Why Your Query Hits the Database 500 Times Instead of Once
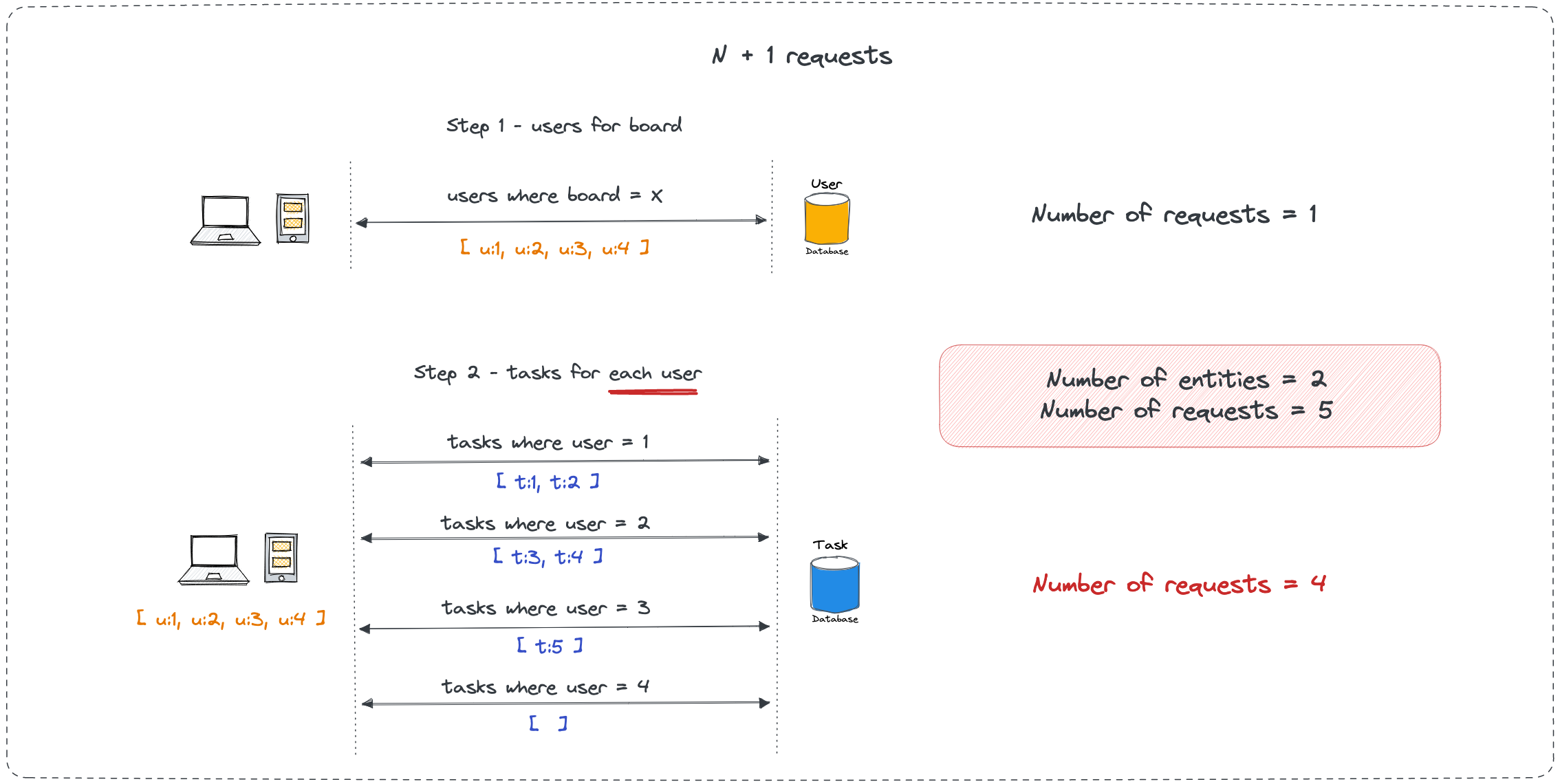
The N+1 problem is why GraphQL APIs get slow. It's sneaky and will kill your database. Every GraphQL API that sees real traffic needs DataLoader - no exceptions.
