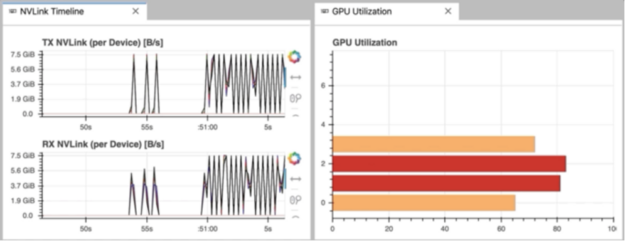
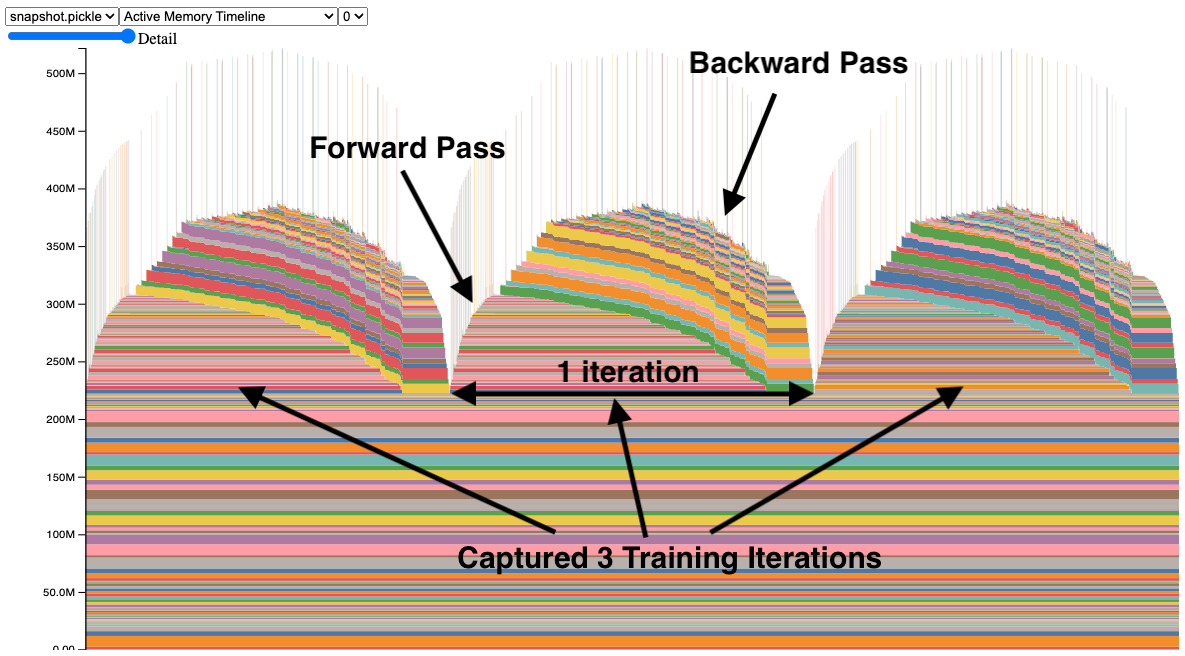
Today is September 11, 2025. Based on current research, Ollama users are experiencing a recurring set of memory and GPU allocation issues that can make or break their local AI experience. These problems have become more prominent with recent model releases and the introduction of new memory management features in Ollama 0.11.x series.
The Core Problems: What's Actually Breaking
Ollama's memory management has evolved significantly, but this evolution has introduced new failure modes that affect both casual users and production deployments. Unlike simple setup issues, these are deep technical problems rooted in how Ollama estimates, allocates, and manages GPU memory.

