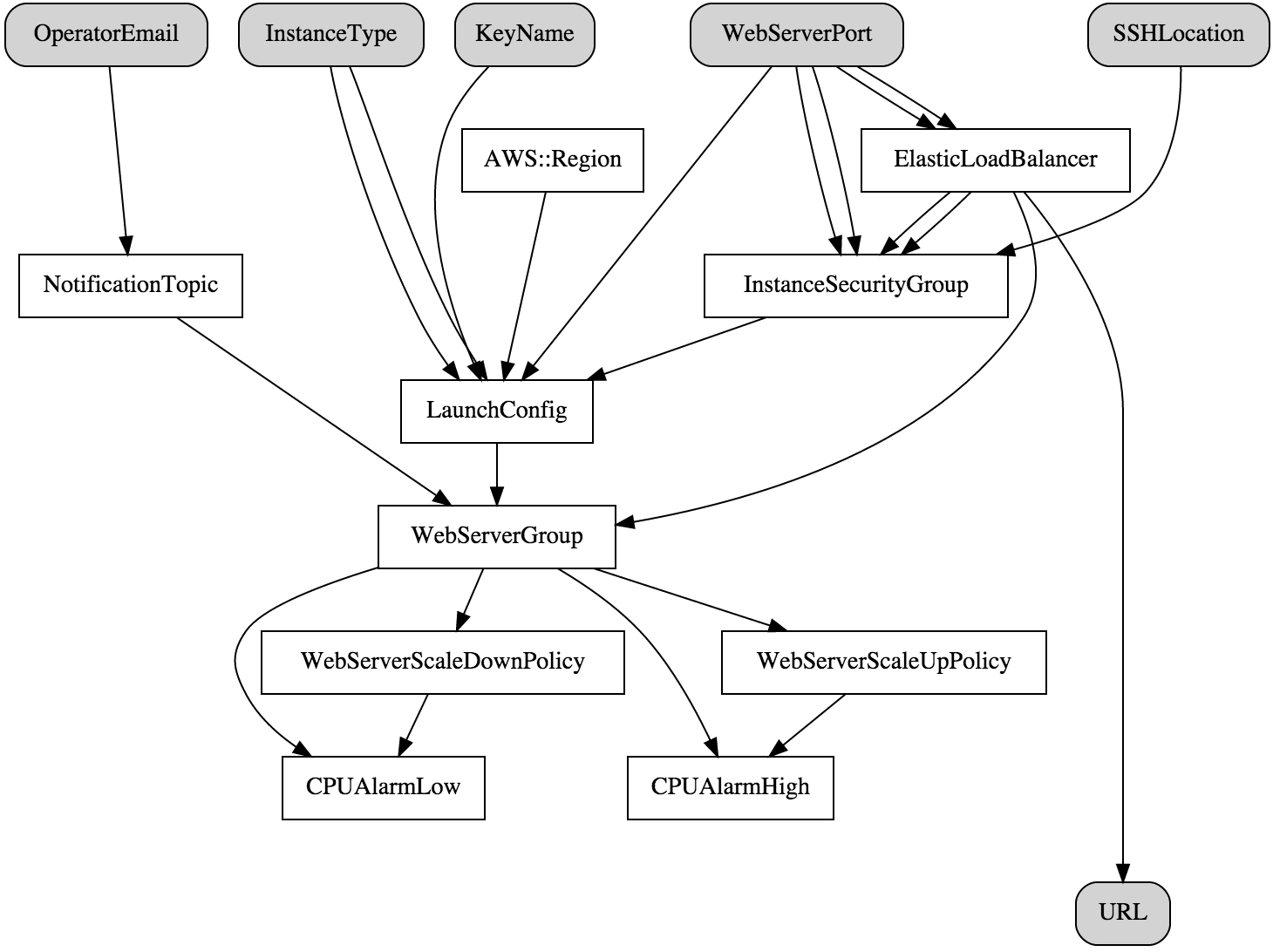
Tuesday night. My critical production deployment that worked perfectly in dev just shit the bed in production. The manager is breathing down my neck, the release is delayed, and I'm staring at CloudFormation error messages that might as well be written in ancient hieroglyphs.
"Cannot assume role" screams one error. "Resource already exists" taunts another. Each deployment attempt takes 20 minutes – enough time to contemplate career changes and watch my team's patience evaporate faster than our AWS credits.
I've been running AWS CDK in production for two years, and let me tell you - the tutorials don't mention the 3 AM debugging sessions or the creative solutions you'll use when CloudFormation decides to have an existential crisis. Here's the real shit that happens when your infrastructure deployment goes sideways.
The Reality Check Nobody Gives You
CDK in production is nothing like AWS marketing sells you. Yeah, TypeScript is infinitely better than YAML hell, but underneath it all, you're still at the mercy of CloudFormation. When everything goes sideways (and it will), you'll be frantically clicking through the AWS console trying to decode CloudFormation error messages while your app burns and users rage on Twitter.
