Why I Keep Doing This Migration
Look, MySQL pissed me off one too many times. After 4 years of babysitting production databases, PostgreSQL just works better. PostgreSQL 16 dropped in September 2023 and fixed the JSON indexing shit that kept breaking our product search. The official PostgreSQL 16 announcement covers all the performance improvements, while this migration guide from 2025 provides current best practices.
Here's why I finally said "fuck this" and migrated our e-commerce platform's 47GB inventory database last year (maybe 52GB? I stopped counting after the third disk expansion):
MySQL kept breaking on us:
- JSON queries were garbage - MySQL's JSON implementation couldn't handle our product catalog searches efficiently (PostgreSQL JSONB performance analysis)
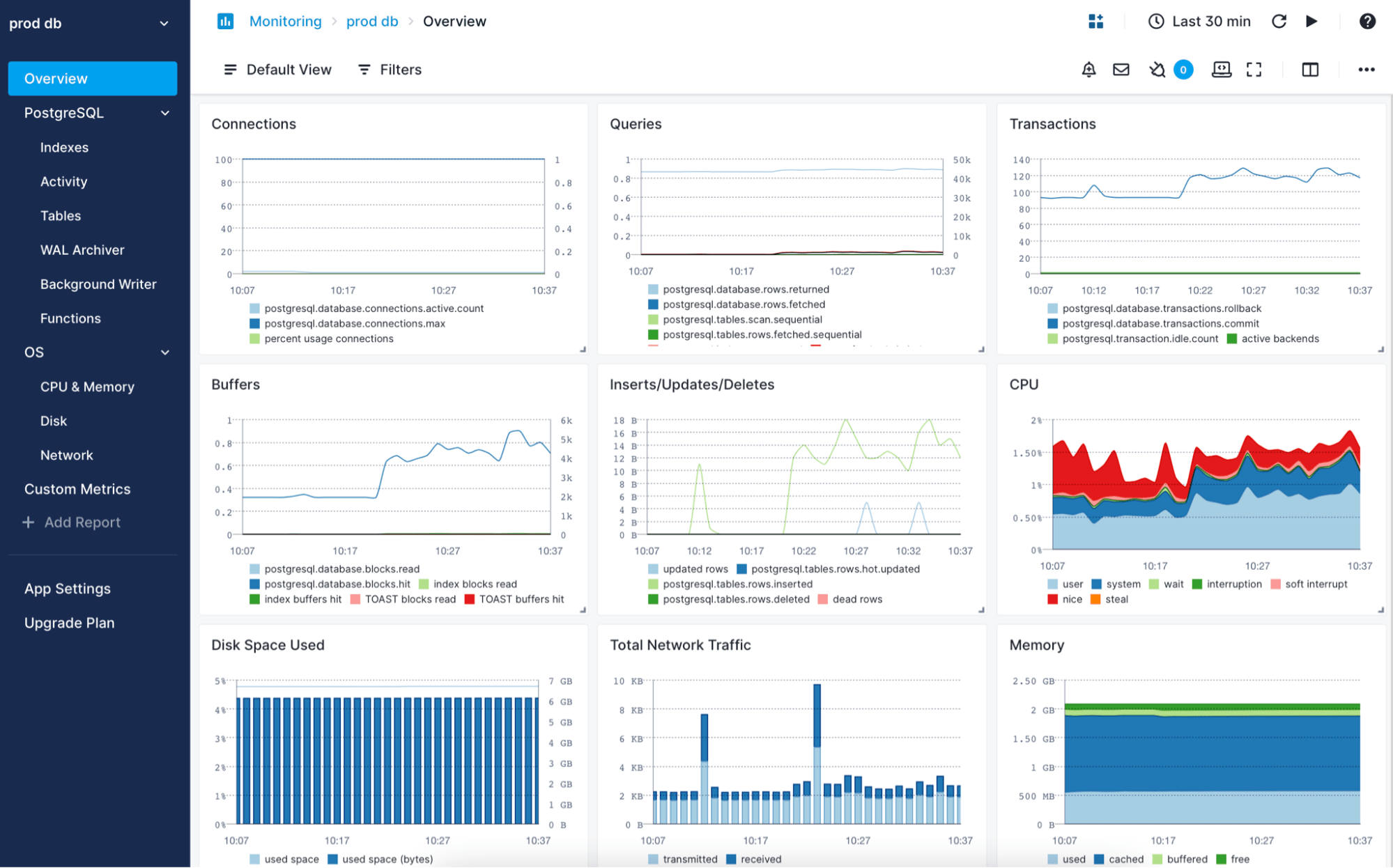
- Complex analytics queries timed out - Our reporting dashboard took 45 seconds to load inventory reports (PostgreSQL query optimization guide)
- Foreign key constraints were optional - I spent 2 days debugging phantom data because MySQL silently ignored a broken relationship (MySQL foreign key reliability issues)
- Replication kept shitting the bed - MySQL's master-slave replication failed twice during Black Friday prep (MySQL vs PostgreSQL reliability comparison)
Hardware Reality Check - Don't Be Like Me
Anyway, this bit me in the ass hard and I don't want you to go through the same pain:
I learned this the hard way when pgloader crashed at 89% complete (pgloader heap exhaustion issue):
- 16GB RAM minimum - I tried with 8GB and pgloader ate all available memory and crashed after 6 hours (pgloader memory requirements)
- SSD storage is non-negotiable - My first migration took 18 hours on spinning rust, same database took 4 hours on SSD (PostgreSQL storage considerations)
- Fast network connection - Migration over VPN to AWS took 14 hours, direct connection took 3 hours (migration best practices)
- 3x storage space not 2x - PostgreSQL uses more space than MySQL for the same data, plus you need temp space for indexes. I think our 47GB MySQL database ended up needing like 140GB? Maybe 150GB? I honestly stopped counting when the disk usage alarm went off at 3am (PostgreSQL vs MySQL storage differences)
Tools that actually work:
- PostgreSQL 17.5 - current stable build as of September 2025, been rock solid in production for us (PostgreSQL 17.5 release notes)
- pgloader 3.6.9 - Latest stable version, avoid 3.6.7 which had bugs with large TEXT columns (pgloader GitHub releases)
- MySQL 8.0+ or 8.4 LTS (if you're still on 5.7, it's EOL as of October 2023 - upgrade first)
