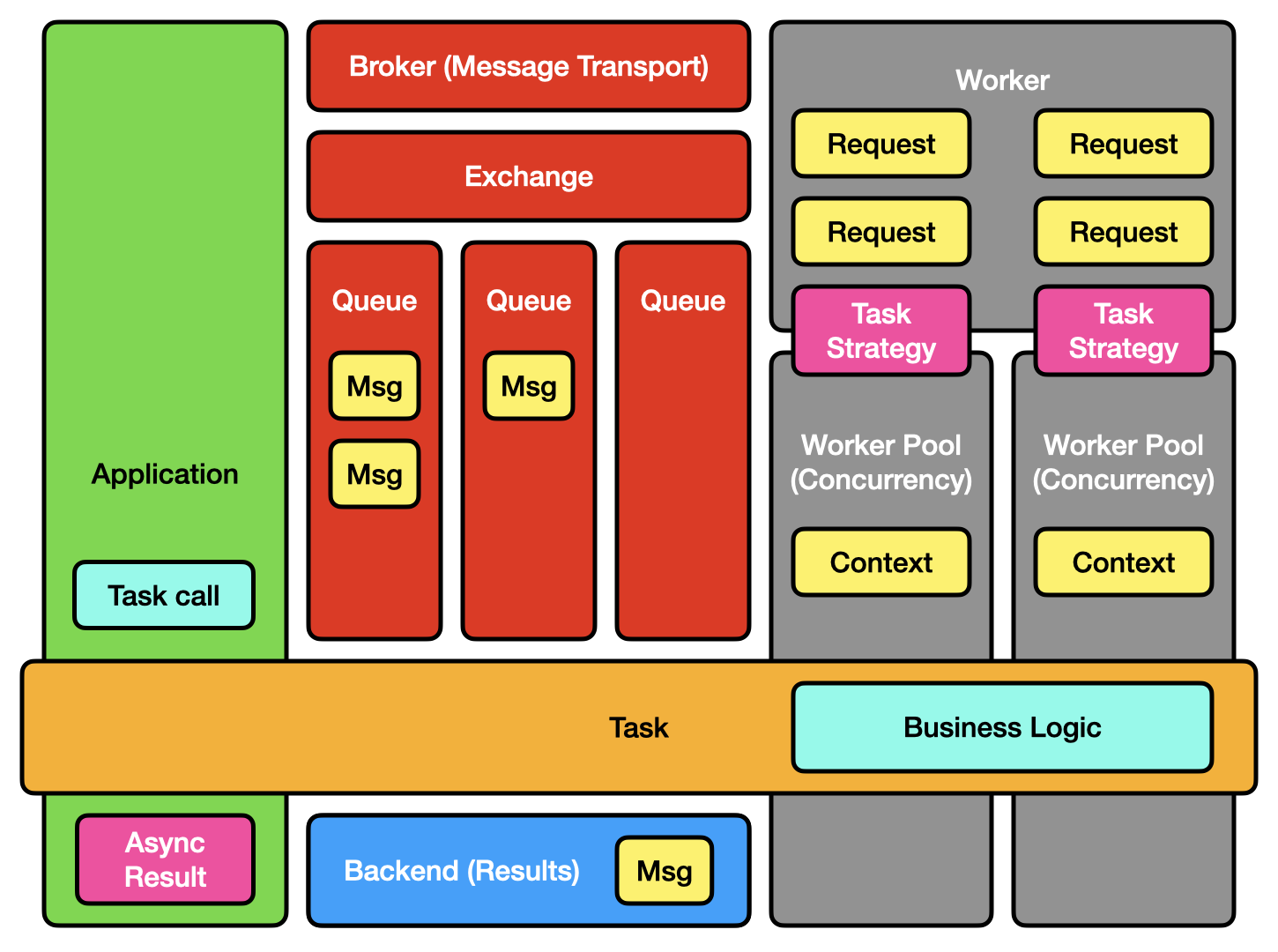
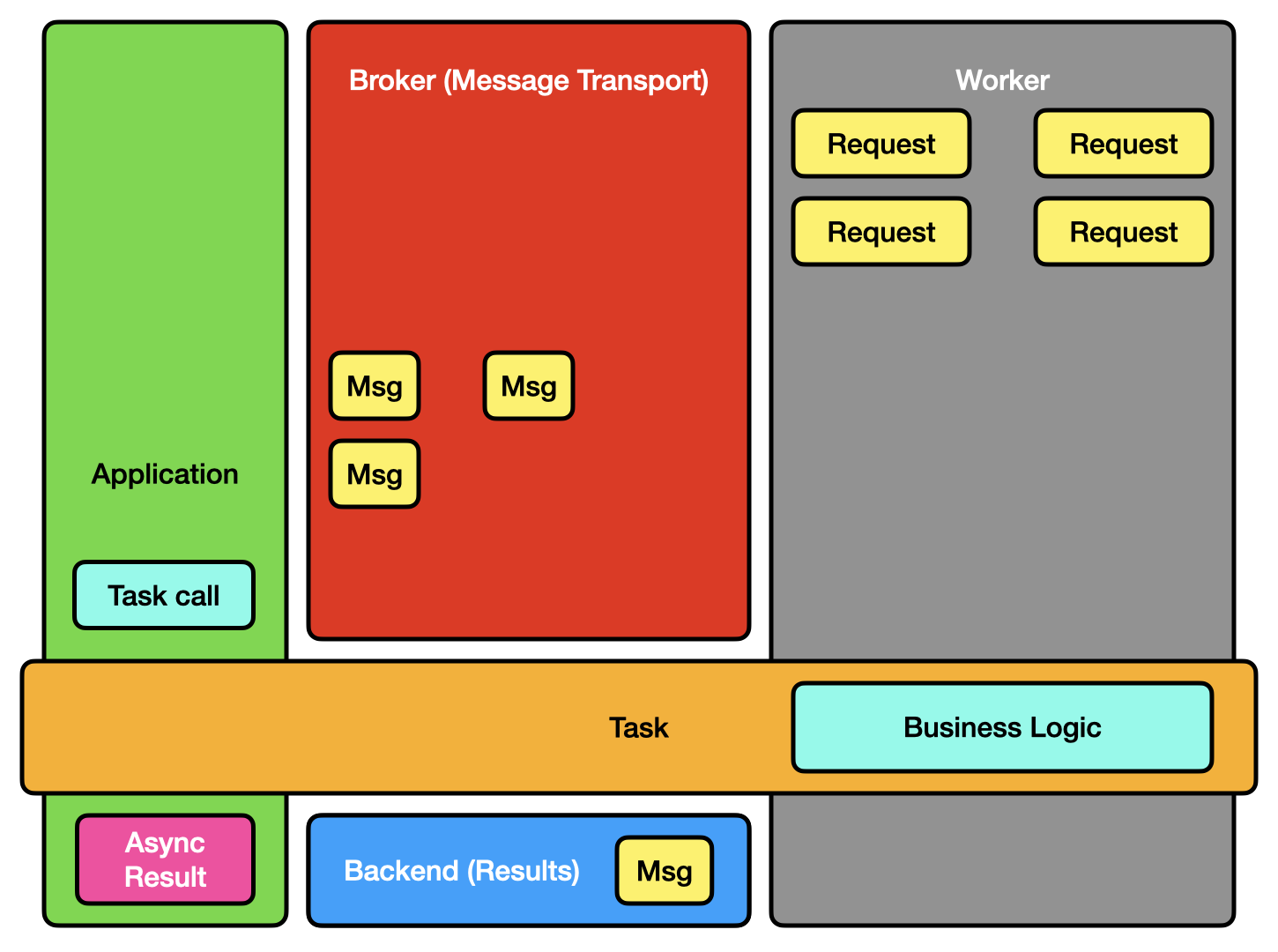
Your Django app is slow because every time someone uploads a file or sends an email, the whole thing freezes while it does the work. That's where Celery comes in - it takes those slow jobs and shoves them into a background queue so your users don't have to sit there watching a spinner for 30 seconds.
The Problem: Everything Is Fucking Slow
Here's what happens without a task queue: User clicks "send newsletter to 10,000 subscribers" → your web server tries to send 10,000 emails → it takes 5 minutes → your app is frozen → users think it's broken → you get angry Slack messages.
Celery fixes this by saying "yeah I'll handle that" and doing the work in the background while your app immediately responds with "email sending started." This pattern is so common that Django's official docs specifically recommend Celery for background tasks.
What Actually Happens Under the Hood
You've got four pieces: your web app throws jobs into a message queue (Redis or RabbitMQ), worker processes grab jobs and do the actual work, and optionally a result backend stores what happened. It's not rocket science but it works.
Latest version is Celery 5.5.3 (as of late 2024). It works with Python 3.8-3.13 and doesn't randomly crash like v4.x did. Python 3.13 support was a complete shitshow because v5.4 broke with async/await changes. Spent 4 hours debugging "SyntaxError: 'await' outside function" messages - ask me how I know.
Performance Reality Check
Celery can theoretically handle millions of tasks per minute. In practice, you'll probably get thousands per second, which is more than enough unless you're running Twitter. The actual speed depends on what your tasks are doing - sending an email is fast, generating a PDF with 500 pages is not.
Default configuration is mediocre but works. You'll need to tune it if you want it to scream, but honestly most people never bother and it's fine.
When Celery Makes Sense
Celery is overkill for simple "send an email later" jobs - RQ does that just fine. But if you need complex workflows like "process this data, then generate a report, then email it to these people, but only if the data processing worked," Celery's Canvas system handles that stuff.
It integrates with Django without making you want to throw your laptop out the window. Flask and FastAPI work fine too. There's a whole monitoring ecosystem (Flower, Prometheus, Sentry) that actually helps you figure out when things break.
The retry mechanisms work well once you figure out the configuration. Auto-scaling is possible with Kubernetes but expect to spend some time getting it right.