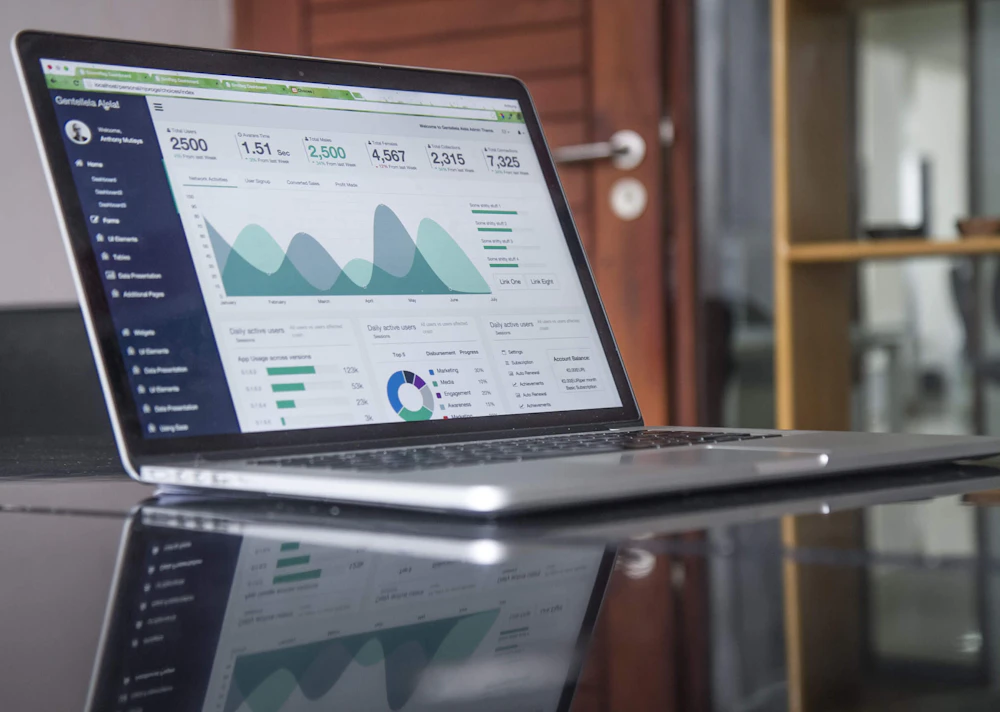
Look, every database vendor talks about being "serverless" these days. But I've run production systems on all of these, and I'll save you the suspense: only one actually delivers on the promise.
DynamoDB: Actually Built for This
🗄️ DynamoDB: The True Serverless Option
DynamoDB is the only database in this comparison designed from day one for serverless workloads. When AWS says "zero administration," they mean it. You literally cannot access the underlying servers - they don't exist from your perspective.
AWS Finally Cut DynamoDB Prices (About Fucking Time): AWS reduced DynamoDB on-demand pricing by 50% in late 2024. Took them long enough - we were getting murdered on costs. This actually makes DynamoDB competitive with managed PostgreSQL, which nobody saw coming. Catch? You still gotta wrap your head around single-table patterns that'll make SQL developers cry.
Real-world serverless performance: DynamoDB handles traffic spikes from 10 requests per second to 40,000 requests per second without any configuration changes. The auto-scaling is transparent - you see the cost increase in your bill, not downtime in your monitoring dashboard.
The DynamoDB tax: Single-table design patterns require rethinking your entire data model. SQL joins become application logic. Transactions are limited to 25 items across 4MB. If your data model requires complex relationships, DynamoDB becomes painful fast.
Aurora Serverless: PostgreSQL/MySQL with Training Wheels

☁️ Aurora: Serverless with Asterisks
Aurora Serverless v2 (finally fucking stable as of mid-2024) tries to make PostgreSQL and MySQL serverless. It auto-scales between 0.5 and 128 ACUs (Aurora Capacity Units), with each ACU representing roughly 2GB of memory and corresponding CPU.
The scaling reality: Aurora takes way too long to scale when you actually need it. We hit the front page of HN and the first wave of users got connection timeouts while Aurora was still figuring out if it needed more capacity. Took maybe half a minute which might as well be forever when your site's blowing up.
Cost structure: Aurora Serverless runs around a dollar per ACU-hour, but the billing gets weird fast. Our database bill started somewhere around $2,500/month, now we're pushing $4k and honestly not sure why. Could be background jobs keeping the thing warm, or maybe all those read replicas we forgot about. The "pay only when active" promise is marketing bullshit when you've got cron jobs running constantly.
PostgreSQL on Aurora: I'm running PostgreSQL 17 and it's been solid. Aurora gives you the latest versions plus whatever extensions you need - pg_vector if you're doing AI stuff. Way faster than regular RDS, like 3x better, but you pay for it.
MySQL on Aurora: Less compelling unless you're stuck with legacy MySQL. If you're starting fresh, just use PostgreSQL.
MongoDB Atlas: NoSQL Serverless (With Asterisks)

