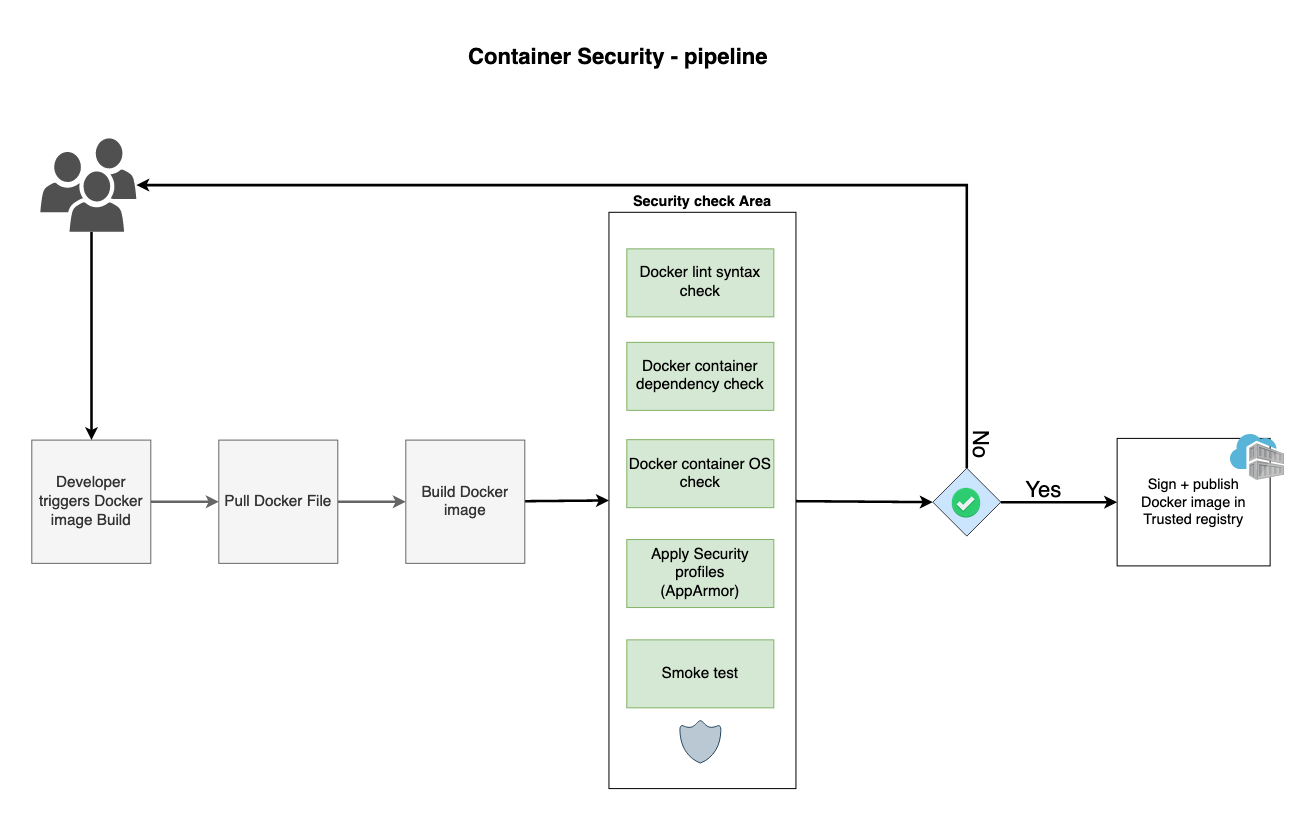
Today is Thursday, August 28, 2025. Let me tell you about admission controllers - the security gatekeepers that will absolutely ruin your deployment plans when they break. I've spent way too many 3am debugging sessions figuring out why perfectly good containers suddenly can't deploy.
The Real Problem Nobody Talks About
Here's what actually happens when you deploy a container in a cluster with admission controllers: your pod hits the API server, which then calls out to a webhook that's supposed to scan your image for vulnerabilities. Sounds simple, right? Wrong.
