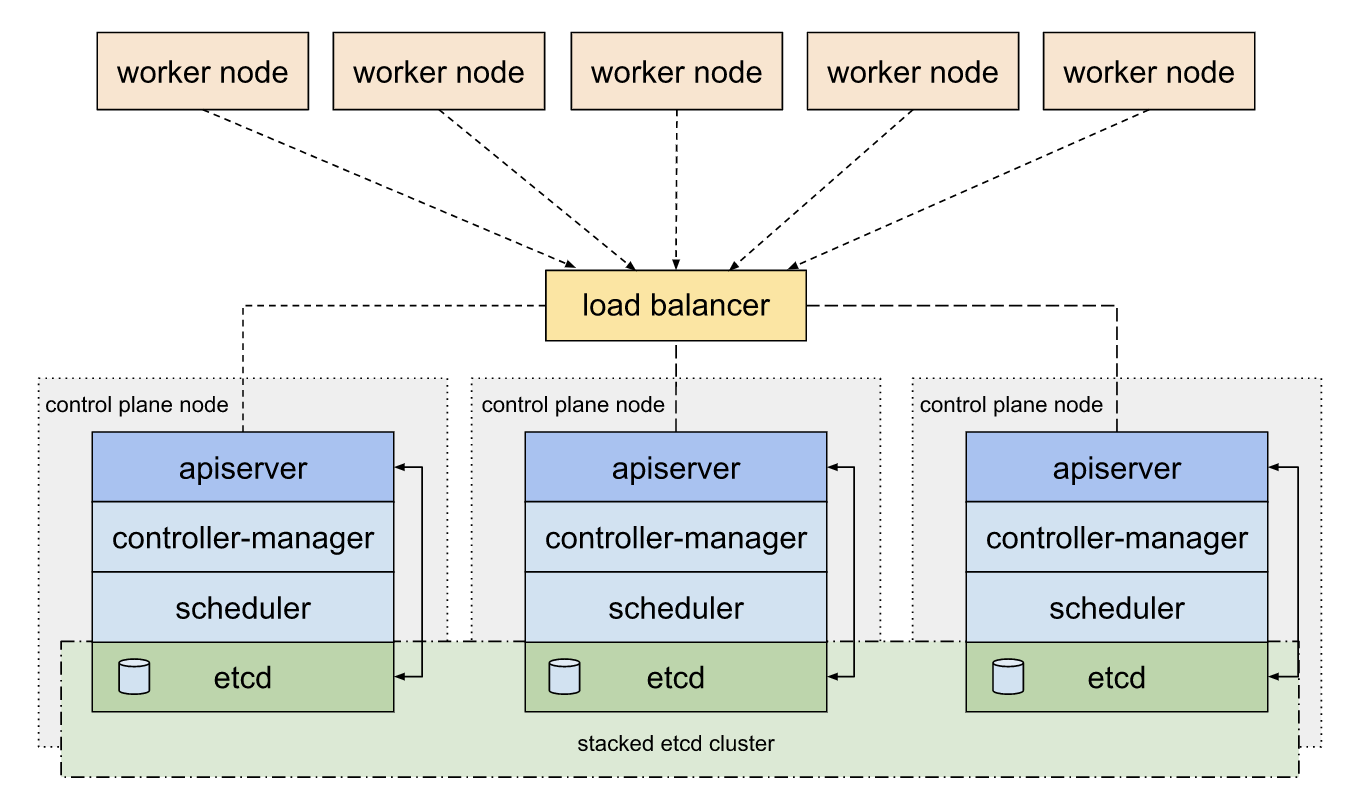
When everything catches fire at 3 AM and you get 47 Slack notifications in 30 seconds, the first thing you need to figure out is whether a single pod shat the bed or your entire cluster just decided to take a vacation. This isn't theoretical - get this wrong and you'll waste hours debugging the wrong shit while your manager breathes down your neck.
Here's what this section will teach you: How to perform the critical 60-second assessment that determines whether you're dealing with a manageable component failure or a cluster-wide catastrophe that requires the nuclear option. You'll learn the exact commands to run, the warning signs that indicate cascade potential, and the real-world failure patterns that have fucked over major companies. Most importantly, you'll understand how to avoid the most common mistake: debugging symptoms instead of causes.
The Difference Between Component Failures and Cluster Outages
Component failures are the Tuesday afternoon kind of broken. One service is acting up, maybe a deployment is stuck, you can still run kubectl commands and your standard debugging techniques work fine.
Cluster-wide outages are the "wake up the entire dev team at 3 AM" kind of fucked. Nothing works, kubectl just hangs, and you're about to discover that your backup plan wasn't as good as you thought.
