This isn't just four tools working together - it's four different ways for things to break simultaneously. But here's the thing: after you survive the initial pain, you get automated deployments that actually don't suck. The stack becomes worth it when you're deploying 50+ times a day without breaking into a cold sweat.
What Each Tool Actually Does
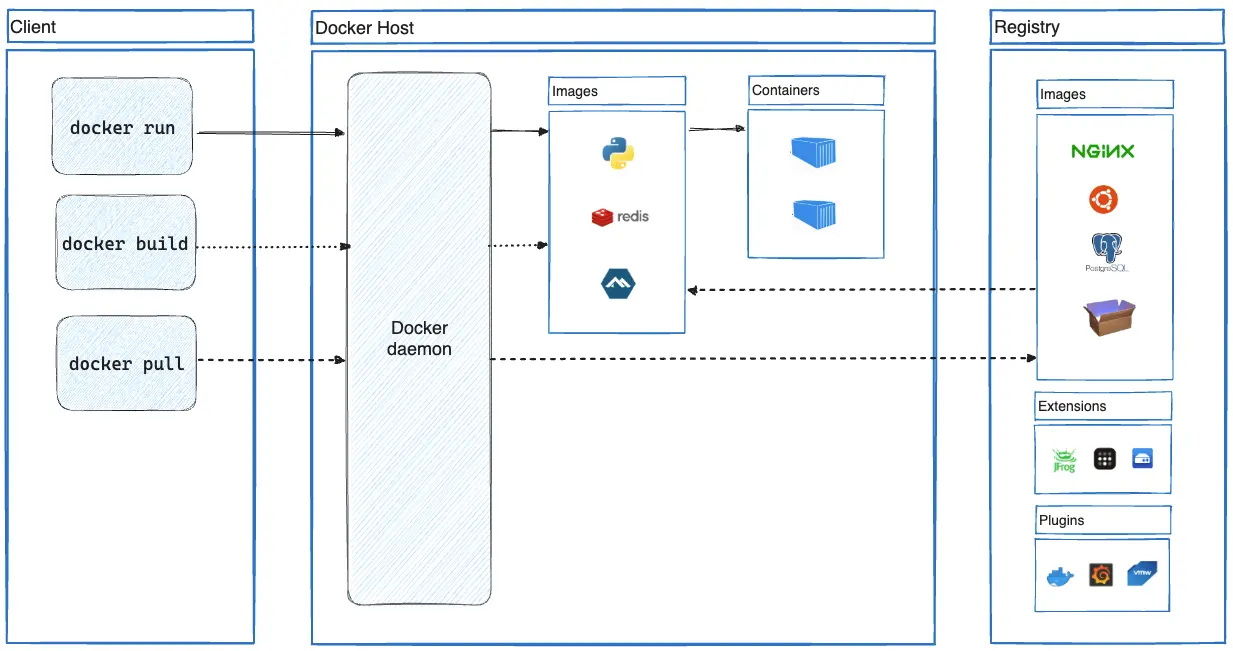
Docker packages your app into containers. Works great until you hit the layer cache bullshit or Docker Desktop randomly stops working and you spend an hour restarting everything. The build optimization docs help, but multi-stage builds are still your best bet for cache performance.

Kubernetes orchestrates those containers. It's powerful as hell, but the learning curve is steeper than tax law. Don't use K8s 1.28.3 - there's a networking bug that'll ruin your week. Stick with 1.29.x.
ArgoCD watches your Git repos and deploys changes automatically. The UI is pretty but times out whenever you're trying to debug a failed deployment. ArgoCD 2.11.x randomly stops syncing - upgrade to 2.12.x or deal with mysterious failures.
Prometheus monitors everything and sends you alerts at 3am. It works great until you see your storage bill. Seriously, configure retention policies or you'll be paying for metrics from 2019.
How It's Supposed to Work
You commit code → Docker builds it → ArgoCD sees the change → Kubernetes deploys it → Prometheus monitors it → You sleep peacefully at night (haha, right).
In reality: You commit code → Docker build fails because of some random layer issue → You fix that → ArgoCD doesn't sync because of a webhook timeout → You manually refresh → Kubernetes pod crashes with CrashLoopBackOff → You debug for an hour → Prometheus fills up your disk with metrics → You fix the retention policy → It finally works → You get an alert at 2am anyway.
But here's the thing: after 6 months of fighting this stack, deployments go from taking 2 hours to 5 minutes. And when something breaks, you actually know why. That's the real value - not the automation itself, but the observability and consistency that comes with it.
Now let's talk about what actually happens when you try to implement this beautiful theory in the real world.

