Bun is stupidly fast - like 4x faster than Node for HTTP stuff - but here's the thing: fast doesn't mean stable. I learned this the hard way when our API went down for 2 hours because Bun's Docker container kept dying with exit code 143 and nobody fucking tells you about the --init flag.
What Actually Breaks in Production
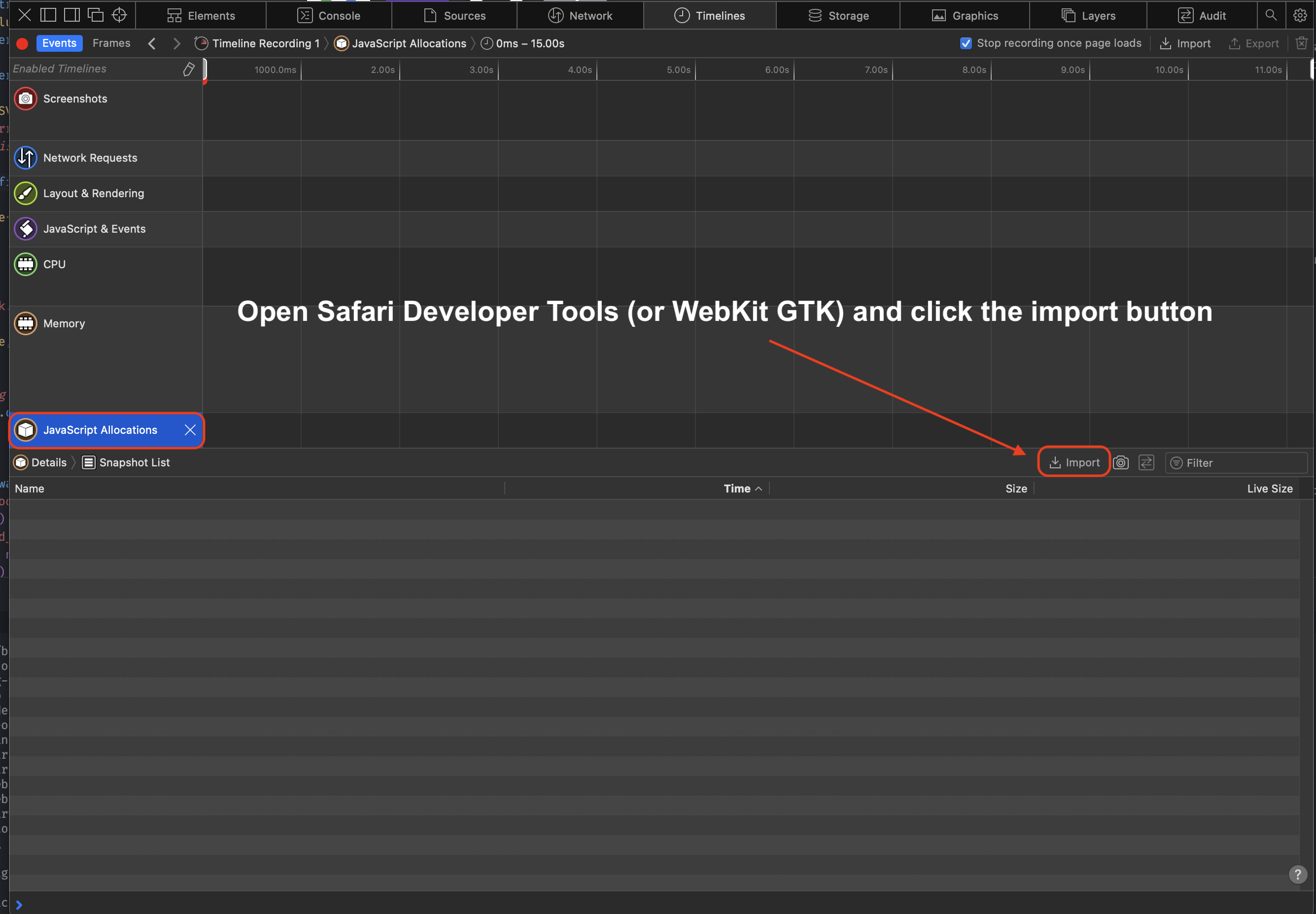
Here's what happens when you deploy Bun without knowing the gotchas:
Docker Containers Die Randomly:
Your containers will exit with code 143 because Docker's signal handling is fucked and Bun doesn't handle SIGTERM properly. Took me forever to debug - like 6 hours maybe? - before finding you need --init:
## This will randomly kill your container
CMD ["bun", "run", "start"]
## This actually works
CMD ["bun", "--init", "run", "start"]
Memory Leaks in JavaScriptCore:
Bun's memory handling is different enough to bite you. Our staging server was leaking memory - think it was like 2 gigs? Either way, way too much. Closure-based leaks that we didn't know how to profile because V8 tools don't work. You need JSC-specific debugging tools.
