Look, I'm going to level with you: getting llama.cpp compiled is a fucking nightmare that nobody warns you about. Half the tutorials online skip the part where everything breaks because their authors never actually tried it on a real system. Here's what actually happens when you follow their "simple" instructions.
The "Easy" Ways (That Sometimes Work)
Pre-built Binaries (Just Download These, Trust Me)
Download from GitHub releases. This is your safest option because someone else already suffered through the compilation hell so you don't have to.
- Windows: Download the .exe, might work out of the box
- macOS: Download the binary, pray Apple's security theater doesn't block it
- Linux: Download and pray your glibc version matches what they compiled against
Package Managers (When They Don't Hate You):
## macOS - actually works most of the time
brew install llama.cpp
## Windows - maybe works
winget install ggml-org.llama.cpp
## Arch Linux - probably broken
yay -S llama-cpp-git # Good luck
## Ubuntu/Debian - doesn't exist in main repos, use PPA or compile
Docker (The Nuclear Option):
## CPU only - works reliably
docker run -it --rm -v /path/to/models:/models ggml-org/llama-server
## GPU support - NVIDIA drivers must be perfect
docker run --gpus all -it --rm -v /path/to/models:/models ggml-org/llama-server
Compilation From Source (Where Dreams Go to Die)
Building from source gives you the best performance, assuming you survive the process. Here's what the happy path looks like and what actually happens:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
mkdir build && cd build
## Basic CPU build (the \"safe\" option)
cmake .. && make -j$(nproc)
## This will probably work. Probably.
GPU Acceleration (Welcome to Hell)
NVIDIA CUDA (Abandon Hope):
## This is what the docs say:
cmake .. -DGGML_CUDA=ON && make -j$(nproc)
## What actually happens:
## Error: CUDA not found
## Error: nvcc: command not found
## Error: identifier \"__builtin_dynamic_object_size\" is undefined
## Error: ambiguous half type conversions
## After 3 hours of Googling:
sudo apt install nvidia-cuda-toolkit # Downloads 2GB
cmake .. -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=\"80;86\" && make -j$(nproc)
## Still breaks because your driver version doesn't match CUDA version
I've been burned by CUDA bullshit three times just this year:
- CUDA 12.0 with driver 550: Spent my entire Saturday debugging mysterious compilation errors - turns out driver 550.78 is cursed (found this out from a random Stack Overflow comment with 3 upvotes)
- Ubuntu 24.04 upgrade: Broke my perfectly working setup at 1am before a demo. Had to reinstall the entire CUDA toolkit from scratch while the client was on Zoom
- WSL2: Works great for a month, then randomly breaks after a Windows update. I've stopped trying to understand why Microsoft hates developers
cmake .. -DGGML_METAL=ON && make -j$(nproc)
## This actually works most of the time because Apple controls the stack
Vulkan (The New Way to Suffer)
cmake .. -DGGML_VULKAN=ON && make -j$(nproc)
## Will fail with shaderc v2025.2 - this breaks with newer shaderc versions
## Need to downgrade shaderc or disable bfloat16 support
## \"Invalid capability operand: 5116\" <- you'll see this error
Check the Vulkan build documentation for the latest known issues and Vulkan SDK requirements.
Getting Models (The Fun Part)
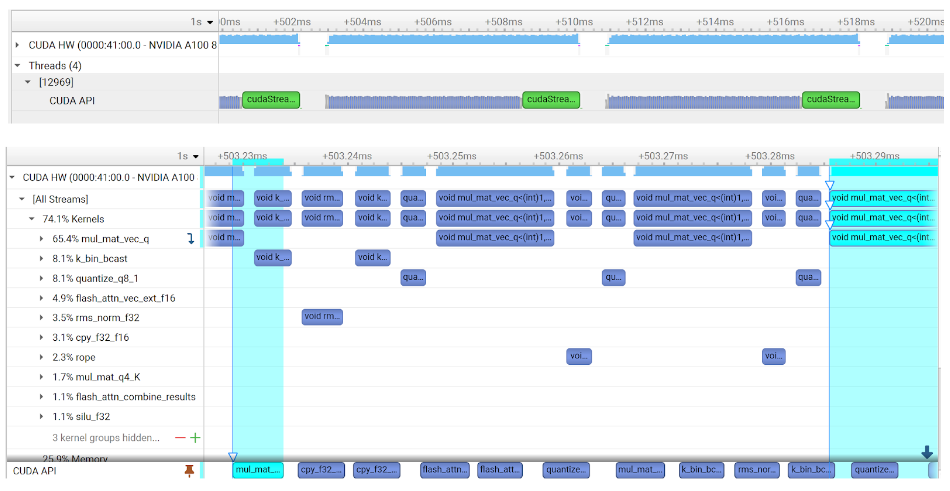
GPU profiling shows where CUDA optimization kicks in - basically eliminates the gaps that slow everything down
You need models in GGUF format. Don't try converting from scratch unless you enjoy pain.
