The Protobuf Workflow
You define your API in .proto files, then generate code for whatever languages you're using. The generated code handles serialization, networking, and type safety. It works pretty well once you get used to it.
The workflow looks like:
- Write
.proto definitions (like writing an interface)
- Run
protoc to generate client/server code
- Implement server logic using generated interfaces
- Use generated client to call services
Sounds simple, right? Here's what actually happens in production.
What Breaks in Production
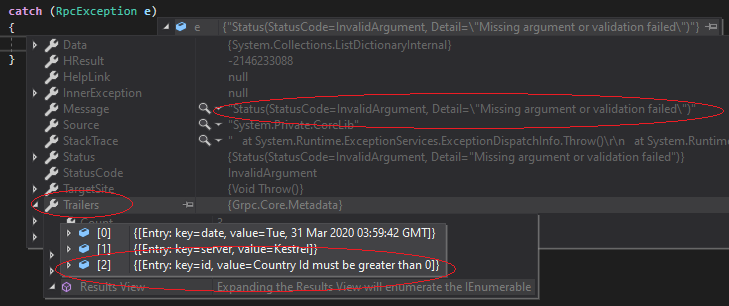
Debugging HTTP/2 Issues: When gRPC breaks, it breaks weird. Your existing HTTP debugging tools (curl, Postman, browser dev tools) don't work. You need `grpcurl` and friends. Network issues manifest as connection hangs instead of clear HTTP error codes. HTTP/2 debugging is fundamentally different from HTTP/1.1.
Load Balancer Hell: Most load balancers are designed for HTTP/1.1. HTTP/2 connection multiplexing means all requests from a client go over one connection, so naive load balancers send all traffic to one backend. You need L7 load balancing or client-side load balancing, which adds complexity. Envoy proxy handles this properly.
Schema Evolution Pain: Protobuf schema changes can break clients in subtle ways. Add a required field? Old clients crash. Change field numbers? Everything dies silently. Rename fields? Good luck debugging that. You need strict versioning discipline and backward compatibility guidelines.
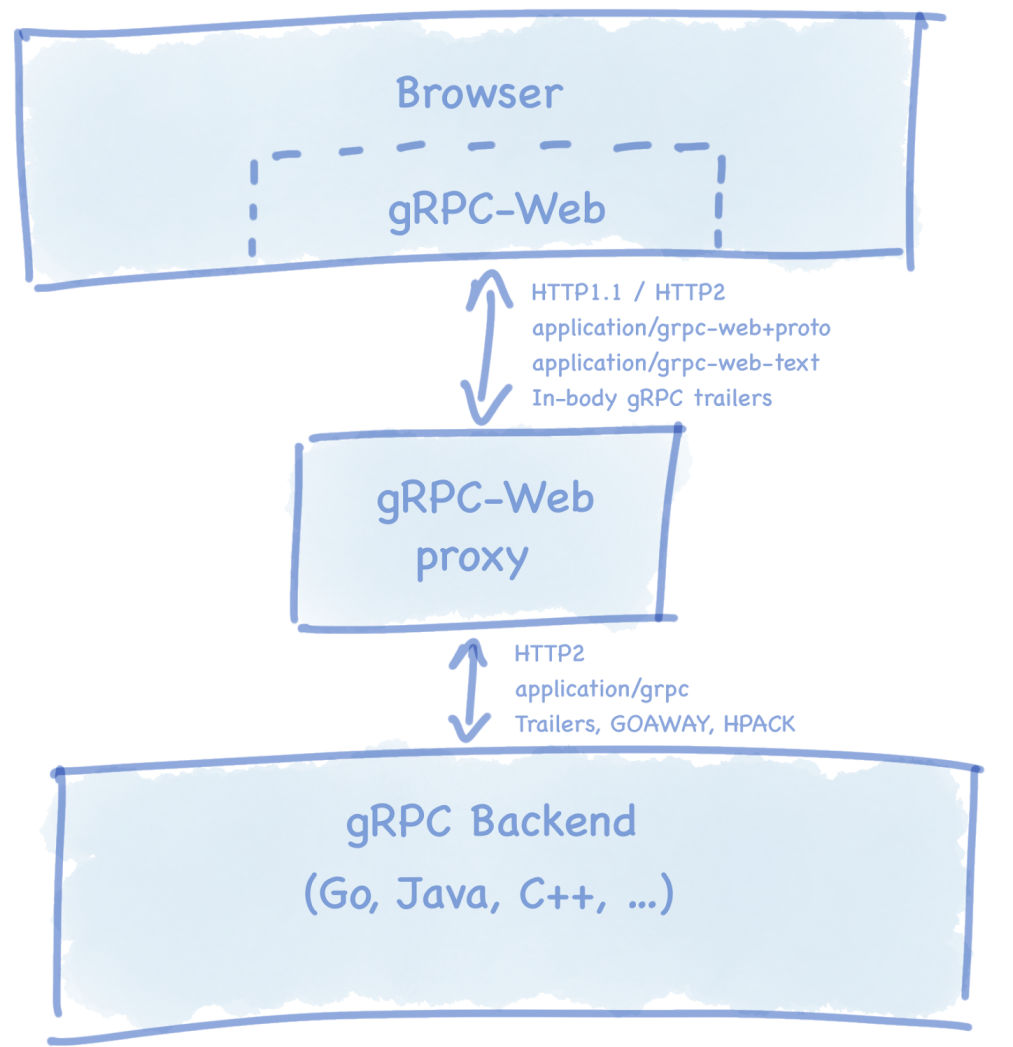
Browser Compatibility Nightmare: Browsers don't support gRPC natively. You need gRPC-Web, which is a proxy that translates between gRPC and HTTP/1.1. It works but adds another moving part to break. Browser limitations are well documented.
