Velero is the backup tool you install after experiencing your first major Kubernetes disaster. Originally called Heptio Ark, it's now maintained by VMware Tanzu and has graduated from the CNCF, which means it's stable enough that you won't get fired for using it.
v1.17.0 dropped in 2025 with Windows support and micro-service architecture for fs-backup. The big deal is they fixed the memory hogging issues - node-agent pods used to request massive memory and hold it forever. Now they actually release it when done backing up your stuff.
Companies like Netflix, MongoDB, and Reddit run this in production, which tells you it's battle-tested enough for your workloads.
The Three Parts That Actually Matter
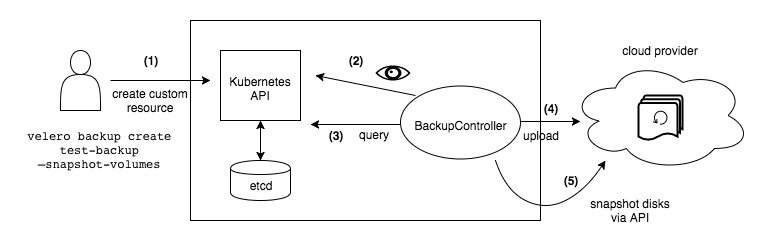
Velero has three components that you'll spend way too much time debugging:
Velero Server: The controller that lives in your cluster and watches for backup CRDs. When it works, it talks to the K8s API and your storage backend. When it doesn't work, you'll spend hours checking RBAC permissions and IAM policies. The server handles backup schedules but won't tell you when they fail unless you set up monitoring.
Velero CLI: Your interface for everything. velero backup create, velero schedule create, velero restore create - sounds simple until you realize half the commands fail silently. The CLI has validation but it's optimistic. Always check velero backup describe after creating anything because "Completed" doesn't mean what you think it means.
Node Agent: DaemonSet that does the heavy lifting for persistent volume backups when CSI snapshots aren't available. Since v1.14 it uses Kopia instead of Restic, which fixed the memory leaks but introduced new failure modes. Pro tip: these pods will randomly restart and leave your backups stuck in "InProgress" status.
When You Actually Need This Thing
Velero solves three problems that will ruin your day:
Disaster Recovery: When someone accidentally deletes prod or your cloud provider has an outage. Netflix uses this because they learned the hard way that shit happens. Recovery time is anywhere from 10 minutes if you're lucky to 6 hours if your persistent volumes are massive. Don't ask me how I know.
Cluster Migration: Moving workloads between clusters without wanting to rebuild everything from scratch. The official migration docs make it sound easy, but you'll spend days fixing storage classes, ingress annotations, and whatever custom resource definitions broke between environments. Test this multiple times before doing it in prod.
Environment Replication: Copying prod to staging so developers can debug with real data instead of made-up test fixtures. Works great until you restore production secrets to staging and suddenly your test environment is sending real emails to customers. Always sanitize before restoring.
Storage Options (And Where They'll Bite You)
Velero supports multiple storage backends, each with its own special way of frustrating you:
AWS S3: The AWS plugin works great once you survive the IAM permission hell. You'll need about 47 different permissions, and the documentation lies about half of them. GitHub issue #8240 from September 2024 shows the plugin still fucks up IRSA roles. Budget 2 days for getting the permissions right, then another day when it breaks after an AWS update.
Google Cloud Storage: The GCP plugin is honestly the least painful to set up. Workload Identity is cleaner than dealing with service account keys, and Google's IAM model actually makes sense. Still fails sometimes but at least the error messages are readable.
Azure Blob Storage: The Azure plugin works with managed disks and blob storage. Managed identity is nice when it works, but Azure's authentication model is a maze. Expect to spend time figuring out which identity goes where.
CSI Volume Snapshots: Uses your CSI driver to take volume snapshots instead of copying files. Fast and efficient when it works, but many CSI drivers have bugs. AWS EBS snapshots are reliable, others are hit-or-miss. Always test restoring from snapshots - taking them is the easy part.
![]()
S3-Compatible Storage: MinIO and Ceph work for on-premises setups. MinIO is solid, Ceph will make you question your life choices. Good for air-gapped environments where cloud storage isn't an option.