I've seen a senior data scientist spend three days trying to reproduce a colleague's "simple" analysis from last month. The notebook crashed on import because of version mismatches. The data path was hardcoded to Sarah's laptop. Half the cells referenced datasets that lived in someone's Google Drive. The fucking thing was a disaster.
This isn't unique - research shows that 90% of computational notebooks aren't reproducible after 6 months, even by their original authors.
This exact nightmare plays out at 90% of data science teams. Everyone works alone because the "collaboration tools" are either nonexistent or such complete shit that emailing .ipynb files around actually feels reasonable by comparison. I've watched teams waste entire months rebuilding analysis that already existed somewhere on Sarah's laptop.
What Actually Works (After Trying Everything Else)
Real-time collaborative editing sounds like magic until you try it. JupyterLab 4.4+ finally made this not suck - you can see other people's cursors, changes sync instantly, and you don't get those "file modified externally" death dialogs. The jupyter-collaboration extension works, but it took three major versions to get there.
Shared computing environments solve the "works on my machine" nightmare. I've spent entire days debugging version mismatches between team members. JupyterHub gives everyone identical environments, but the setup will make you question your life choices.
Version control that doesn't hate notebooks - this was the biggest pain point for years. Raw notebook JSON diffs are unreadable garbage. nbdime makes Git usable with notebooks, and the jupyterlab-git extension lets you commit without leaving the interface. The ReviewNB service adds proper code review for notebooks, which GitHub still can't do properly.
JupyterLab Collaboration in 2025: Finally Not Completely Broken
JupyterLab 4.4+ is the first version where collaboration doesn't randomly crash every goddamn hour. Earlier versions were a complete nightmare - the RTC feature was marked "experimental" because it actually was experimental. I've deployed 4.4.6 for three teams now and it's finally solid enough for daily use without wanting to murder someone.
The Real-Time Collaboration (RTC) finally works reliably. No more mysterious sync failures or corrupted notebooks that make you want to throw your laptop out the window.
## This actually works now
pip install jupyter-collaboration
jupyter lab --collaborative
But here's where it gets ugly - it only works smoothly for 3-5 people max. With more users, you slam into WebSocket connection limits and everything becomes laggy as hell. I learned this shit the hard way when a 12-person team tried collaborative editing and it turned into a cursor circus that made everyone seasick. The browser starts choking around 8+ simultaneous connections and performance goes to absolute shit.
The Three Ways Teams Fuck This Up (And How I Fixed Them)
Disaster #1: Shared Network Drives - The File Corruption Special
Some genius in management decided we should put all notebooks on a shared network drive. "It'll be easy!" they said. What actually happened: file locking hell, permission errors every damn day, and notebooks getting corrupted when two people saved simultaneously. I spent a week rebuilding analysis that got trashed by Windows file locking.
The Fix: Git with nbstripout to strip outputs before commits. Painful to set up, but at least notebooks stop dying random deaths. The Git best practices guide helps teams avoid the branch-merging disasters that inevitably follow.
Disaster #2: Email Attachments - AKA Version Hell
"Just email me the latest version" - famous last words. We had seven versions of the same analysis floating around in email threads. Nobody knew which was current. Half the notebooks referenced data files that lived on someone's laptop. Reproducing results was basically impossible.
The Fix: Automated HTML reports with nbconvert. Every analysis gets converted to HTML and posted to a shared location. At least people stop asking "which version is the real one?" Papermill automates notebook execution and parameterization, making reproducible reports actually possible.
Disaster #3: The Cursed Shared Server
"Let's just give everyone SSH access to one server!" - the words of someone who's never seen users kill each other's Python processes. Memory wars, accidentally deleting each other's files, and mysterious crashes when Sarah ran her 50GB dataset processing.
The Fix: JupyterHub with actual user isolation. Each person gets their own container with memory limits. No more process murder sprees.