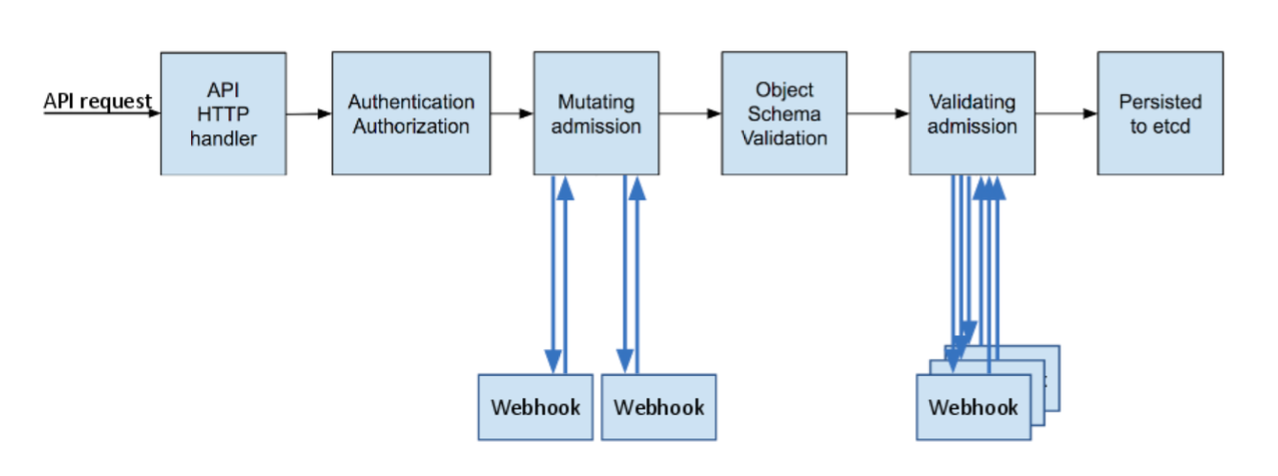
The admission controller has 10 seconds (default timeout) to:
- Download your potentially massive container image
- Run a full vulnerability scan against multiple CVE databases using tools like Trivy or Snyk
- Apply whatever insane security policies your security team dreamed up
- Return a decision
This is like asking someone to perform brain surgery during a commercial break. It's not happening.
What Actually Goes Wrong (From Personal Experience)
The "admission webhook denied the request" Nightmare
This error message is about as helpful as a screen door on a submarine. I've seen this break deployments for hours because:
![]()
- The webhook timed out because someone deployed a 2GB enterprise image with 50,000 packages
- Network policies blocked the admission controller from talking to the scanner API
- Two different security tools disagreed about whether the same CVE is critical or medium (check the NIST NVD for reference)
Webhook Timeouts That Will Drive You Insane
Kubernetes defaults to a 10-second timeout for webhooks. Meanwhile, scanning a typical enterprise Java application takes 45 seconds minimum according to container scanning benchmarks. The math doesn't work. When it times out, some admission controllers fail "open" (let everything through - great security!), others fail "closed" (block everything - great for your weekend plans). This is controlled by the failurePolicy setting.
I learned this the hard way when our Node.js images suddenly started taking 60 seconds to scan after a dependency update added 200 new packages. Guess what happened at deployment time?
Multiple Security Tools Playing King of the Hill
Your security team probably deployed Falco, OPA Gatekeeper, Kyverno, and three different vendor tools all doing admission control.
![]()
They'll conflict with each other in creative ways:
- Tool A says the image is fine
- Tool B says it's got critical vulns
- Tool C crashes trying to scan it
- Your deployment fails with a generic "webhook failed" message
Good luck figuring out which one is lying.
The CI/CD Death Spiral
When admission controllers fail, they don't fail gracefully. They fail spectacularly and take your entire deployment pipeline with them.
Real Production Horror Story
I watched a team lose an entire Friday because their GitLab CI/CD pipeline started failing every deployment with Kubernetes executor issues.
The error? "admission webhook denied the request". No details. No logs. Just pain.
Turned out their vulnerability scanner had been down for 6 hours, but the admission controller was configured to fail closed. Every single deployment - dev, staging, prod - blocked. The security team was unreachable (of course), and nobody knew the emergency override procedure.
The Disable-Everything Panic Response
When deployments are failing and the CEO is breathing down your neck, teams start disabling admission controllers to "get deployments flowing again". Now you've got vulnerable containers running in production because your security automation became the problem instead of the solution.
Root Cause: Everyone's Lying to You
The dirty secret nobody mentions: the entire architecture is fundamentally broken.
Synchronous Design, Asynchronous Reality
Admission controllers expect instant responses. Vulnerability scanning is inherently slow - you're analyzing thousands of packages against constantly-updating CVE databases that can be hundreds of GB in size. It's like trying to fit an elephant through a keyhole.
Network Dependencies Are a Single Point of Failure
Your admission webhook needs to call out to external services over the network. Corporate firewalls block it. Proxy configurations break it. The scanning service goes down and takes your deployments with it.
Scanner APIs Are Unreliable
Every vulnerability scanner has different APIs (Trivy's API, Snyk's API, Grype's API), different authentication, different response formats, and different ideas about what constitutes a security vulnerability. Trying to make them all work together is like herding cats that are on fire.
The only way to fix this mess is to stop trying to do real-time vulnerability scanning at deployment time. But first, you need to survive the next outage.