![]()
Kubernetes networking fails in predictable ways. I've been debugging this shit since Kubernetes 1.11, back when nobody knew what a CNI was and we all just hoped Flannel wouldn't randomly die. Here's what actually breaks and how to fix it without losing your mind.
CNI Plugin Failures

The CNI plugin handles all pod networking. When it breaks, you get these fun symptoms:
- Nodes stuck in
NotReadywith "CNI plugin not initialized" - Pods stuck in
Pendingforever - Random connectivity drops that make you question reality
failed to create pod sandboxerrors in kubelet logs
What's actually wrong:
CIDR conflicts - Your pod network overlaps with node or service networks. I've seen this kill entire clusters during weekend deployments.
## See what networks you're using
kubectl cluster-info dump | grep cidr
kubectl get nodes -o jsonpath='{.items[*].spec.podCIDR}'
Version mismatches - Your CNI plugin doesn't support your Kubernetes version. Kubernetes 1.25 changed the default CNI timeout from 10s to 30s, which masks real connection issues. Don't use Flannel 0.15.1 - it corrupts routing tables on node restart. Calico 3.20+ requires Kubernetes 1.19+ but the error messages just say "plugin failed" without mentioning version conflicts.
IP exhaustion - Someone configured a /28 subnet for 100 pods. Math doesn't work.
## Check what IPs you have left
kubectl describe node NODE_NAME | grep PodCIDR
## For Calico users
calicoctl get ippool -o wide
The fix? Expand your CIDR or reduce your pod density. I learned this the hard way during Black Friday 2021 when AWS was having one of their "everything is fine" us-east-1 outages and we were frantically trying to failover to us-west-2, only to discover our pod CIDR was a /24 and we needed to scale to 500 pods. Took down checkout for 3 hours.
DNS Resolution Failures

CoreDNS is supposed to handle DNS but breaks constantly:
- Service resolution works sporadically (like 70% of the time)
nslookup kubernetes.defaultreturnsSERVFAIL- Apps can't find services that definitely exist
- DNS works from some pods but not others
What's actually wrong:
CoreDNS resource starvation - Default resource limits are garbage. 100m CPU isn't enough for any real load. Resource limits that look reasonable will throttle DNS under load.
## Check if CoreDNS is being throttled
kubectl top pods -n kube-system | grep coredns
kubectl describe deployment coredns -n kube-system | grep resources
Quick fix: Bump CoreDNS resources to 500m CPU and 512Mi memory. The default limits are a joke - whoever thought 100m CPU would handle a production cluster was clearly not running real workloads.
DNS config inconsistency - Different nodes have different DNS settings after upgrades. Kubelet configurations get out of sync.
## Check if DNS configs match across nodes
kubectl get pods -n kube-system -l k8s-app=kube-dns -o wide
kubectl describe configmap coredns -n kube-system
Network policies breaking DNS - Someone applied network policies without understanding they need to allow DNS traffic. Pods can ping by IP but can't resolve names.
Service Routing Issues
Kubernetes Services are load balancers that route traffic to pods. They break constantly.
You'll see:
kubectl get svcshows endpoints exist- Direct pod access works:
curl pod-ip:8080 - Service access fails:
curl service-name:8080 - Load balancer says "no healthy targets"
What's broken:
Endpoint lag - The endpoint controller is slow updating when pods start/stop. Your service sends traffic to dead pods.
## Check if endpoints match reality
kubectl get endpoints your-service -o yaml
kubectl get pods -l app=your-app -o wide
Mixed kube-proxy modes - Some nodes use iptables, others use ipvs. kube-proxy configuration is inconsistent after upgrades.
External Access Problems
Ingress controllers handle external traffic. They fail in spectacular ways:
- Ingress never gets an external IP
- 502 errors for services that work internally
- SSL cert issues causing browser warnings
- Traffic routes to wrong backends
Common failures:
Cloud LB integration broken - AWS ALB can't create load balancers due to IAM issues. GCP quota limits hit.
## Check ingress status
kubectl get ingress -A
kubectl describe ingress your-ingress
kubectl logs -n ingress-nginx deployment/ingress-nginx-controller
Cert-manager failures - cert-manager can't renew certs because DNS challenges fail or HTTP challenges are blocked.
Network Policy Hell
Network policies break legitimate traffic more than they block attacks. Default deny-all policies applied without understanding what needs to communicate.