Docker adds yet another layer of complexity to GPU memory management
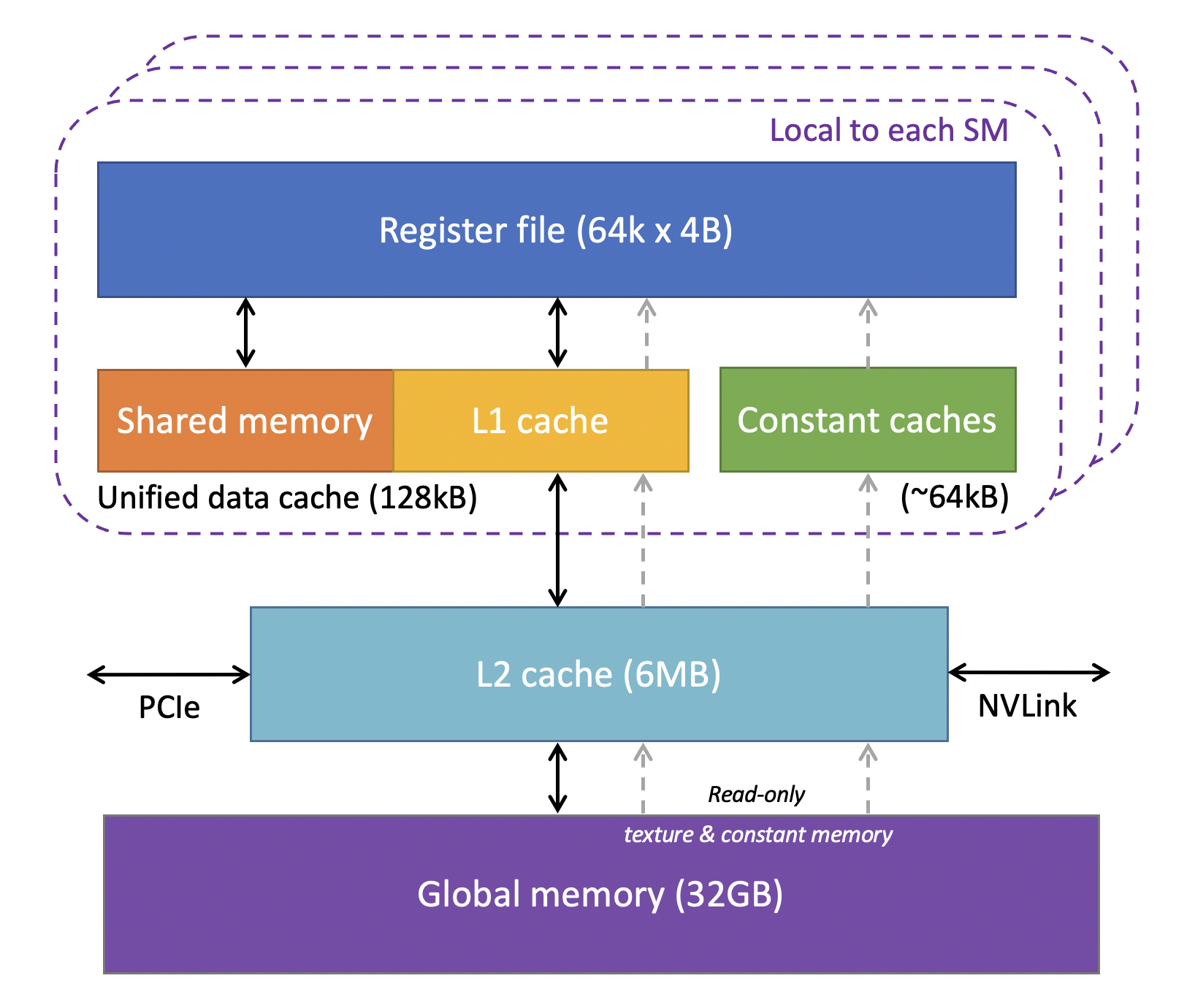
GPU memory levels and hierarchy showing how data flows through different cache layers
Memory Leaks: The Silent System Killer
Memory leaks in Ollama have become particularly problematic with recent versions, with users reporting RAM usage going from like a gig to some crazy amount - maybe 40 gigs or something insane like that over extended sessions. These leaks manifest in several ways:
- VRAM stays allocated after model unloading, requiring manual cleanup
- System RAM consumption grows continuously during long conversations
- Context memory accumulation in multi-turn conversations never gets freed
- GPU memory fragmentation prevents loading new models even when sufficient VRAM exists
This happens because Ollama's memory management is garbage. When you load and unload models, GPU memory doesn't get properly released, so you end up with fragmentation that eventually prevents any new model loading. Making it worse, CUDA's memory allocation behavior and driver-level memory management add another layer of unpredictability.
