This is the most frustrating GPU problem you'll hit - your GPUs work fine at the OS level but Kubernetes acts like they don't exist. I've debugged this exact bullshit 47 times over the past 3 years. 95% of the time it's the device plugin being completely fucked. The NVIDIA device plugin is literally one pod that can kill your entire $500k GPU infrastructure when it crashes.
How GPU Discovery Actually Works (When It Doesn't Break)
Here's the fragile chain that breaks at least once a week:
- NVIDIA drivers detect GPUs at hardware level (usually fine)
- Device plugin DaemonSet tells kubelet about them (crashes here 80% of the time)
- kubelet registers GPU resources with API server (works if #2 didn't die)
- Scheduler can finally see and allocate GPUs (miracle if you get this far)
Any one piece shits the bed and your $50k GPU node becomes a very expensive CPU-only machine. The device plugin going down for 6 hours while nobody notices? Yeah, that was last fucking Tuesday. Cost us 3 hours of ML training time.
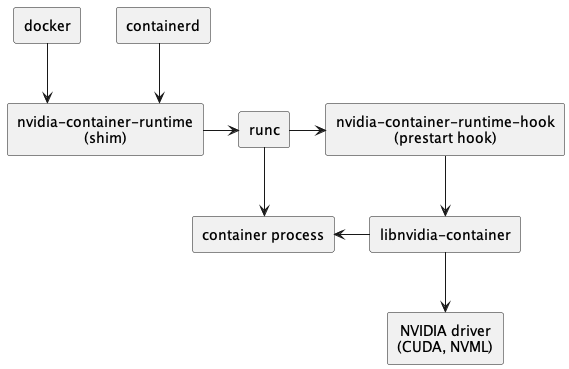
Device Plugin Crashes (And Takes Your GPUs With It)
The device plugin is a single point of failure - when it crashes, everything breaks. I've spent 4 hours debugging "insufficient nvidia.com/gpu" only to discover the device plugin had been crashed for 2 days and nobody noticed. Two fucking days of broken GPU allocation because monitoring was shit.
How to tell if your device plugin died and took your GPUs with it:
## Check if Kubernetes can see any GPUs (spoiler: it can't)
kubectl describe nodes | grep nvidia.com/gpu
## Returns nothing or "0" even though nvidia-smi shows GPUs
## Check device plugin pods (probably crashed)
kubectl get pods -n gpu-operator -l app=nvidia-device-plugin-daemonset
## Shows CrashLoopBackOff, ImagePullBackOff, or just straight up missing
Why device plugins actually crash in production:
Driver/CUDA version mismatches - the classic. Everyone deploys the latest device plugin image without checking what CUDA version their nodes actually have. Then wonder why it crashes immediately.
## Check driver version on node (this takes forever)
kubectl debug node/gpu-node-1 -it --image=busybox
## In debug container:
cat /host/proc/driver/nvidia/version
## Check what CUDA version the device plugin wants
kubectl logs -n gpu-operator nvidia-device-plugin-daemonset-xxx | grep -i "cuda\|driver"
Simple rule: device plugin CUDA version ≤ node driver version. Device plugin wants CUDA 12.2 but you have 11.8 drivers? It'll crash every fucking time with "CUDA driver version is insufficient for CUDA runtime version". I learned this at 11:47pm on a Friday, after 4 hours debugging "why won't this start", only to find the mismatch buried in log line 847. Of course.
Container runtime not configured for GPUs - another way things blow up. You need the NVIDIA Container Runtime properly set up or containers just can't see GPU devices even when they're allocated.
## Verify container runtime configuration
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, runtime: .status.nodeInfo.containerRuntimeVersion}'
## Check runtime class configuration
kubectl get runtimeclass nvidia -o yaml
Security context restrictions - security teams lock down everything, device plugin can't access GPUs. You need privileged access which makes security people uncomfortable, but there's no way around it:
## Device plugin needs to be privileged (security team will hate this)
## This broke twice before I got the host paths right
securityContext:
privileged: true # Required or device plugin can't see GPUs
capabilities:
add: ["SYS_ADMIN"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
- name: dev
mountPath: /dev # Has to be exactly /dev, not /dev/nvidia*
volumes:
- name: dev
hostPath:
path: /dev # This path matters - learned the hard way
GPU Operator: Great When It Works, Hell When It Doesn't
The NVIDIA GPU Operator is supposed to handle all the GPU software automatically. In reality, it's another layer of complexity that finds new and creative ways to break. I've watched it fail during installation 7 out of 10 times. Success rate on fresh clusters? Maybe 30% if you're lucky.
