The classic Jupyter Notebook was fine until you needed more than one file open. That single-document interface became painful fast when you're bouncing between datasets, comparing models, or just trying to keep your exploratory work organized.
JupyterLab fixes that fundamental limitation. It's what Project Jupyter built when they realized people needed an actual IDE, not just a fancy web REPL.

What You Get That Notebook Doesn't Have
Multiple Documents: Open notebooks side-by-side, compare outputs, drag cells between files. No more tab hell in your browser. The JupyterLab documentation explains the interface layout.
File Management: Built-in file browser that doesn't suck. Upload files, rename stuff, see your directory structure without leaving the interface.
Terminal Access: Real terminal, not some gimped web version. SSH into servers, run git commands, install packages when pip breaks (again).
Language Support: Python dominates, but JupyterLab runs 40+ other kernels. R for statistics via IRKernel, Julia for performance with IJulia, SQL for databases using SQL magic, Scala when Java isn't painful enough through Almond.
Extensions That Work: The extension ecosystem actually functions. Git integration via jupyterlab-git, code formatters like Black, database connections through SQL tools, variable inspectors with lsp extension - stuff that makes you productive instead of frustrated.

Memory Management Reality Check
JupyterLab will eat every byte of RAM you have and ask for more. The web-based architecture means you're running a browser inside a browser, and that shit gets heavy fast with large datasets.
You'll learn to restart kernels religiously. Large matplotlib outputs will slow everything to a crawl. Working with datasets bigger than your available memory? Prepare for kernel death and the joy of losing your work.
Real Deployment Scenarios
Local Development: Install with pip install jupyterlab, run jupyter lab, pray your ports aren't blocked. Works great until you need HTTPS or want other people to access it. The official installation guide covers different methods, and this troubleshooting guide helps when things break.
Cloud Platforms: Google Colab gives you free JupyterLab until your data gets too big. AWS SageMaker has it but costs real money. Azure ML exists if you're already trapped in Microsoft land.
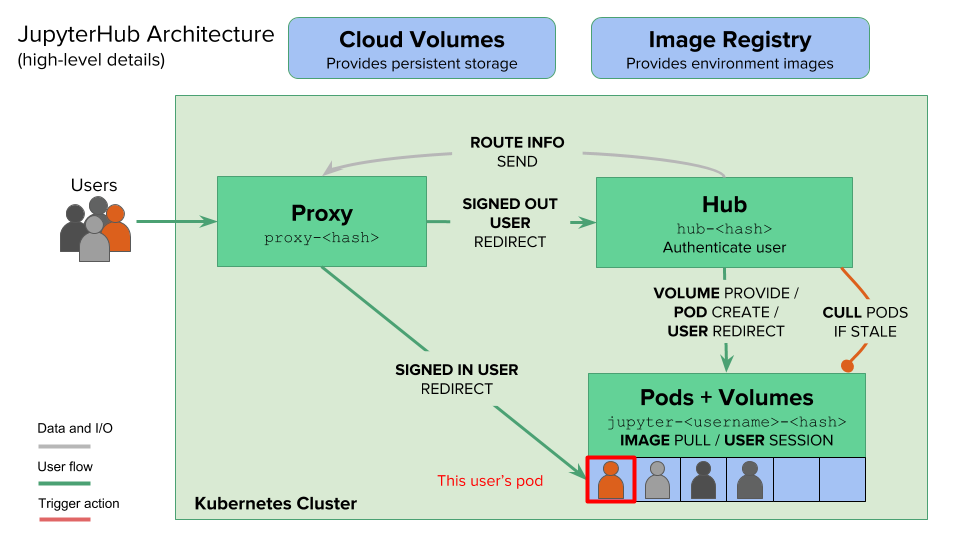
Self-Hosted Pain: Running JupyterLab on a server starts simple until you need authentication, SSL certificates, and resource limits. That's when you discover JupyterHub and question your life choices. The deployment guide walks through setup, Docker configurations provide pre-built environments, and Kubernetes deployment helps with scaling.
Who Actually Uses This
According to Stack Overflow's 2024 survey, 12.8% of developers admit to using JupyterLab (the rest are still stuck with Notebook or pretending VS Code notebooks work). That's data scientists debugging models at 2am, researchers trying to reproduce experiments that worked yesterday, students learning Python and constantly crashing kernels, and engineers who need more than VS Code but less than PyCharm.
The ecosystem continues to grow: JupyterCon 2024 highlighted adoption across finance, healthcare, and academia, with organizations like Netflix using notebooks for experimentation and Bloomberg deploying JupyterHub for thousands of analysts.
The real test: can you debug a pandas memory error at 3am? JupyterLab won't prevent the error, but at least you can see where everything went wrong.