I've watched Fortune 500 companies spend years and millions trying to roll out "collaborative notebooks" because some consultant told them it's just like deploying email servers. It's not. The difference between team collaboration (50 users) and enterprise deployment (500+ users) is like the difference between cooking dinner for your family and running a fucking restaurant during Black Friday.
Here's the thing everyone gets wrong: you can't just take basic JupyterHub and "make it bigger." The Zero to JupyterHub guide gets you to hello world, but enterprise means throwing out 80% of what you learned and starting over with the mindset that everything will break.
Shit that breaks when you scale:
Authentication becomes a nightmare. Your IT department demands SSO integration with Active Directory, multi-factor authentication, and compliance logging for everything. That jupyter lab --collaborative setup you loved? Dead the moment legal wants audit trails for every notebook execution. I've spent weeks debugging LDAP Authenticator configs that should work but don't because enterprise AD is a special kind of hell.
Resource management turns into warfare. With 5 users, memory limits are suggestions. With 500 users, that one data scientist running TensorFlow on CPU will bankrupt your AWS bill and crash everyone else's kernels. I've debugged production deployments where 80% of compute sat idle while users couldn't start notebooks because one data scientist was running a 64GB pandas operation "real quick" and crashed the whole node. Kubernetes resource limits become your religion, and JupyterHub spawner tuning is some dark art that requires 3 weeks of trial and error plus sacrificing a goat.
Security becomes your full-time job. Team deployments trust everyone with everything. Enterprise means network segmentation, data access controls, secrets management, and the kind of paranoia that keeps CISOs awake at night. Every notebook execution is a potential data exfiltration vector, and you'll spend more time thinking about security than data science.
Three Ways This Goes Sideways
Category 1: Companies with 100-500 Data Scientists
Your data team outgrew basic JupyterHub but you're not Google. You need industrial-strength deployment without the army of DevOps engineers. Budget conscious but willing to pay for functionality that actually works.
What usually fails: Half-measures. Trying to run JupyterHub on a single beefy server "just until we can justify the K8s complexity." Spoiler alert: that server dies spectacularly at 2:47 AM on December 15th when everyone's trying to finish year-end models, taking three months of work with it. I've personally watched this kill two different companies' Q4 revenue forecasts.
Category 2: Financial Services/Healthcare Giants (1000+ Users)
Compliance requirements that would make a lawyer cry. HIPAA, SOX, GDPR, and internal security policies written by people who think USB ports are security vulnerabilities. Every notebook needs to be auditable, reproducible, and locked down tighter than Fort Knox.
What usually fails: Building first, security audit later. You spend 6 months building this beautiful platform, then InfoSec discovers you're running containers as root and can SSH into user sessions. Congratulations, you just violated PCI-DSS, HIPAA, and three internal policies nobody told you about. Time to rebuild everything from scratch while the CFO asks why you wasted half a million dollars.
Category 3: Tech Companies That Should Know Better
Engineering teams who think they can build their own notebook platform because "how hard can it be?" Usually have 5-10 different data science teams with conflicting requirements and the kind of technical debt that makes senior engineers wake up screaming.
What usually fails: "We can build this better internally." Famous last words. They spend 18 months building a custom notebook platform with 12 different microservices, then discover they've reinvented JupyterHub but worse and with more bugs. I've watched three senior engineers quit mid-project when they realized they were recreating problems that were solved in 2018. The remaining team is still fixing authentication edge cases that JupyterHub's LDAP connector handles out of the box.