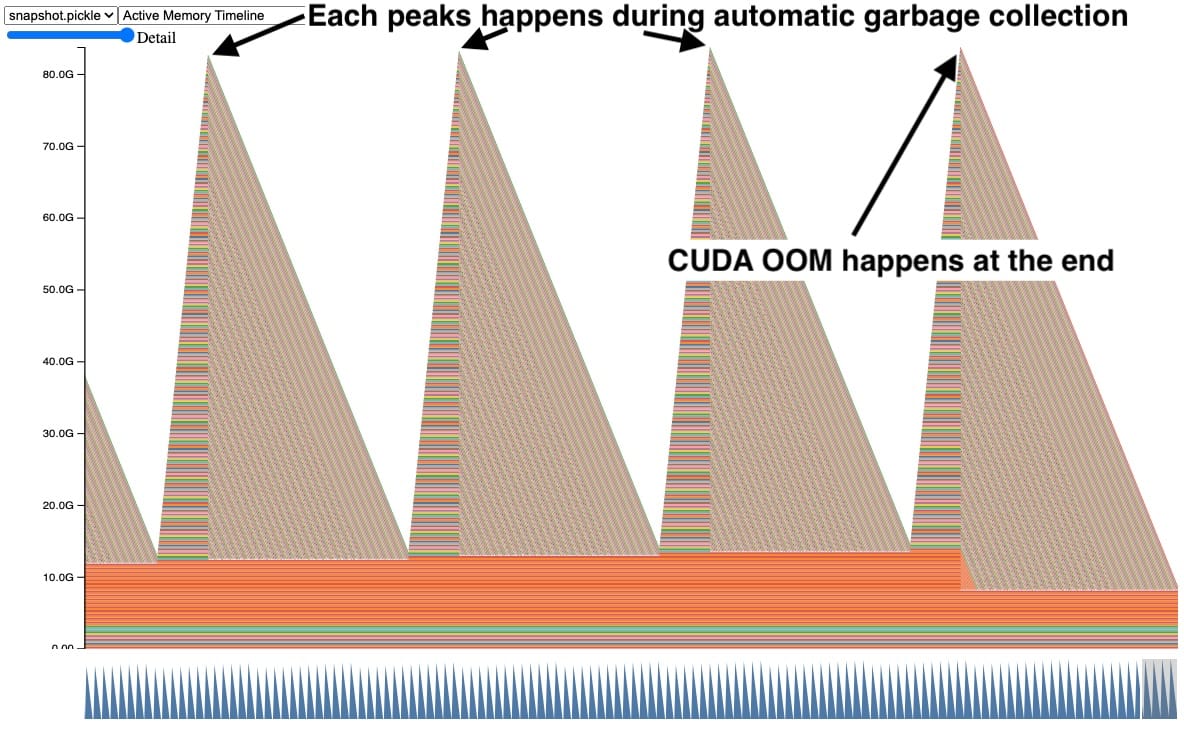
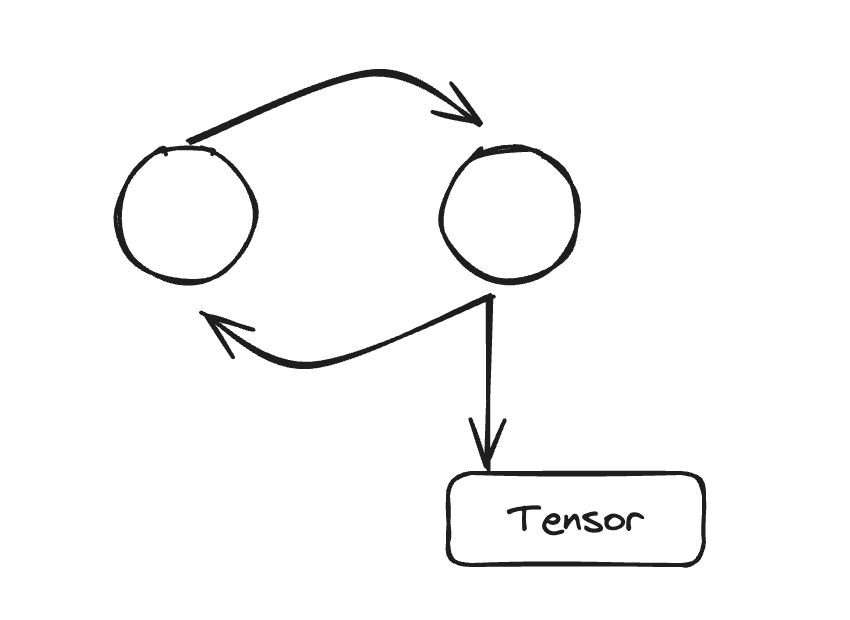
Typical GPU memory leak pattern - tensors accumulate over time until OOM occurs, indicating reference cycle issues
CUDA Out of Memory: The 4GB GPU Nightmare
The classic "CUDA error: out of memory" affects users with smaller GPUs disproportionately. Recent reports show that even 4GB VRAM systems that previously worked with specific models now fail after Ollama updates.