Here's what happens: you write a query that looks innocent, but it triggers individual database calls for every piece of related data.
query GetPostsWithAuthors {
posts(first: 10) {
title
author {
name
}
}
}
Looks innocent, right? Wrong. This query actually generates 11 database queries:
SELECT * FROM posts LIMIT 10- gets the postsSELECT * FROM users WHERE id = 1- author for post 1SELECT * FROM users WHERE id = 2- author for post 2- ...and so on for all 10 posts
Saw this bring down our production database during a marketing campaign. Traffic spiked and suddenly the database was getting hit with thousands of individual queries instead of a few optimized ones. Database CPU at 100%, everything crashed.
DataLoader Fixes This By Batching Queries
DataLoader batches individual loads that happen during a single tick of the event loop. Instead of 10 separate user queries, it waits a few milliseconds and batches them into one query. Facebook built this to solve their own N+1 problems at scale.
import DataLoader from 'dataloader';
// This function gets called with an array of IDs
const batchLoadUsers = async (userIds) => {
const users = await db.query('SELECT * FROM users WHERE id IN (?)', [userIds]);
// CRITICAL: Return users in the same order as the input IDs
return userIds.map(id => users.find(user => user.id === id) || null);
};
// Create the loader
const userLoader = new DataLoader(batchLoadUsers);
// Use it in resolvers
const resolvers = {
Post: {
author: (post) => userLoader.load(post.author_id),
},
};
Now that query that was hitting the database 11 times only hits it 2 times: once for posts, once for all the authors.
The key thing is creating the DataLoader in your GraphQL context so it's scoped to the request:
const server = new ApolloServer({
context: () => ({
userLoader: new DataLoader(batchLoadUsers),
}),
});
Don't create global DataLoaders. Made that mistake once - users started seeing other people's data because the cache wasn't clearing between requests.
Query Complexity Analysis Prevents Abuse
Without limits, clients can write queries that eat massive resources. Seen queries that try to fetch every user with all their posts and all comments - millions of records. GitHub hit this problem and now has strict query complexity limits.
import { costAnalysis } from 'graphql-query-complexity';
const server = new ApolloServer({
typeDefs,
resolvers,
validationRules: [
costAnalysis({
maximumCost: 1000,
scalarCost: 1,
objectCost: 2,
listFactor: 10, // Lists are expensive
}),
],
});
This blocks queries before they run if they're too expensive. A simple query might cost 10 points, but a nested query with lists can easily cost thousands.
Memory Leaks From Subscriptions
GraphQL subscriptions are great until they start leaking memory. The problem is event listeners that never get cleaned up when clients disconnect.
// This will leak memory
const resolvers = {
Subscription: {
messageAdded: {
subscribe: () => pubsub.asyncIterator(['MESSAGE_ADDED']),
},
},
};
You need to handle cleanup manually:
const resolvers = {
Subscription: {
messageAdded: {
subscribe: () => {
const iterator = pubsub.asyncIterator(['MESSAGE_ADDED']);
// Clean up when the client disconnects
iterator.return = () => {
// Remove any event listeners here
return { done: true, value: undefined };
};
return iterator;
},
},
},
};
Debugged a Node process that was eating 8GB of RAM because subscription listeners never got cleaned up. Took 6 hours to figure out.
Monitor What Actually Matters
Regular HTTP monitoring doesn't work with GraphQL because everything goes through /graphql and returns 200 OK even when things break. GraphQL execution is like a tree of resolvers running concurrently, each potentially hitting your database at the same time.
const server = new ApolloServer({
plugins: [{
requestDidStart() {
const start = Date.now();
return {
willSendResponse(requestContext) {
const duration = Date.now() - start;
if (duration > 2000) {
console.warn('Slow GraphQL query:', {
duration,
operation: requestContext.request.operationName,
query: requestContext.request.query?.substring(0, 200),
});
}
},
didEncounterErrors(requestContext) {
console.error('GraphQL errors:', {
operation: requestContext.request.operationName,
errors: requestContext.errors.map(e => e.message),
path: requestContext.errors[0]?.path,
});
},
};
},
}],
});
Track query execution times, not just HTTP response times. GraphQL can return partial results with errors, so a 200 response doesn't mean everything worked.
