Lambda was first and everyone uses it, but that doesn't mean it's actually good. After 5 years of dealing with Lambda's random bullshit, here's what actually drives engineers to switch platforms.
The Cold Start Casino
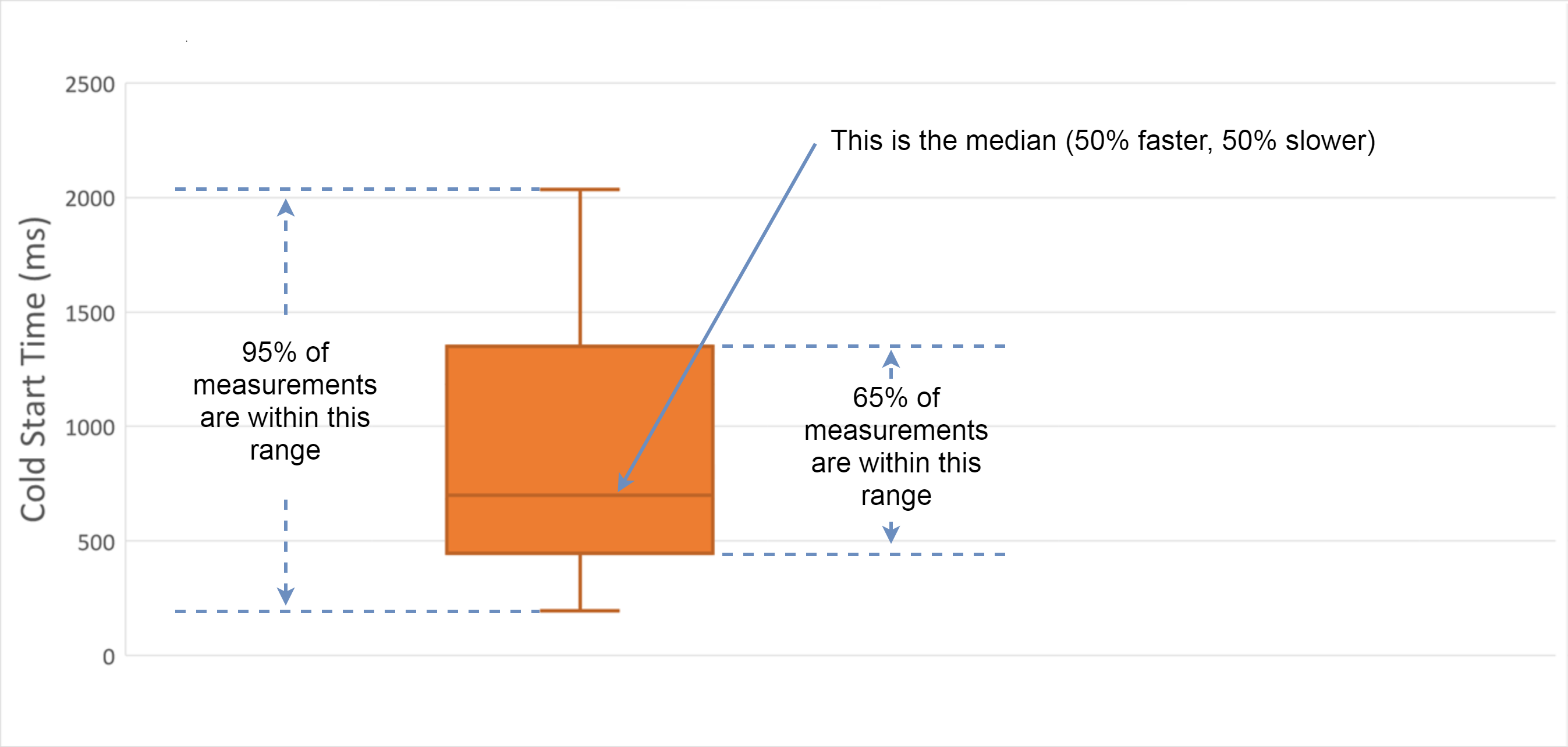
Cold starts aren't just slow - they're completely unpredictable. I've watched the same function take 180ms one request and 2.3 seconds the next, with absolutely zero change in code or traffic patterns. Java functions are worse - expect 3-8 seconds regularly.
The real killer? You can't reproduce it locally. Everything works fine on your machine, then production randomly shits itself during traffic spikes.
Specific error you'll see: `Task timed out after 29.00 seconds` - even for functions that normally run in under 200ms. AWS's own documentation admits cold starts are "highly variable".
AWS Vendor Lock-in Hell
Here's what they don't tell you about Lambda: once you start using DynamoDB triggers, SQS events, and API Gateway, you're fucked. Every service integrates with 3-4 other AWS services, and moving to another cloud means rewriting literally everything.
I spent 4 months trying to migrate a "simple" Lambda function to Google Cloud Functions. The function was 50 lines of code. The AWS service dependencies took 6 weeks to untangle.
The 15-Minute Wall of Pain
Lambda hard-kills your function at 15 minutes. No graceful shutdown, no chance to save state, just dead. This is fine for API endpoints but completely useless for:
- Data migrations (always take longer than expected)
- ML model training (laughably short timeout)
- Large file processing (S3 downloads alone can eat 5+ minutes)
You end up with complex Step Function orchestrations or giving up and using EC2 instances.
CloudWatch Logging is Garbage for Debugging
CloudWatch logs are like trying to debug through a straw. Want to search across multiple function invocations? Good luck. Need to correlate errors across services? Hope you like manually matching timestamps.
Real error message you'll see: `RequestId: abc123 END RequestId: abc123 REPORT RequestId: abc123` with zero context about what actually broke.
Why Alternatives Actually Work Better
Other platforms fix the specific stuff that makes Lambda annoying:
![]()
Cloudflare Workers: V8 isolates start in under 5ms. No cold starts, period. Your API responds consistently every single time instead of playing Lambda's cold start roulette.
![]()
Azure Functions: Durable Functions let you build actual workflows instead of hacky Step Function JSON hell. I've built complex approval processes that would take weeks to code in Lambda.
![]()
Google Cloud Functions: HTTP triggers work like normal web servers. No weird API Gateway proxy integration bullshit.
Kubernetes platforms: You control the infrastructure. When something breaks at 3am, you can actually debug it.
The next sections show which alternative solves your specific Lambda pain points, with real performance numbers from production deployments (not marketing benchmarks).
Bottom line: Every serverless platform sucks in different ways. The trick is finding one that sucks less for your particular use case. Here's the honest breakdown of what each platform is actually like when your production system depends on it.