What You Actually Need to Build

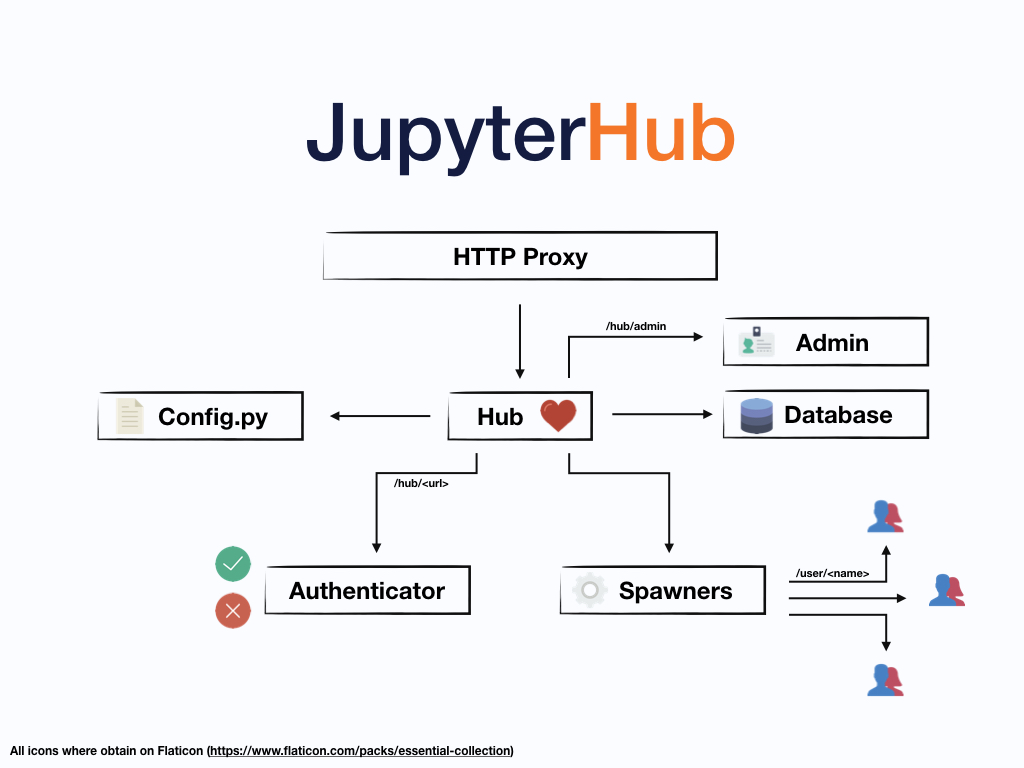
Forget the toy examples in tutorials. Here's what production enterprise JupyterLab deployment looks like. The Jupyter Enterprise Gateway architecture provides the enterprise-grade foundation, while BinderHub patterns offer scalable notebook spawning mechanisms.
Layer 1: Load Balancer + SSL Termination
No more self-signed certificates or Let's Encrypt certs that expire at 5 PM on Friday when you're already at your kid's soccer game. Enterprise-grade SSL certificates, proper DNS configuration, and load balancing that doesn't fall over when the entire data science team discovers they can run distributed training on GPUs and suddenly you have 200 connections instead of 20.
HAProxy configuration examples or AWS ALB integration patterns in front, handling SSL termination and routing traffic to multiple JupyterHub instances. Because when your CEO wants to see the quarterly analysis and the server is down, updating your resume won't help. The JupyterHub proxy configuration requires careful tuning for enterprise load patterns.
Layer 2: JupyterHub Federation
Multiple JupyterHub instances behind the load balancer, not because you love complexity but because single points of failure are career-limiting events. Session affinity configured correctly or users randomly lose their work mid-analysis.
Layer 3: Kubernetes Container Orchestration
Not because it's trendy, but because manually managing 500 user containers across 50 nodes is the kind of problem that turns senior engineers into alcoholics. Kubernetes provides:
- Pod scheduling and resource limits that actually work
- Node failure handling (servers die, usually at the worst possible moment)
- Rolling updates without downtime (because "maintenance windows" is not a phrase data scientists understand)
Layer 4: Shared Storage That Doesn't Suck
Network storage that won't shit the bed when 200 data scientists simultaneously try to load the quarterly sales dataset at 9 AM Monday morning. This isn't your MacBook's NVMe SSD anymore - you need distributed file systems that can handle 200 concurrent pd.read_csv() calls without everyone's notebooks timing out.
Options that don't suck: AWS EFS with provisioned throughput, Azure Files Premium, or self-managed Lustre if you have storage engineers who know what they're doing. Kubernetes persistent volume patterns require careful configuration for data science workload patterns.
Layer 5: Enterprise Integration Hell
LDAP authentication (because IT won't let you use Google OAuth), audit logging that satisfies compliance officers, and network policies that let legitimate traffic through while blocking the creative ways users try to circumvent security.
The OAuth Authenticator collection provides enterprise SSO options, but LDAP configuration debugging consumes weeks. Audit logging patterns must satisfy compliance frameworks while network security policies balance access with isolation.
This is the layer that murdered my last two deployments. LDAP authentication will consume 3x longer than you budgeted, OAuth will break in ways that make you question your career choices, and SSO integration will teach you the true meaning of despair. Every. Fucking. Time.
The Numbers That Matter (And The Ones That Don't)
Resource Planning That Reflects Reality:
- 500 users don't use the system simultaneously. Plan for 20-30% concurrent usage during peak hours, 50% during model training season (November-January for most companies).
- Memory: 8-16GB per active user, 32GB for anyone running PyTorch because it's a memory-hungry beast. The data scientists who claim they only need 4GB are lying through their teeth - they'll be back asking for more RAM within a week.
- CPU: 2-4 cores per active user. ML training hammers CPU despite what NVIDIA's marketing department wants you to believe.