This isn't just about model size. Ollama's memory estimation algorithms have changed, and the new estimation system sometimes overestimates memory requirements, causing models that should fit to be rejected. The OLLAMA_NEW_ESTIMATES environment variable was introduced to address this, but it's not well documented and many users don't know it exists. This affects model compatibility across different hardware configurations.
Model Switching Failures: When GPU Memory Gets Stuck
Model switching has become unreliable, especially for users with limited VRAM. The process of unloading one model and loading another often fails with memory allocation errors, even when the target model is smaller than the previous one.
This happens because:
- Ollama doesn't wait for GPU memory cleanup before loading new models
- Memory fragmentation prevents contiguous allocation for new models
- The memory estimation system doesn't account for fragmentation overhead
- Multiple models can partially load, consuming VRAM without being usable
The OLLAMA_NEW_ESTIMATES Solution
Ollama 0.11.5 introduced improved memory estimation, but it's controlled by an environment variable that's not widely known. The new estimation system changes how GPU memory allocation is calculated, often allowing models to load that previously failed.
But turning on new estimates can also cause instability in some configurations, creating a trade-off between compatibility and memory efficiency. If you're running a 1650 with 4GB VRAM, prepare for suffering - you'll be fighting allocation failures constantly.
Why These Problems Persist
Memory is fucked because you've got System RAM, GPU VRAM, and a bunch of driver bullshit all fighting each other. CUDA, ROCm, and Metal drivers each handle memory differently and love to break in creative ways. Then you've got GGUF quantization affecting memory usage in non-linear ways that make estimation a pain in the ass, combined with operating system differences where Windows, Linux, and macOS all handle GPU memory allocation differently.
The interaction between these systems creates edge cases that are difficult to predict and test comprehensively. What works perfectly on one system configuration may fail catastrophically on another with seemingly similar specifications.
The Real Impact on Users
Everyone gets fucked by these issues differently. I've seen systems eat 64GB of RAM in an hour during a conversation. Had a demo crash right in front of a client because Ollama decided to leak memory during model switching. One guy on Discord lost his weekend because his production chatbot kept OOMing every few hours - turns out it was the context accumulation bug. Another dude's workstation froze solid during a Blender render because Ollama wouldn't release GPU memory properly.
And the error messages? Completely useless. You get "CUDA error: out of memory" when you have 6GB free, or silent failures where models just refuse to load with zero indication why.
What This Guide Covers
This troubleshooting guide provides practical solutions for the most common memory and GPU allocation issues affecting Ollama users as of September 2025. We'll cover:
- Diagnosing memory leaks and preventing system crashes
- Configuring GPU memory allocation for optimal performance
- Using environment variables to fix CUDA out of memory errors
- Implementing proper model switching workflows
- Monitoring memory usage to prevent problems before they occur
- Recovery strategies when memory allocation fails completely
Each solution includes specific commands, configuration changes, and verification steps. We focus on fixes that actually work in real-world scenarios, not theoretical optimizations that sound good but fail under load.
The goal is to make Ollama memory management predictable and reliable, regardless of your hardware configuration or use case.