Pod Security Standards block everything because GPU software needs privileged access (obviously):
## The namespace needs to allow privileged containers or nothing works
kubectl create namespace gpu-operator
kubectl label namespace gpu-operator pod-security.kubernetes.io/enforce=privileged
kubectl label namespace gpu-operator pod-security.kubernetes.io/audit=privileged
kubectl label namespace gpu-operator pod-security.kubernetes.io/warn=privileged
If you don't set these labels, the operator pods will fail to start and you'll waste 30 minutes figuring out why. Ask me how I know this.
Installation resource contention turns your nodes into swap-thrashing disasters. The operator tries to deploy everything at once, which never works well:
## Watch the installation slowly fail
kubectl get pods -n gpu-operator -w
kubectl get events -n gpu-operator --sort-by='.lastTimestamp'
## Check if your nodes are dying under the load
kubectl describe nodes | grep -A 5 -B 5 "Pressure\|Evicted"
What actually works for installation:
Step 1: Just restart the damn device plugin first: kubectl delete pods -n gpu-operator -l app=nvidia-device-plugin-daemonset
Still broken? Then:
- Pin to a specific version that actually works:
helm install gpu-operator nvidia/gpu-operator --version=v25.3.0 - Slow down the rollout so it doesn't kill your nodes:
--set driver.rollingUpdate.maxUnavailable=1 - Actually read the prerequisites first (wild concept, I know, but it saves 2 hours)
Node Labeling and GPU Feature Discovery Problems
GPU discovery is another place things fall apart. You either get automatic labeling through NFD or you label nodes manually. Both approaches have their own special ways of breaking.
NFD configuration issues prevent automatic GPU detection. NFD must be configured to detect PCI devices and NVIDIA vendor IDs:
## Correct NFD worker configuration for GPU detection
apiVersion: v1
kind: ConfigMap
metadata:
name: nfd-worker-conf
namespace: node-feature-discovery
data:
nfd-worker.conf: |
sources:
pci:
deviceClassWhitelist:
- "03" # Display controllers (GPUs)
- "12" # Processing accelerators
deviceLabelFields:
- vendor
- class
- subsystem_vendor
custom:
- name: "nvidia-gpu"
matchOn:
- pciId:
vendor: "10de" # NVIDIA vendor ID
Manual labeling mistakes - when NFD doesn't work, you label nodes manually. Easy to fuck up, easy to forget, easy to have inconsistent labels across nodes:
## Verify GPU node labels
kubectl get nodes -o custom-columns=NAME:.metadata.name,GPU:.metadata.labels.'nvidia\.com/gpu',FAMILY:.metadata.labels.'nvidia\.com/gpu\.family'
## Add missing labels
kubectl label nodes gpu-node-1 nvidia.com/gpu=present
kubectl label nodes gpu-node-1 nvidia.com/gpu.family=tesla
kubectl label nodes gpu-node-1 accelerator=nvidia-tesla-v100
Resource Advertisement and Kubelet Integration
The kubelet must successfully register GPU resources from the device plugin. Integration failures prevent resource allocation even when GPUs are detected correctly.
Device plugin socket communication breaks when Unix domain sockets have permission issues or the kubelet can't connect:
## Check device plugin socket registration
ls -la /var/lib/kubelet/device-plugins/
## Should show nvidia.sock with proper permissions
## Verify device plugin registration in kubelet logs
kubectl logs -n kube-system kubelet-gpu-node-1 | grep -i "device plugin\|nvidia"
Resource allocation limits in kubelet configuration can block GPU registration. The kubelet must be configured to handle extended resources:
## Kubelet configuration for GPU support
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
DevicePlugins: true
Actually Debugging Device Plugin Issues (Not Just Guessing)
Stop randomly changing config files. Here's the systematic debugging approach that actually works - check these in order and stop when you find the broken piece:
## 1. Is the hardware even there?
kubectl debug node/gpu-node-1 -it --image=busybox
## In debug pod: lspci | grep -i nvidia
## 2. Do the drivers work?
kubectl debug node/gpu-node-1 -it --image=nvidia/cuda:12.3-runtime-ubuntu22.04
## In debug pod: nvidia-smi
## 3. Is the device plugin running? (probably not)
kubectl get pods -n gpu-operator -l app=nvidia-device-plugin-daemonset
kubectl logs -n gpu-operator nvidia-device-plugin-daemonset-xxx
## 4. Can Kubernetes see GPUs? (spoiler: no)
kubectl describe nodes gpu-node-1 | grep -A 5 -B 5 "nvidia.com/gpu"
## 5. Nuclear option - try to run something with GPUs
kubectl run gpu-test --image=nvidia/cuda:12.3-runtime-ubuntu22.04 --restart=Never --rm -it --limits=nvidia.com/gpu=1 -- nvidia-smi
This will tell you exactly where things are broken. Don't randomly change configs - fix the specific problem you find.
Once device discovery works, you get to deal with the scheduler being unable to actually allocate the GPUs it can see. Different category of pain.