Language Implementation Quality
Go: Rock solid, used by Google internally. grpc-go is the reference implementation. Fast, good tooling, works as expected. Go tutorials cover everything you need.
Java: Mature, well-maintained. grpc-java used heavily in enterprise. Slightly verbose but reliable. Netty integration provides excellent performance.
Python: Works fine but the async story was messy for a while. Better now with `grpcio-status`. Python implementation is solid in recent versions.
Node.js: Had some rough edges early on. I hit memory leaks in Node.js gRPC 1.6.x that brought down our chat service twice before I figured out the upgrade was necessary. If you're still on anything before 1.7.0, upgrade immediately. gRPC-Node 1.50.x has connection pool issues - skip to 1.51+. Better now but still not as polished as Go/Java. Node.js implementation has improved significantly.
C++: The original implementation. Fast but complex. You probably don't need it unless you're optimizing for microseconds. C++ docs cover advanced usage.
Monitoring and Observability
gRPC integrates with OpenTelemetry and Prometheus out of the box, which is nice. But your existing HTTP monitoring dashboards won't work. You need gRPC-specific metrics and alerts. Jaeger tracing works well with gRPC services.
Error reporting is different too - no HTTP status codes, just gRPC status codes. Your error aggregation needs to understand the difference between CANCELLED and DEADLINE_EXCEEDED. gRPC health checking provides standardized health endpoints.
When It Actually Works Well
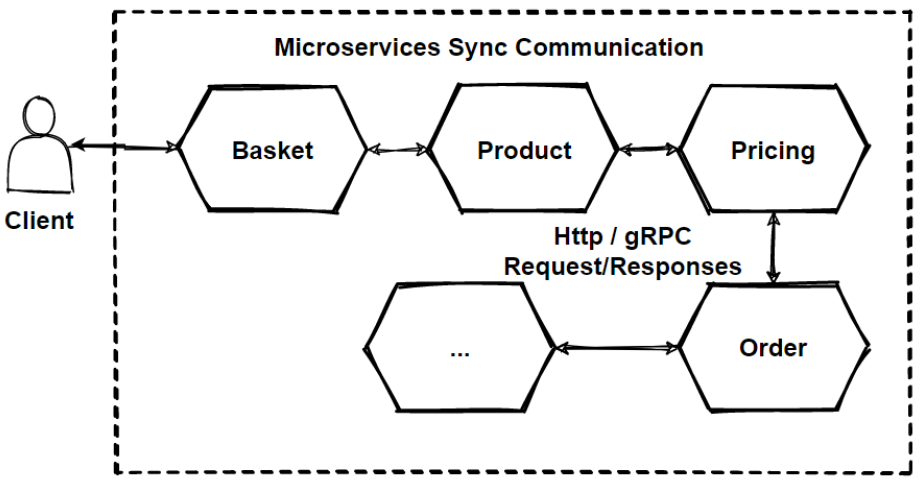
Internal service-to-service communication in Kubernetes works great. Service discovery, load balancing, and SSL termination all have good tooling. gRPC shines when you control both ends of the communication and care about performance. Service mesh integration with Istio provides excellent observability.
It's less great for public APIs where you need broad compatibility and easy debugging. REST remains better for external developer-facing APIs.