Prisma finally stopped being incompetent. The latest versions shipped the Rust-free architecture that should have been the original design. Only took them 3 years to realize their Rust experiment was a dead end.
![]()
Why Prisma Almost Died
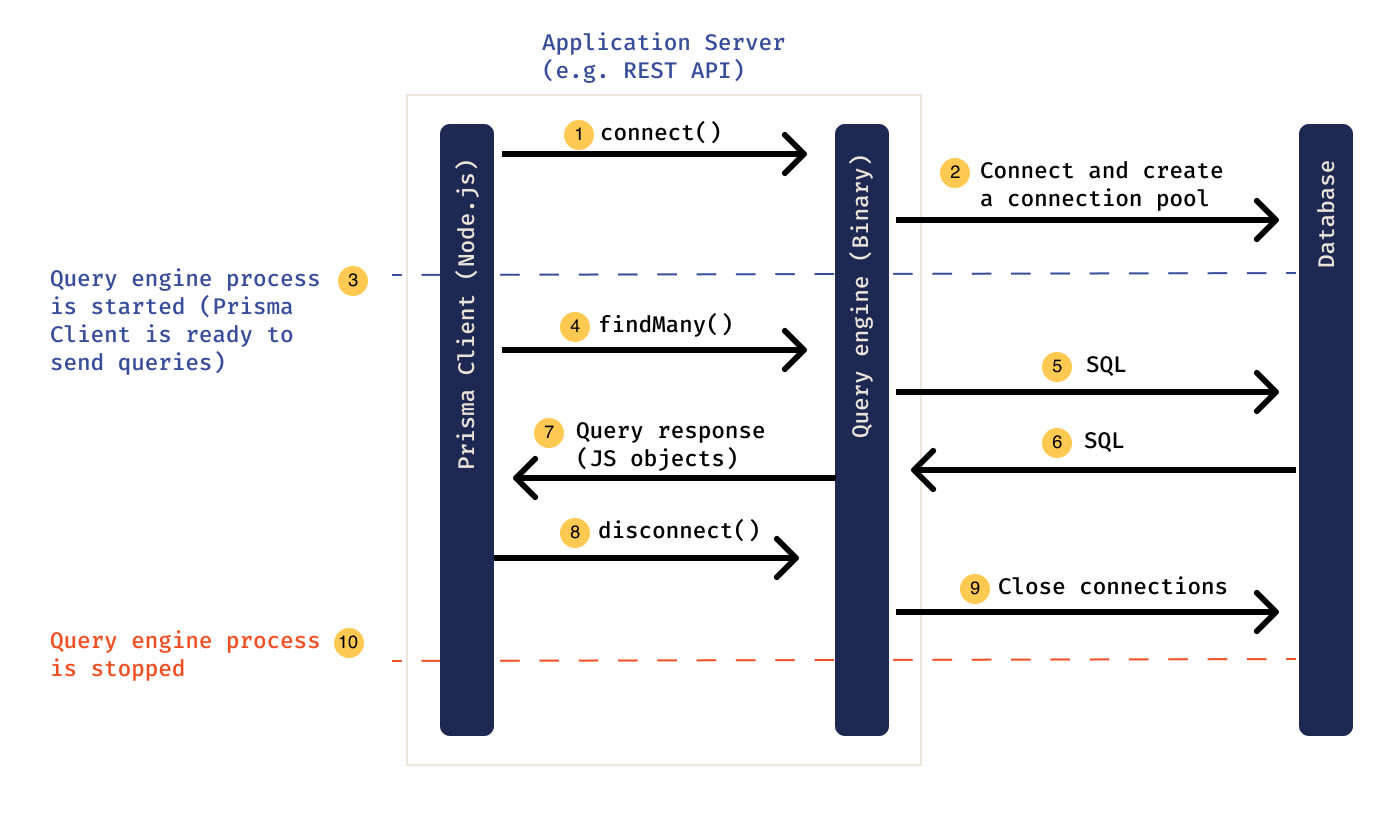
The Rust engine was supposed to be fast. Instead I got serialization overhead on every damn query. Rust's speed didn't matter when you're wasting cycles converting data between TypeScript and Rust on every single database call. Some recent versions had memory issues that killed our staging environment twice.