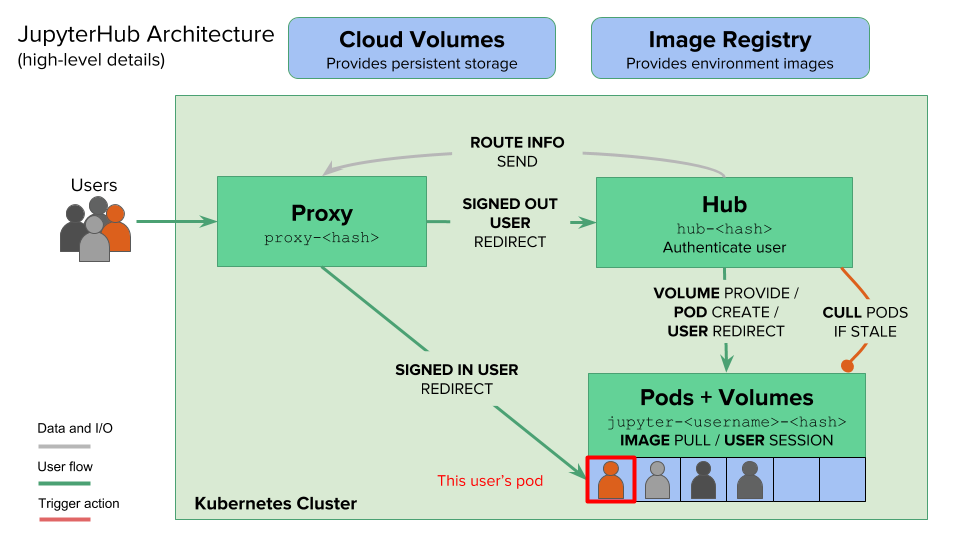
Three Approaches That Actually Work (After You Debug Them for Weeks)
The "Just Make It Work" Approach (Teams of 3-5)
One server, everyone logs in, pray nobody crashes it. Budget 2x what you think because something always breaks.
## This looks simple but will consume your soul
pip install jupyter-collaboration
jupyter lab --collaborative --port=8888 --ip=0.0.0.0
Reality check: Costs $100-400/month once you factor in a decent server, backup storage, and the SSL certificate that will absolutely take three fucking attempts to get working. Someone will accidentally kill the server at least once per month because they ran sudo killall python during troubleshooting. DigitalOcean and Linode are popular choices because they're cheap, but you get what you pay for when everything goes sideways at 3am.
The "Proper" Deployment (Teams of 5-50)
JupyterHub with user isolation. Prepare for configuration hell but at least people stop murdering each other's processes. Budget $300-1500/month and 40+ hours of setup pain.
What they don't tell you: The authentication integration will break twice, the spawner configuration is documented like shit, and you'll spend a weekend debugging why user containers randomly die.
The "Enterprise Nightmare" (50+ Users)
Kubernetes-based JupyterHub. Sounds impressive in meetings, delivers maximum suffering. Budget $1500+/month plus a dedicated DevOps person who hates you.
Zero to JupyterHub with Kubernetes - the documentation is good but you'll still hit three undocumented edge cases that require Stack Overflow detective work.
What Actually Happens in Real Teams
The "Pair Programming" Fantasy vs Reality
In theory: Two data scientists collaborate seamlessly in real-time, one cleaning data while the other visualizes.
In practice: One person types while the other watches their cursor jump around. The collaboration turns into "no, click here... no, THERE" sessions. Works for debugging or code review, but day-to-day analysis is still mostly solo work.
The Security Nightmare Nobody Talks About
Collaboration breaks isolation - when people can edit your notebooks, they can see your API keys, database passwords, and that embarrassing TODO comment about your manager. I've seen teams accidentally commit AWS credentials because collaborative editing made everyone forget about output cells that still showed print(f"Connected to {DB_PASSWORD}") from debugging sessions. One team leaked their prod database password in a Git commit that stayed public for 3 months until AWS started charging them $2000/month for cryptocurrency mining that wasn't theirs. The OWASP guide to securing development environments covers threats that most data teams ignore until they get that billing alert.
The Hidden Costs That Kill Budgets
Your $200/month server becomes $800/month after you add:
- Backup storage (another $50/month)
- Monitoring tools (because you need to know when it breaks)
- SSL certificates that expire and break everything
- 20-30% of someone's time fighting configuration issues
Most teams underestimate admin overhead. Budget for one person spending Friday afternoons fixing whatever broke during the week.
Why Cloud vs On-Premise Is a False Choice
Cloud is expensive but someone else deals with hardware failures at 3am. On-premise is cheaper until your server dies and nobody knows how to rebuild it.
The real choice is between "expensive but reliable" and "cheap but you're on call forever."
So which nightmare do you choose? Here's how to pick your poison.