Immediate Triage: The 60-Second Assessment
Signs of Cluster-Wide Outage
Control Plane Symptoms:
- `kubectl` commands timeout or return "connection refused"
- Multiple unrelated services simultaneously become unreachable
- Kubernetes Dashboard or monitoring tools can't connect to the cluster
- All new deployments fail across different namespaces
- Ingress controllers return 503 errors for ALL applications
Quick verification commands:
## Test cluster connectivity (30-second timeout)
kubectl get nodes --request-timeout=30s
## Check control plane component status
kubectl get componentstatuses
## Verify API server health from outside the cluster
curl -k https\://10.0.1.100:6443/healthz
## Replace 10.0.1.100 with your actual API server endpoint IP
## Common errors: \"connection refused\", \"context deadline exceeded\", \"x509: certificate signed by unknown authority\"
If these basic commands fail or hang, you're dealing with a cluster-wide issue.
Signs of Component-Level Issues
kubectl get nodesworks normally- Some services work while others don't
- Problems are confined to specific namespaces or applications
- System pods in kube-system namespace are healthy
- You can deploy test workloads successfully
Real-World Production Outage Patterns
IP Exhaustion: The Silent Cluster Killer
Here's how we got fucked completely: our cluster looked totally fine - kubectl get nodes was green, existing pods just humming along like nothing was wrong. But we couldn't deploy anything new and it took like 45 minutes of head-scratching before we found the real problem.
Here's what was actually happening:
- AWS CNI ran out of IPs in our subnets (classic EKS gotcha that bites everyone eventually)
- New pods just sat there
Pendingforever with some bullshit "insufficient resources" message - Existing stuff kept working fine, so our monitoring was all green (which made this extra painful)
- Control plane was completely healthy, so we kept looking in all the wrong places first
kubectl describe podeventually showed "no available IP addresses" but it was buried in like 50 lines of other garbage
Why this was extra fucking painful:
- All our dashboards were green because existing pods were fine
- We wasted 30 minutes assuming it was a scheduler problem (wrong)
- The actual error was buried deep in AWS CNI logs that we never check
- Autoscaling just... stopped working, so the next traffic spike killed us
- Took forever - felt like hours but was probably 45 minutes of actual work and a lot of head-scratching
The brutal lesson: Partial outages are the absolute worst because they trick you into debugging the wrong shit first. Half your users are screaming, the other half haven't noticed, and you're chasing ghosts.
The Spotify \"Oops I Deleted Production\" Chronicles
Spotify fucked up their Terraform and accidentally deleted everything during what was supposed to be a routine change. Took them hours to recover because, surprise, they didn't have proper backups of their K8s configs.
What that looks like:
kubectlsuddenly returns "cluster not found"- Your entire monitoring dashboard goes blank in seconds
- No gradual degradation, no warning signs - everything just stops existing
- The GCP console shows empty where your cluster used to be
Only reason it wasn't completely fucked: Spotify had failover systems that weren't running on Kubernetes. But if K8s was your only infrastructure? You're done.
What made it worse: I bet they had three different people trying to fix it at the same time, probably making it worse. Recovery is messy when everyone panics.
The Monzo Banking Kubernetes Bug That Ate Production (2017)
Monzo got completely fucked by some old Kubernetes bug that took down their entire cluster for over an hour. Customer payments just stopped working.
What went sideways:
- A dormant K8s bug triggered during routine operations
- Control plane components started failing in a cascade
- New pods couldn't schedule, existing ones started dying
- Payment processing completely stopped - bank customers couldn't move money
Why it was extra painful:
- No gradual degradation - the cluster just shit the bed all at once
- Their monitoring couldn't help them diagnose a bug in Kubernetes itself
- Recovery required rebuilding the cluster while customers were locked out of their bank accounts
- The post-mortem revealed multiple failure points happening simultaneously
The brutal lesson: Even mature platforms like Kubernetes can have deep bugs that only surface when all the wrong things happen at once. And when they do, there's no "quick fix" - you're rebuilding from scratch.
The DNS Cascade: When Everything Breaks Because Nothing Can Talk
Here's the nightmare scenario that'll keep you up at night: your control plane gets unstable and DNS stops working. Suddenly even your healthy apps can't function because they can't resolve basic service names. Render learned this the hard way in 2022.
How it goes to hell:
- Something triggers etcd stress (memory spike, network hiccup, whatever)
- API server starts choking (timeouts, slow responses, general misery)
- CoreDNS pods die but can't restart because API server is fucked
- Everything else dies because nothing can resolve DNS anymore
It's simple and completely devastating. Your dashboard goes completely red.