Download Pre-converted Models (Do This)
## From Hugging Face - thousands of models already converted
## Search: huggingface.co/models?library=gguf&sort=trending
wget https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q4_0.gguf
## Or use the built-in downloader (when it works):
./llama-cli --hf-repo TheBloke/Llama-2-7B-Chat-GGUF --hf-file llama-2-7b-chat.Q4_0.gguf
Check TheBloke's collection for the best pre-quantized models, or browse Microsoft's GGUF models for enterprise-grade options.
Model Conversion (When You Hate Yourself)
## This looks simple but will break in creative ways:
python convert_hf_to_gguf.py /path/to/model --outfile model.gguf
./llama-quantize model.gguf model_q4_0.gguf Q4_0
## Common failures:
## \"No module named 'torch'\" - install PyTorch first
## \"CUDA out of memory\" - model too big for your GPU during conversion
## \"Unsupported model architecture\" - model too new or weird
For conversion help, check the conversion documentation and quantization guide.
Actually Running It (Cross Your Fingers)
Simple Test (Start Here)
./llama-cli -m model.gguf -p \"The capital of France is\" -n 50
## Should output \"Paris\" if everything works
## Will output garbage or crash if something's wrong
Interactive Chat
./llama-cli -m model.gguf -cnv
## Type messages, model responds
## Ctrl+C to quit (sometimes works)
Server Mode (For Real Applications)
./llama-server -m model.gguf --host 0.0.0.0 --port 8080
## Web UI available at localhost:8080
## OpenAI-compatible API at /v1/chat/completions
The llama.cpp server provides a clean web interface for interacting with models, plus an OpenAI-compatible API for integration with existing applications.
CPU Settings
## Use most of your CPU cores (but not all - system needs some)
./llama-cli -m model.gguf -t 12 -p \"test\"
## Lock model in memory (prevents swapping death spiral)
./llama-cli -m model.gguf --mlock -p \"test\"
GPU Settings (The Tricky Part)
## Offload layers to GPU (-ngl = number of GPU layers)
./llama-cli -m model.gguf -ngl 32 -p \"test\"
## Start with -ngl 10, increase until you run out of VRAM
## Too high = CUDA_ERROR_OUT_OF_MEMORY and everything stops
## Too low = GPU sits idle while CPU struggles
- Memory swapping: Model bigger than RAM = death spiral
- Wrong thread count: Too many threads = slower than fewer threads
- Thermal throttling: Laptop gets hot, CPU slows down, tokens/sec drops
- Background apps: Chrome eating RAM while you're trying to run a 13B model
When Everything Fails
"It worked yesterday, now it's broken" (My every Tuesday morning)
- Try a different model first (maybe your model file got corrupted) - saved me 2 hours of debugging once when the real problem was a half-downloaded 13GB file
- Restart everything and try again (fixes 30% of issues) - I hate that this works but it does
- Check if GPU drivers updated overnight - Windows Update strikes again, every fucking time, usually during the worst possible moment
- Delete build directory, recompile from scratch (nuclear option) - I've done this 6 times and stopped feeling guilty about it
"CUDA_ERROR_OUT_OF_MEMORY"
- Lower
-ngl value (use less GPU layers)
- Use smaller quantization (Q4_0 instead of Q8_0)
- Close Chrome (seriously, it's probably using 8GB)
- Restart computer (clears GPU memory leaks)
"Segmentation fault" or Random Crashes
- Check model file integrity (redownload if needed)
- Lower thread count (-t 4 instead of -t 16)
- Try different quantization format
- Accept that some models are just cursed