- DBeaver because pgAdmin's interface makes me want to throw my laptop out the window

Pre-Migration Assessment (The Stuff That Will Bite You Later)
Run these queries to find the landmines in your schema (replace inventory_db with your actual database):
-- Find the data types that will cause pgloader to have a mental breakdown
SELECT DISTINCT DATA_TYPE
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'inventory_db'
AND DATA_TYPE IN ('ENUM', 'SET', 'YEAR', 'TINYINT');
-- Identify your biggest tables (these take forever to migrate)
SELECT TABLE_NAME,
ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) as SIZE_MB
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'inventory_db'
ORDER BY SIZE_MB DESC;
-- Find stored procedures that you'll need to rewrite by hand
SELECT ROUTINE_NAME, ROUTINE_TYPE
FROM information_schema.ROUTINES
WHERE ROUTINE_SCHEMA = 'inventory_db';
The 4 things that will definitely fuck you up:
- ENUM columns become CHECK constraints - Our product status went from
ENUM('active','discontinued')to a CHECK constraint that half our app didn't expect - AUTO_INCREMENT sequences start weird - PostgreSQL sequences don't start at your current max ID unless you tell them to
- Zero dates break everything - MySQL's
0000-00-00dates will cause pgloader to error out. I had 1,247 records with invalid dates in our orders table - Case sensitivity will murder your app - PostgreSQL converts
ProductTabletoproducttable, your ORM queries will fail with "relation does not exist"
Realistic Timeline Planning (Not The Bullshit Estimates You See Elsewhere)
OK, real talk time. Every migration guide lies about timelines:
How long this actually takes (based on my last 5 migrations):
- Under 1GB: 1-2 hours (including debugging weird schema issues)
- 1-10GB: 2-5 hours (our 8GB customer database took 4.5 hours)
- 10-50GB: 4-8 hours (the 47GB inventory database took 7 hours including index rebuilds, or maybe 9 hours? I lost track after the UTF-8 issue)
- 50-100GB: 8-16 hours (and that's if nothing breaks)
Downtime reality check:
- Schedule for a weekend because shit will go wrong
- Plan for 2x your estimated time - my "4 hour migration" took 9 hours when pgloader choked on our UTF8 data
- Have pizza and coffee ready - you'll be debugging until 3am. I spent 6 hours tracking down why our user login system broke, turned out PostgreSQL was case-sensitive on the username column and half our users had mixed-case usernames in MySQL
- Keep MySQL running until you're 100% sure PostgreSQL works - I rolled back twice before getting it right
The migration itself is the easy part. It's the 47 SQL queries in your application that assume MySQL's quirks that will ruin your week.