🍃 MongoDB: NoSQL with Expensive Scaling
MongoDB Atlas Serverless launched with great fanfare but has strict limitations that make it unsuitable for production workloads above toy scale. The 1TB storage limit and connection throttling hit faster than you'd expect.
Atlas pricing is a trap: M10 instances are completely useless for anything real - like $57/month to host a glorified to-do app. Production requires M30+ and we're paying something like $1,200/month with backups and monitoring. Maybe more now, I stopped looking at the MongoDB line item because it just makes me angry.
Performance improvements: The latest MongoDB is supposedly faster, but it requires WiredTiger cache tuning that nobody on my team wants to deal with. Atlas handles this automatically, which is nice, but you're paying a premium for that hand-holding.
Scaling reality: MongoDB sharding works well for write scaling but introduces operational complexity. Choosing the wrong shard key is a permanent mistake - you cannot change it without a full migration. Atlas makes sharding easier but doesn't eliminate the fundamental data modeling challenges.
Cassandra: Distributed by Design, Serverless by Accident

💍 Cassandra: The Ring Architecture
Cassandra's latest version with SAI (Storage-Attached Indexes) finally lets you do multi-column queries without the traditional "model your data for your queries" nightmare. This makes Cassandra slightly less insane for regular developers.
DataStax Astra DB provides the closest thing to "serverless Cassandra." You get the linear scaling and fault tolerance of Cassandra without managing JVM heap sizes or compaction strategies. Pricing starts at $0.10 per read/write operation with a $25 minimum monthly charge.
Serverless characteristics: Cassandra naturally scales horizontally without downtime. Adding nodes increases capacity linearly. The architecture is inherently "serverless" in that no single node is special - lose any node and the cluster continues operating.
The complexity trade-off: Even with Astra DB, you still need to understand Cassandra's data modeling patterns. Consistency levels, partition keys, and tombstone accumulation remain operational concerns. This isn't "zero administration" like DynamoDB.
PostgreSQL and MySQL: Server-Based Thinking in Serverless Clothes


🐘 PostgreSQL & MySQL: Old School Reliability
Traditional PostgreSQL/MySQL deployment patterns don't translate well to serverless architectures. Connection pooling, read replicas, and manual scaling decisions require traditional database administration skills.
Managed options improve the story:
- **Amazon RDS Proxy** helps with connection pooling for Lambda functions
- **Google Cloud SQL** offers automatic scaling for read replicas
- **Azure Database for PostgreSQL** provides built-in connection pooling
Connection limits still bite: PostgreSQL defaults to 100 concurrent connections. Each Lambda execution creates a database connection. Under load, you'll hit connection limits and get "FATAL: sorry, too many clients already" - PostgreSQL's way of saying "fuck you, scale better."
Learned this one the hard way during our product launch when everything went to shit at once. Had like 400+ Lambdas or some crazy number all trying to connect at once - everything went to shit simultaneously. Still have PTSD from that 'FATAL: sorry, too many clients' error message. RDS Proxy helps but adds latency and costs $0.015/hour per connection.
Also had some weird connection pooling issue during migration where connections would just... disappear? Took us 3 hours on Stack Overflow to figure out it was some timeout setting nobody knew about.
Current reality:
- PostgreSQL: Works great, latest version has better performance
- MySQL: Fine if you're stuck with it
- Both offer JSON columns for flexible schemas
- Neither offers true auto-scaling without rethinking your architecture
The Real Serverless Database Decision Matrix
Choose DynamoDB if:
- Your application can work with NoSQL patterns
- Traffic is unpredictable (spiky or seasonal)
- You want true zero administration
- Budget predictability matters less than operational simplicity
Choose Aurora Serverless if:
- You need complex SQL queries and relationships
- Your team knows PostgreSQL/MySQL already
- You can tolerate 15-30 second scaling delays
- Budget allows for $3,000+ monthly database costs
Choose MongoDB Atlas if:
- Your data model fits document patterns naturally
- You need rapid development with schema flexibility
- Your team prefers NoSQL query patterns
- You're building content management or catalog systems
Choose Cassandra/Astra if:
- You need massive write throughput (100k+ ops/sec)
- Global distribution is required
- Eventual consistency is acceptable
- You have time-series or IoT data
Choose traditional PostgreSQL/MySQL if:
- "Serverless" is marketing fluff for your use case
- You need predictable performance and costs
- Your workload is steady-state with known patterns
- You have existing database administration expertise
What "Serverless" Actually Costs in 2025
💰 The Real Cost Story
The pricing models vary dramatically, and the marketing numbers don't reflect real-world costs:
DynamoDB: Our bill runs around $200/month but jumped to $800 when we got featured somewhere. Then went back down. Then spiked again for no fucking reason. Hard to predict.
Aurora Serverless: Started at $2,500/month, now we're at $4k and honestly not sure why.
MongoDB Atlas: M10 instances are useless for anything real. We're paying around $1,200/month with backups and monitoring - I think? Could be $1,500 by now, I stopped looking at the bill.
Cassandra Astra: $25 minimum monthly but scales with usage. Good if you have high transaction volumes, expensive for typical web apps.
Traditional managed databases: RDS PostgreSQL starts around $200/month but you need read replicas and monitoring to match what the serverless options give you automatically.
The hidden costs include data transfer (can double your bill), backup storage, monitoring tools, and the engineering time spent on database operations versus application development.
But understanding costs is only half the battle. The real test comes when you need to migrate between these systems - which is when most companies realize they're completely fucked.