The most useful metrics I've found are:
- P99 query execution time (catch the worst queries)
- Error rate by operation name (identify problematic queries)
- Database connection pool utilization (prevent exhaustion)
- Memory usage over time (catch leaks early)
For production monitoring, Apollo Studio works if you can afford it, or Sentry for error tracking. The key is tracking resolver-level performance, not just HTTP response times.

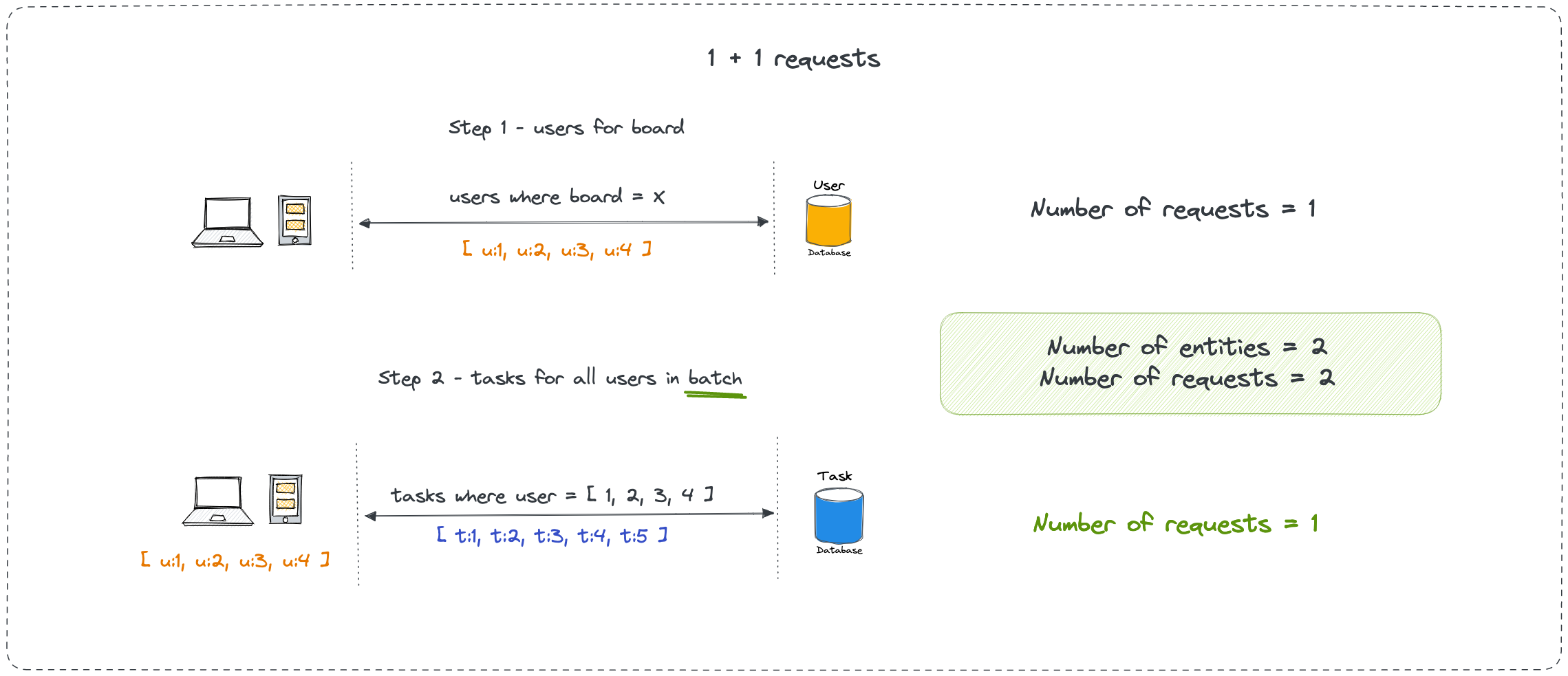 You're hitting the N+1 problem. Your innocent-looking query triggers hundreds of database calls instead of a few optimized joins.
You're hitting the N+1 problem. Your innocent-looking query triggers hundreds of database calls instead of a few optimized joins.