- Storage: 100GB per user minimum, 1TB if they're doing anything with images/video. Data scientists are worse than digital hoarders - they download the same dataset 17 times "just to be safe."
What Kills Enterprise Budgets:
- Underestimating network bandwidth. When 200 people simultaneously pull the same 10GB dataset, your network becomes the bottleneck.
- Ignoring GPU costs. One data scientist requesting "just a small GPU instance" can cost more per month than the entire team's CPU budget.
- Not planning for growth. Your 100-user deployment will become 300 users within 18 months because success breeds demand.
Cost Reality Check:
- Small enterprise (100-200 users): $15K-$50K/month in cloud costs, plus 1-2 FTEs who hate their lives
- Mid-size (200-500 users): $50K to oh-shit-that's-expensive/month plus dedicated DevOps team who drink heavily
- Large enterprise (500+ users): $150K+/month plus specialized infrastructure team and a therapist
These numbers are from actual deployments I've survived. Multiply by 5x when your data scientists discover p4d.24xlarge instances exist and decide their random forest "needs" 8 A100 GPUs for "testing."
The Security Model That Passes Enterprise Audits
Enterprise security isn't "enable HTTPS and pray." It's defense in depth with enough complexity to make security consultants buy vacation homes.
Network Segmentation:
Users shouldn't be able to SSH into production databases from notebook containers. Network policies that isolate user workloads from sensitive systems while still allowing legitimate data access. Calico network policies and Istio service mesh provide enterprise-grade microsegmentation.
Secrets Management:
No hardcoded credentials in notebooks. Integration with enterprise secret managers (AWS Secrets Manager, HashiCorp Vault, Azure Key Vault) so users can access databases without seeing passwords. Kubernetes secrets integration requires proper RBAC configuration.
Audit Logging:
Every notebook execution, every file access, every login attempt logged in formats that compliance teams can actually use. Not just access logs - you need semantic logging that answers "who ran what analysis on which dataset." Prometheus metrics and Grafana dashboards provide operational visibility, while SIEM integration handles compliance requirements.
Data Loss Prevention:
Preventing users from accidentally (or intentionally) downloading customer data to their laptops. This means sandboxed execution environments and carefully controlled data egress policies. Cloud Security Alliance guidelines and GDPR compliance patterns shape these requirements.
The Monitoring You Actually Need
Traditional server monitoring (CPU, memory, disk) won't save you when your enterprise deployment goes sideways. You need monitoring that understands the data science workflow. The Prometheus monitoring stack integrates with JupyterHub metrics while Kubernetes monitoring patterns provide infrastructure visibility:
User Experience Monitoring:
- Time from "start notebook" to "cell execution" (should be under 30 seconds)
- Kernel spawn success rate (should be >95%)
- Notebook load times for different file sizes
- Resource starvation detection (users waiting for compute resources)
Business Impact Monitoring:
- Analysis completion rates (how many projects actually finish)
- Model deployment pipeline health (if integrated with MLOps)
- Cost per analysis (tracking resource consumption per business outcome)
Infrastructure Health:
- Database connection pool exhaustion (JupyterHub's database gets hammered)
- Shared storage performance (IOPS and bandwidth utilization)
- Container image pull times (affects startup latency)
- Authentication system latency (LDAP/SSO response times)
The goal isn't perfect uptime - it's predictable performance and fixing shit before users start screaming. Data scientists can tolerate scheduled maintenance but not mysterious 5-minute notebook load times that make their jobs impossible.
Migration Strategy That Won't Destroy Your Team
Moving 500 data scientists from their existing workflow to enterprise JupyterLab is change management from hell. Here's how to avoid the worst pitfalls:
Phase 1: Parallel Deployment (Months 1-3)
Run both systems simultaneously. Let early adopters migrate voluntarily while maintaining the old system. You'll discover integration issues and user workflow problems without affecting business-critical analysis.
Phase 2: Business Unit Migration (Months 3-6)
Migrate teams by business unit, not by individual preference. Teams that work together should move together. Provide migration assistance - most data scientists have years of accumulated notebooks and data files.
Phase 3: Forced Migration (Months 6-12)
Set a hard fucking deadline and stick to it. The last 20% of users will find 47 different reasons why the new system doesn't work for their "special" requirements. Plan for screaming, threats to quit, escalations to your boss, and panicked calls from VPs who suddenly care deeply about notebook deployment strategy.
What Actually Helps:
- Training sessions focused on workflow, not features
- Migration tools that automatically transfer notebooks and environments
- Champions in each team who can help with the transition
- Clear documentation for common tasks (most people won't read it, but having it helps the ones who do)
Enterprise JupyterLab deployment isn't a technical problem - it's convincing 500 stubborn data scientists to change their sacred workflows, which makes debugging LDAP authentication look like fucking kindergarten.