The most brutal part? CDK deployment failures often leave you in limbo states that require manual intervention. Your infrastructure code is perfect, but CloudFormation decides to have an existential crisis, and suddenly you're the one cleaning up the mess.
The UPDATE_ROLLBACK_FAILED Nightmare

Every engineer who's used CloudFormation has this recurring nightmare: you wake up in a cold sweat dreaming about "UPDATE_ROLLBACK_FAILED." It's really difficult to recover from, and it always happens when you need to ship critical fixes.
Picture this: urgent production bug, one-line config change, should take 5 minutes tops. CloudFormation decides Tuesday night is the perfect time to completely lose its shit with UPDATE_ROLLBACK_FAILED. Now I'm stuck there until 3 AM, frantically Googling "CloudFormation rollback recovery" like it's going to save my career, while angry Slack messages pile up from customers who can't use the app because AWS decided to hold my deployment hostage.
What triggers this hell? Usually Lambda layer updates within functions. The function can't revert to the prior state if the previous layer is absent due to rollback sequencing. Or nested stack fuckery where resources get stuck in UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS.
The nuclear option: Go to CloudFormation console → Stack Actions → Continue Rollback → Skip the failing resources. Yes, this leaves your infrastructure in an inconsistent state. Yes, you'll need to manually fix it later. But at least you can deploy fixes while customers are screaming.
The 12-Hour Debugging Marathon
Migrating 12 production applications from CDK v1 to v2 exposed every hidden configuration issue lurking in my infrastructure code. What AWS promised as a "cleaner, more modular experience" turned into debugging deployment errors that were harder to Google than CDK v1 issues.
The "Resource already exists" Friday afternoon special:
You're trying to ship a quick fix. CDK deploys fine in dev, staging, and 3 other environments. Production? "Resource already exists." This happens when your stack references resources created outside CDK, or when previous deployments failed partially and left orphaned resources.
Solution that actually works: cdk diff shows the resource conflict. Either import the existing resource with `Fn::ImportValue` or delete it manually. Sometimes you need to nuke the entire stack and redeploy – which is terrifying in production but sometimes the only option.
Asset Bundling: The Silent Killer
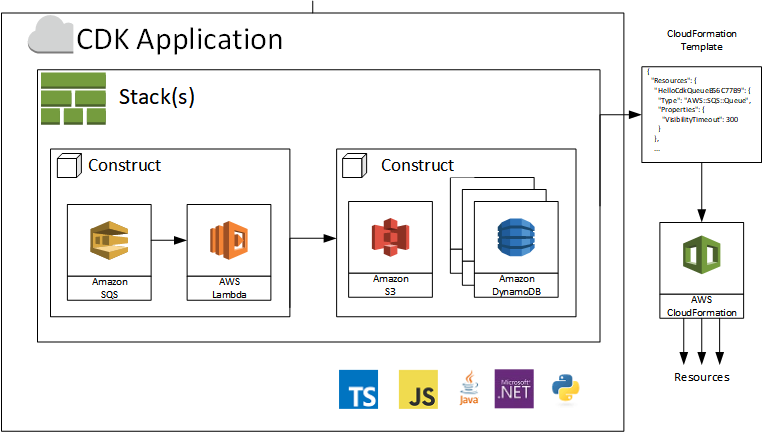
CDK's asset bundling looks convenient until it kills your deployment workflow. I had a Lambda function with heavy dependencies – deployment went from 5 minutes to 25 minutes because CDK rebuilds assets every time, even for config-only changes.
The gotcha nobody tells you: A simple environment variable change becomes a 20-minute ordeal because CDK bundles your function code again. Asset bundling includes Docker build time during deployment. That 15-minute deployment becomes 30+ minutes.
Learned the hard way: Use --exclusively flag to skip asset bundling when you're only changing configuration. Or build assets in CI and reference them in CDK. The convenience isn't worth watching progress bars for half your day.
The Hidden Cost Bomb
I used CDK's ECS patterns for a quick prototype - literally one line of code and boom, automatic ECS cluster. I felt like a fucking genius. "Look at me, deploying enterprise-grade container infrastructure with TypeScript!" Three weeks later the AWS bill drops on my desk like a brick: $847.32. For a prototype that nobody even used. Nobody.
Turns out the "convenient" L3 pattern created its own NAT gateway, VPC, ECS cluster, CloudWatch log groups, and a bunch of SQS queues I didn't even know existed. I think the NAT gateway alone was like $45/month just sitting there. The L3 constructs hide every infrastructure decision that actually costs money.
Always check what CDK generates: cdk synth shows the CloudFormation template. Always review it before deploying, especially with L3 constructs. They make assumptions about your architecture that might not match your budget.