What broke in production:
- Bundle size: Binary was huge - killed our Lambda deployments, cold starts took forever
- Query overhead: Every query paid serialization costs
- Platform issues: ARM64 vs x86 binaries broke our CI/CD pipeline multiple times
- Docker problems: Different container architectures meant different binaries
Benchmark Results: The Numbers Don't Lie
I ran benchmarks myself because I don't trust marketing numbers. Here's what I'm seeing in my own testing:
Large Dataset Queries (Where You Actually Notice):
findManyon large datasets: way faster - used to be painfully slow, now it's actually usable- Complex joins with includes: this was brutal before - used to take forever, now it's reasonable
- Filtered queries with relations: way better - probably cut our API response times significantly
Bundle Size Revolution:
- Old Rust engine: insanely huge - something like 14MB, maybe more
- New TypeScript engine: way smaller - around 1.5MB I think? Still big but deployable
- Result: massive reduction, went from "this is insane" to "ok I can live with this"
How They Actually Fixed It
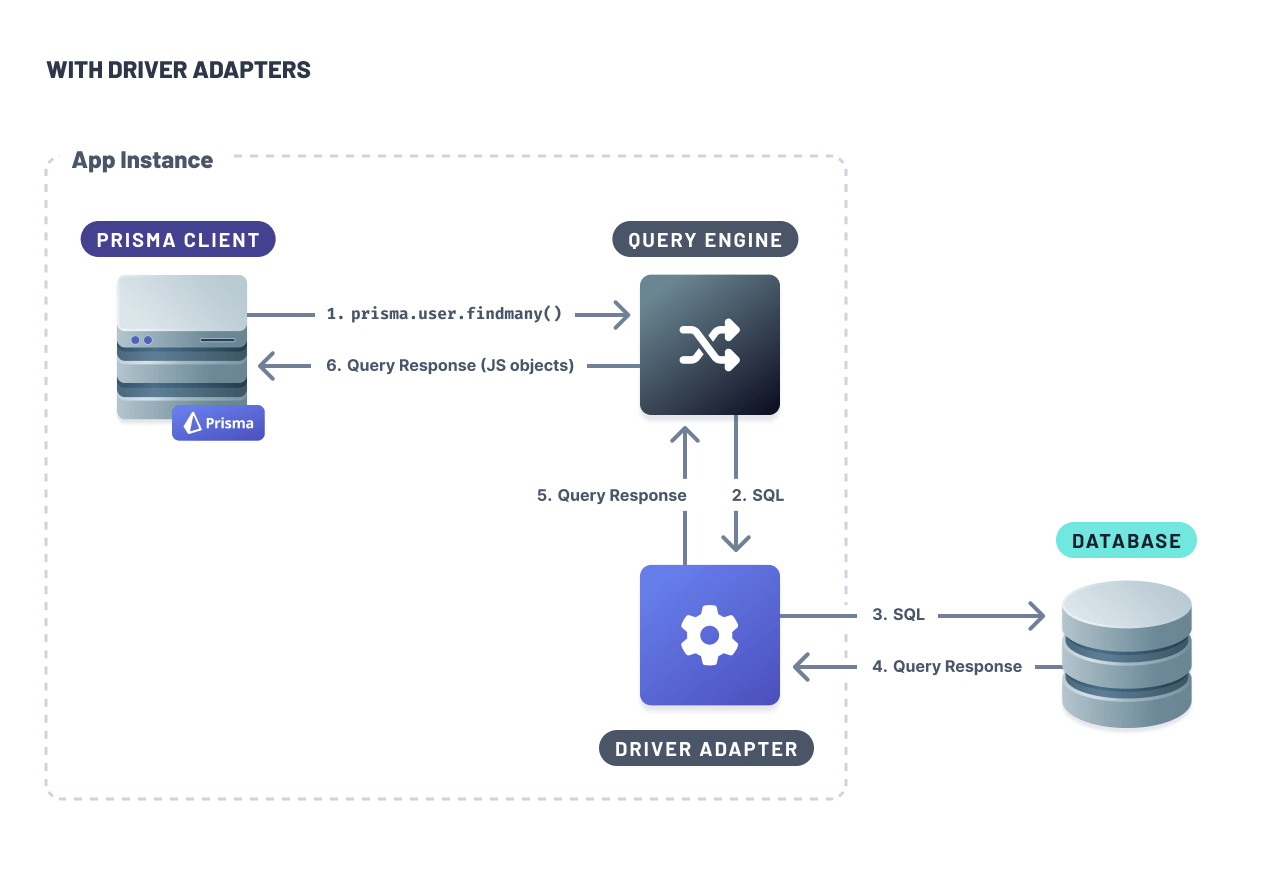
Here's how they fixed their garbage architecture:
Before: your TypeScript had to talk to a separate Rust process, which was slow as hell and meant every query paid serialization costs.