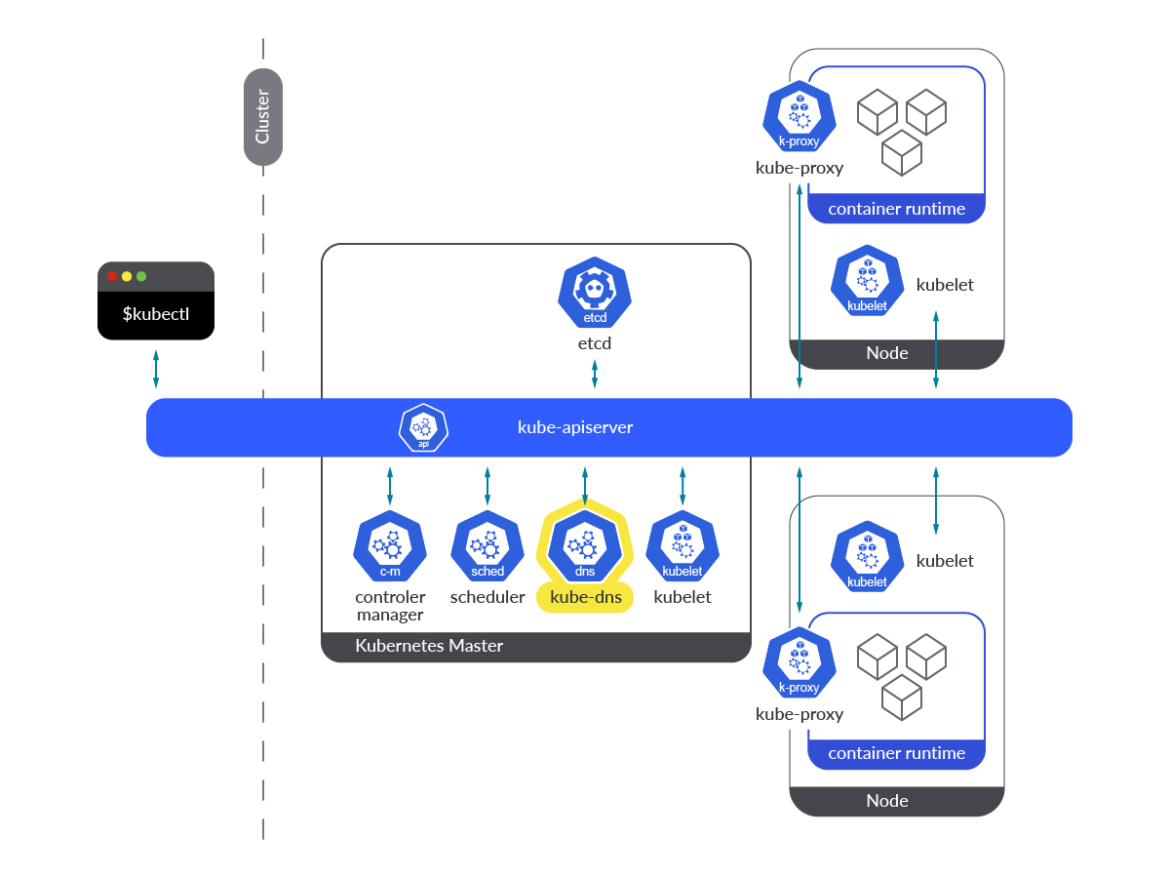
Detection commands:
## Check if DNS is working from within pods
kubectl exec -it <any-running-pod> -- nslookup kubernetes.default
## Verify CoreDNS pod health
kubectl get pods -n kube-system -l k8s-app=kube-dns
## Test API server DNS resolution
kubectl exec -it <pod> -- nslookup kubernetes.default.svc.cluster.local
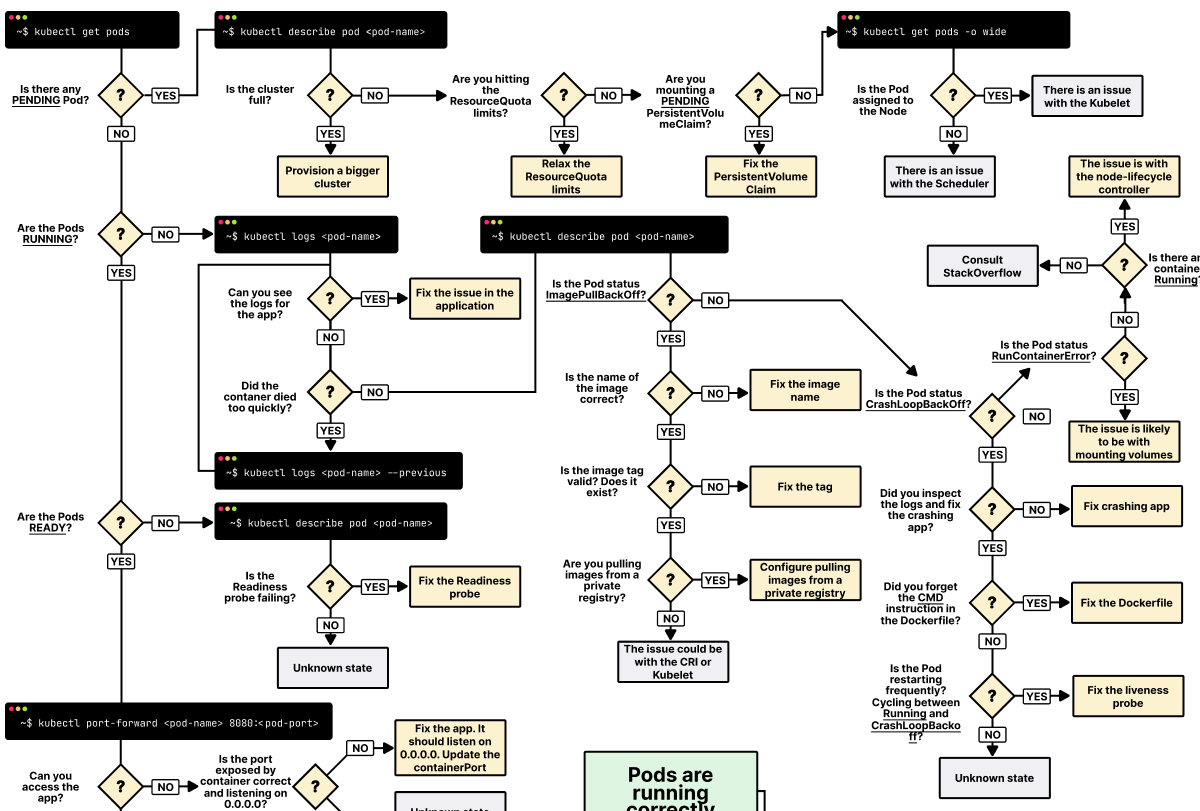
The \"Is Everything Actually Fucked?\" Decision Tree
Step 1: Can you even run kubectl without it hanging?
YES → Great, run kubectl get nodes and kubectl get pods --all-namespaces right now
- All green and mostly running? → It's probably just one service being a pain in the ass
- Nodes showing NotReady or tons of Pending pods? → Your infrastructure is having a bad time
- Weird mixed status everywhere? → Something is cascading and it's about to get worse
NO → Your control plane is dead, Jim
- Try kubectl from a different machine/network (maybe it's just your connection)
- Check AWS/GCP/Azure status pages (maybe it's not your fault)
- SSH directly to control plane nodes if you can (spoiler: you probably can't)
SORT OF → kubectl works but your apps are returning 500s everywhere
- DNS is probably fucked (check CoreDNS pods)
- Your ingress controller might be dead
- Load balancers could be routing traffic to nowhere
What to Actually Do When Everything is on Fire
First 5 minutes (while you're still panicking):
- Wake everyone up: Post in #incidents, page the on-call team, text your manager
- Check if it's not your fault: AWS status, GCP status, whatever cloud you're using
- Try kubectl from different places: Your laptop, a server, a different VPN - rule out network issues
- Screenshot everything: Trust me, you'll forget what the error messages looked like
Next 10 minutes (when the adrenaline kicks in):
- Figure out what's actually broken: Is it just you? Just one region? Everything?
- Hit the big red button: If you have backup infrastructure, start failing over NOW
- Start collecting evidence: Control plane logs, cloud events, anything that might be useful
- Update the war room: Keep people informed so they stop asking "what's the status?"
The hard truth: Those first 15 minutes determine whether your outage becomes a minor incident or a career-defining disaster. The difference isn't technical skill - it's having a systematic approach that works under pressure and knowing exactly which questions to ask first. Every minute you spend debugging the wrong thing is another minute of customer-facing downtime and another thousand dollars in lost revenue.
The systematic recovery procedures in the following sections will walk you through the exact steps for different failure scenarios, from simple etcd hiccups to complete cluster destruction. But none of it matters if you don't correctly diagnose what type of outage you're dealing with first.