## See what policies are blocking you
kubectl get networkpolicies -A
kubectl get namespaces --show-labels
The Debug Process That Actually Works
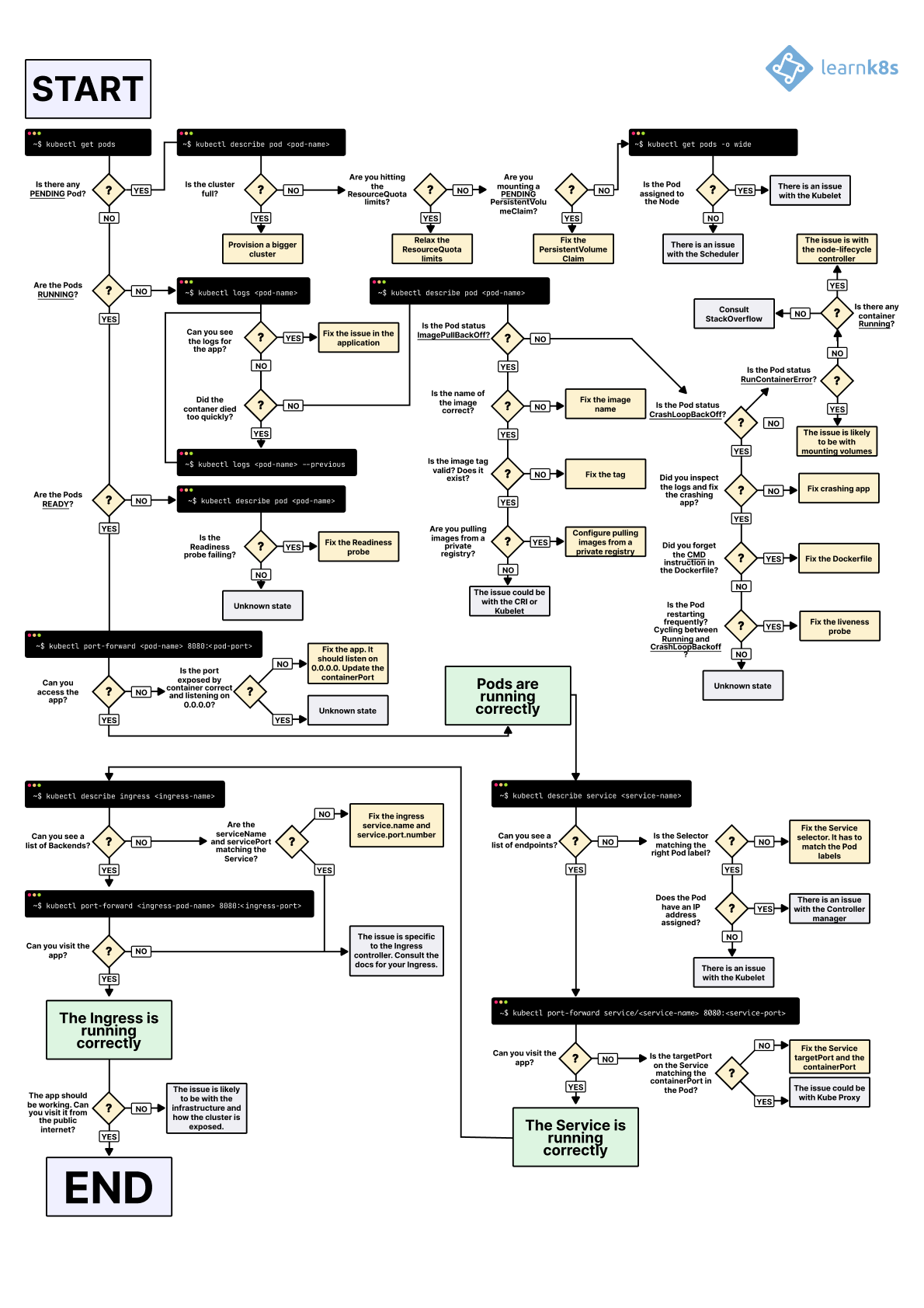
When everything's broken, use this order:
- Check CNI status
kubectl get nodes -o wide
kubectl describe nodes | grep Ready
- Test basic connectivity
kubectl run test --image=busybox --rm -it -- ping 8.8.8.8
- Verify DNS
kubectl exec test -- nslookup kubernetes.default
- Test service routing
kubectl exec test -- curl service-name:8080
- Check external access
kubectl exec test -- curl your-domain.com
Start here and work through systematically. Most networking issues are CNI problems, DNS throttling, or network policies blocking legitimate traffic.