After: everything's in TypeScript now, no more cross-language overhead. They use a lean WASM module for query planning but keep all execution in JavaScript land.
The magic is eliminating that serialization step - no more converting data back and forth between TypeScript and Rust on every single database call.
Real-World Impact for Production Apps
Serverless Actually Works Now:
Our Lambda cold starts were a complete nightmare - sometimes they'd just timeout, product team was constantly bitching about it. After the migration, they're actually reasonable now. Still not great, but at least deployable.
CPU Usage Dropped:

Killed that separate Rust process that was eating CPU in the background. Our monitoring shows way lower baseline CPU usage. AWS bill went down noticeably, maybe like 15-20% or something.
Developer Experience:
- Faster builds (no binary compilation)
- Simplified Docker deployments
- Better monorepo compatibility
- Easier open-source contributions (TypeScript vs Rust barrier)
- No more cross-compilation issues in CI/CD
- Better debugging experience with source maps
Migration Path to High Performance
Here's how to ditch the Rust engine:
- Update your schema generator (takes 5 seconds):
generator client {
provider = \"prisma-client\"
engineType = \"client\" // This is the magic line
}
- Install the driver adapter (another 30 seconds):
npm install @prisma/adapter-pg # PostgreSQL
npm install @prisma/adapter-mysql # MySQL
npm install @prisma/adapter-sqlite # SQLite
- Update your client code (the part that might break shit):
import { PrismaClient } from '@prisma/client'
import { PrismaPg } from '@prisma/adapter-pg'
import pg from 'pg'
// You need to instantiate the pool yourself now
const pool = new pg.Pool({ connectionString: DATABASE_URL })
const adapter = new PrismaPg(pool)
const prisma = new PrismaClient({ adapter })
Just Benchmark Your Shit
Test Before You Migrate:
Performance gains depend completely on what you're doing. Large datasets get way faster, simple queries barely change. Don't trust the marketing - run your actual workload with Artillery or k6 before and after.
Key Metrics to Track:
- Query response times (especially for large result sets)
- Bundle size impact on deployment time
- Cold start performance in serverless environments
- CPU utilization under load using APM tools
- Memory consumption patterns with Node.js profiling
- Connection pool utilization via database monitoring
What This Means for Competition
So now Prisma doesn't completely suck compared to other ORMs. Benchmarks show it can actually compete with Drizzle now on TypeScript compilation, which was another thing people bitched about.
The New Performance Landscape:
- Drizzle: Still wins on absolute bundle size (~7KB) and raw SQL control
- Prisma: Now competitive on query performance with superior DX
- TypeORM: Legacy performance profile unchanged, decorator overhead remains
- Raw SQL: Still fastest but at cost of type safety and DX
- Kysely: Type-safe SQL builder alternative gaining traction
- MikroORM: Data mapper pattern with good performance
What This Actually Means
Prisma finally fixed their shit. The Rust-free architecture is the default now and it actually works.
If you've been avoiding Prisma because it was slow garbage, those problems are mostly fixed. Now it's just about whether you want the nice DX or prefer something lighter like Drizzle.