What Exactly Is a Cold Start?
Here's what happens when Lambda decides to ruin your day: your function has been sitting idle, so AWS killed the execution environment to save money. Fair enough. But when a request comes in, Lambda has to spin up a brand new container from scratch, and that takes forever.
I've seen Java functions take 8+ seconds on cold start while users sit there refreshing the page thinking the API is down. Node.js is usually better, but try explaining to a user why clicking the same button sometimes takes 10x longer than other times.
The Four Phases of Pain
Here's what Lambda is actually doing while your users wait:
1. Container Provisioning
Lambda spins up a new container and allocates CPU/memory. Here's something AWS doesn't advertise loudly: more memory = more CPU = faster cold starts, even if your function barely uses 100MB. I've seen 128MB functions take forever while the same code with 1GB memory starts in seconds.
2. Runtime Startup
This is where different languages show their true colors:
- Python/Node.js: Usually a few hundred milliseconds - not terrible
- Go: Fastest at around 100-200ms - compiled languages win again
- Java: 2-10+ seconds - JVM startup is a nightmare
- C#/.NET: 1-3 seconds - better than Java, still painful
3. Code Download
Lambda downloads your deployment package. Keep ZIP files small or you'll wait forever for S3 transfers. Container images can be up to 10GB but good luck explaining why your "serverless" function takes 30 seconds to start.
4. Dependency Hell
This is where most functions die a slow death. Every import statement, every database connection, every SDK initialization adds seconds. I've debugged functions where import pandas alone took 4 seconds during cold start.
When Cold Starts Will Ruin Your Day
AWS claims cold starts only affect 1% of requests in "steady-state" applications. That's marketing bullshit. Here's when they'll actually bite you:
You're Fucked If:
- Your API gets sporadic traffic (most APIs outside FAANG)
- Users actually sleep at night (weird, I know)
- You dare to deploy during business hours
- Black Friday happens and Lambda can't scale fast enough
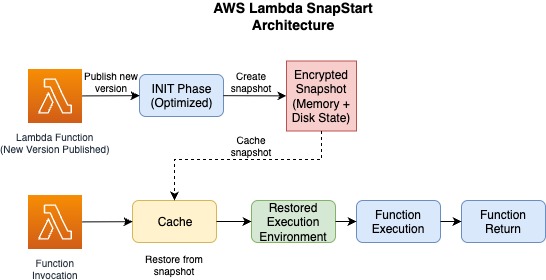
- You're running anything in Java without SnapStart
You Might Survive If:
- Your function gets hit every 15 minutes (the magic timeout where Lambda keeps environments warm)
- You're willing to pay for Provisioned Concurrency (spoiler: it's expensive)
- You enabled SnapStart and it actually works with your code (good luck)
What Actually Happens in Production
Here's what I've seen in real applications, not AWS marketing materials:
Java without SnapStart is just unusable - think 6-12 seconds for Spring Boot functions. I've literally watched users click refresh because they thought the API was broken. With SnapStart enabled, you can get it down to around 800ms, which is actually tolerable.
Python is usually around 400-800ms depending on what shit you're importing. Had one ML function hit 3+ seconds because someone imported scikit-learn at the module level. Moved the import inside the handler function and got it down to under a second.
Node.js is decent, usually around 300-600ms. Express.js apps tend to be on the slower side, but it's manageable.
Go is the fastest at around 150ms most of the time. If you don't mind writing more verbose code, it's your best bet for consistently fast cold starts.
C# sits in the middle at 1-3 seconds. Entity Framework will absolutely murder your cold start times if you're not careful.
Production Horror Stories (The Hidden Costs)
Cold starts don't just make individual requests slow - they can take down your entire system:
The Database Connection Death Spiral: Each Lambda execution environment opens its own database connections. During a traffic spike, I've seen 200+ Lambda functions all try to connect to a PostgreSQL instance with a 100-connection limit. The database locked up, Lambda functions started timing out, and we had to restart everything. Fun way to spend a Tuesday morning.
The Timeout Cascade From Hell: Cold starts cause requests to timeout (30s is a long time for users). Frontend retries the request. More cold starts. More timeouts. More retries. We basically DDoSed ourselves until someone pulled the Lambda kill switch.
The Monitoring Nightmare: Good luck debugging "why is the API sometimes slow?" when 90% of requests are fast but 10% take 5x longer due to cold starts. Your error rates look fine, but user experience is garbage.
Language-Specific Pain Points
Java: The Startup From Hell
Java Lambda functions are basically unusable without SnapStart. I've seen Spring Boot functions take 12+ seconds on cold start - that's not a function timeout, that's a user walking away timeout.
What Actually Works:
- SnapStart saves your ass if your code is compatible (spoiler: mine wasn't)
- GraalVM Native Image compiles to binaries but good luck getting it working with reflection
- The "just throw more memory at it" approach - 1GB+ memory helps but costs a fortune
Python: Import Statement Roulette
Every import statement is a roll of the dice. import pandas alone can add 2-4 seconds to cold start. import torch and you might as well go get coffee.
Tricks That Actually Work:
- Import heavy shit inside your handler function, not at the top of the file
- Lambda Layers help but the 250MB limit is a cruel joke for ML libraries
- Use
pip-toolsto find which dependencies are murdering your cold start times
Node.js: Not As Fast As They Claim
Node.js marketing says "fast startup!" but Express.js apps still hit 600ms+ consistently. Large node_modules directories are the devil.
Reality Check:
- Tree shaking with webpack helps but adds deployment complexity
- Async initialization sounds great until you realize cold start blocking is sync
- Connection pooling doesn't help when the pool starts empty
The State Management Disaster
Everything stateful gets wiped when Lambda decides to kill your execution environment:
Database Connections Are Expensive: Every cold start means opening new database connections. I learned this the hard way when our PostgreSQL instance hit connection limits during a Black Friday sale. RDS Proxy helps but it's another moving part that can break.
Auth Tokens Vanish: Your carefully cached JWT tokens? Gone. OAuth tokens? Poof. Every cold start means re-authenticating, which adds another 200-500ms to an already slow request.
In-Memory Cache Is a Lie: Anything you cached in memory gets nuked on cold start. Redis becomes your best friend, but now you're paying for another service to work around Lambda's stateless bullshit.
How to Tell If Cold Starts Are Killing You
The Magic Log Line:
REPORT RequestId: abc123 Duration: 5234.67 ms Init Duration: 4567.89 ms
See that Init Duration? That only appears during cold starts. If you're seeing this on 10%+ of requests, you have a problem.
CloudWatch Won't Save You:
INIT Durationmetric exists but only shows during cold starts (helpful!)Durationincludes cold start time, making it useless for performance analysisConcurrent Executionsspikes right before cold start hell begins
The Real Debug Process:
- First thing I check: is it actually a cold start or just broken code?
- Look for
Init Durationin logs - if missing, it's not cold start related - Nuclear option: restart everything and pretend it never happened
- When all else fails, throw more memory at it until the problem goes away
OK, enough complaining about cold starts. What you really need are solutions that work in production. The optimization techniques in the next section can dramatically reduce your Lambda cold start times - I think we got Java down by something like 80-90% with SnapStart and proper memory tuning. Anyway, here's what actually works instead of random blog post advice.