How to Not Let Bun Eat All Your RAM
Here's the thing about Bun's memory management: it's different enough from Node to bite you in the ass, but similar enough that you won't see it coming. JavaScriptCore handles memory allocation differently than V8 - objects pile up in different heap regions, garbage collection triggers differently, and the tools you're used to won't work.
Track Memory Before It Kills Your Server:
Monitor memory usage because Bun will OOM your container with zero warning:
import { heapStats } from "bun:jsc";
// Check every 30 seconds or your server dies at 3am
setInterval(() => {
const stats = heapStats();
const memMB = Math.round(stats.heapSize / 1024 / 1024);
// Alert before you hit the limit
if (memMB > 800) {
console.error(`Memory getting scary: ${memMB}MB`);
}
}, 30000);
The Memory Leaks That Will Ruin Your Weekend:
After 6 months of this shit randomly breaking:
- Request handlers that never clean up: Every Express middleware that doesn't remove listeners will slowly kill your server
- Database connection pools going insane: Bun's SQL connection handling can leak connections if you don't explicitly close them
- The setTimeout/setInterval spiral of death: Create too many timers and watch your memory climb forever
Server Setup That Won't Crash Every 5 Minutes
Bun.serve() Config That Actually Works:
Fuck the docs - here's what you actually need:
Bun.serve({
port: process.env.PORT || 3000,
hostname: '0.0.0.0',
development: false,
// This shit actually matters in production
reusePort: true, // Multiple processes can bind to same port
lowMemoryMode: true, // Don't eat all the RAM
fetch(request) {
// Don't do fancy shit here - just return responses
try {
return handleRequest(request);
} catch (error) {
// Log the real error for debugging
console.error(`Request failed: ${request.url}`, error.message);
return new Response('Server shit the bed', { status: 500 });
}
},
error(error) {
// Production errors need context, not just the message
console.error('Bun server error:', {
message: error.message,
stack: error.stack,
timestamp: new Date().toISOString()
});
return new Response('Internal Server Error', { status: 500 });
}
});
Docker Config That Won't Die Every 10 Minutes:

This Dockerfile actually works - learned through 3 days of containers randomly dying because Docker signal handling is broken:
FROM oven/bun:1.2-slim
## Don't skip these or you'll hate your life
ENV NODE_ENV=production
ENV BUN_RUNTIME_TRANSPILER_CACHE_PATH=/tmp/bun-cache
WORKDIR /app
COPY package.json bun.lockb ./
## Install only production deps - dev deps will break shit
RUN bun install --frozen-lockfile --production
COPY . .
## THE MOST IMPORTANT LINE - without --init your containers die with exit 143
## Took me 2 days to figure this out because nobody documents it properly
CMD ["bun", "--init", "run", "start"]
Performance Numbers That Actually Matter

When Bun Is Actually Faster:
Those benchmarks aren't complete bullshit - Bun legitimately crushes Node in specific scenarios:
- HTTP throughput: We went from 13k req/sec with Node to 52k with Bun on the same hardware
- CPU-heavy shit: Number crunching tasks that took Node 3.4 seconds finish in 1.7 seconds with Bun
- Cold starts: Serverless functions respond instantly vs Node's 300ms+ startup pain
The Reality Check:
Real apps hit databases constantly, so JavaScript speed matters less than you think. When you're CPU or I/O bound, Bun's speed is noticeable. But most apps spend their time waiting for databases and external APIs anyway.
Don't Overthink Concurrency:
// Just use Promise.allSettled - it works fine
async function handleBatchRequests(requests) {
const results = await Promise.allSettled(
requests.map(processRequest)
);
// Filter out the failures and move on
return results
.filter(r => r.status === 'fulfilled')
.map(r => r.value);
}