Running the latest Drizzle 0.44.5 in production and connection pooling breaks in ways that never happen locally.
Connection Pooling That Actually Works
Connection pooling means keeping database connections open instead of creating new ones for every request. Pretty straightforward until it completely fucks you over in production.
Database connections fail in production if you don't get the pool settings right. Found this out when our Node.js 20.11.0 app went down for 2 hours - PostgreSQL 15.4 has a 100 connection limit by default and we hit it during Black Friday traffic.
For Traditional Servers (Node.js, whatever):
import { Pool } from 'pg';
import { drizzle } from 'drizzle-orm/node-postgres';
const pool = new Pool({
connectionString: process.env.DATABASE_URL,
max: 10, // Don't go above 20, trust me
idleTimeoutMillis: 10000, // Kill idle connections fast
connectionTimeoutMillis: 2000, // Fail fast when DB is fucked
statement_timeout: 10000, // Kill slow queries
});
export const db = drizzle(pool, { schema });
In my experience, pools above 20 connections usually make things worse. Most databases can't handle that many connections anyway. Start with 10, monitor with pg_stat_activity, then bump to 15 if you're actually hitting limits.
For Serverless Functions (Vercel, AWS Lambda):
I learned this the hard way with serverless - every damn function creates its own connections, so you hit database limits fast. Traditional connection pooling doesn't work because functions are stateless and don't give a shit about your carefully configured pools.
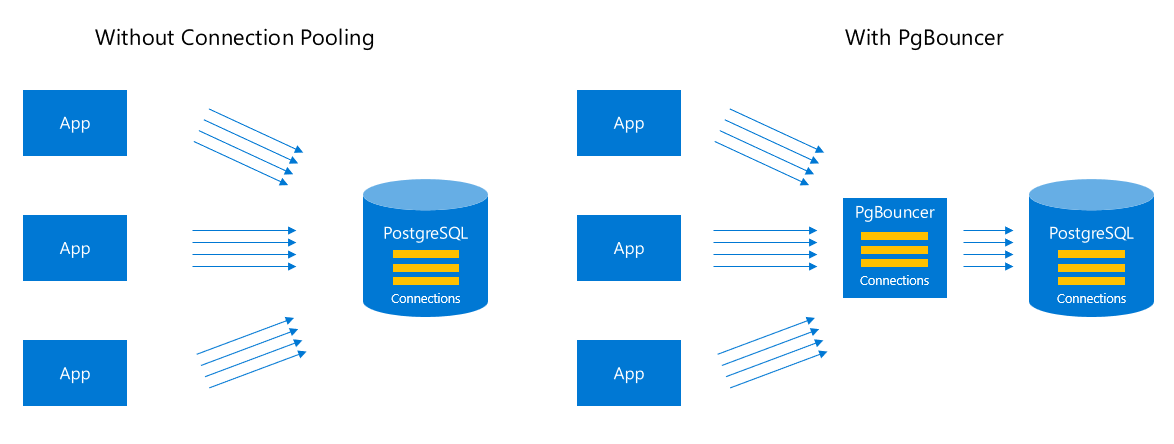
Every cold start means new connections, and with traditional drivers you hit connection limits during traffic spikes. HTTP-based database drivers work better for serverless since they don't maintain persistent connections. Neon's serverless approach specifically addresses these challenges with WebSocket connections for better performance.
// Neon HTTP - optimal for serverless (no persistent connections)
import { drizzle } from 'drizzle-orm/neon-http';
import { neon } from '@neondatabase/serverless';
const sql = neon(process.env.DATABASE_URL!);
export const db = drizzle(sql, { schema });
// Vercel Postgres - built-in connection management
import { drizzle } from 'drizzle-orm/vercel-postgres';
import { sql } from '@vercel/postgres';
export const db = drizzle(sql, { schema });
// Supabase - connection pooling handled automatically
import { drizzle } from 'drizzle-orm/postgres-js';
import postgres from 'postgres';
const queryClient = postgres(process.env.DATABASE_URL!, {
max: 1, // Serverless functions should use minimal connections
idle_timeout: 20,
connect_timeout: 10,
});
export const db = drizzle(queryClient, { schema });
Supabase handles connection pooling automatically through PgBouncer, but their docs are absolute garbage when you're trying to debug connection issues at 3am.
Edge Runtime Deployment Patterns

Edge functions are finicky bastards when it comes to database drivers. Here's what's actually working for us (after trying everything else):
Cloudflare Workers + D1:
D1 is SQLite at the edge with global replication. Works pretty well when it's not being slow as molasses.
import { drizzle } from 'drizzle-orm/d1';
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const db = drizzle(env.DB, { schema });
// D1 handles connection management automatically
const users = await db.select().from(usersTable).limit(10);
return new Response(JSON.stringify(users));
},
};
Vercel Edge Functions:
// Uses Neon HTTP or Vercel Postgres
import { drizzle } from 'drizzle-orm/neon-http';
import { neon } from '@neondatabase/serverless';
const sql = neon(process.env.DATABASE_URL!);
const db = drizzle(sql, { schema });
export const runtime = 'edge';
export default async function handler(req: Request) {
// Works in Vercel Edge Runtime
const result = await db.query.users.findMany({ limit: 10 });
return new Response(JSON.stringify(result));
}
Vercel Edge will bite you in the ass: Works fine in development, then crashes in production with "Module not found: Can't resolve 'pg'" errors. Took me 4 hours to figure out that Edge Runtime can't import pg or any Node.js modules. Use neon-http instead or your deploy will fail every fucking time.
Memory Management and Performance Optimization
Common ways database performance gets worse in production:
1. Query Optimization

// ❌ Bad - fetches all columns, causes memory bloat
const users = await db.select().from(usersTable);
// ✅ Good - select only needed fields
const users = await db.select({
id: usersTable.id,
name: usersTable.name
}).from(usersTable);
// ✅ Better - use prepared statements for repeated queries
const getUserByEmail = db
.select({ id: usersTable.id, name: usersTable.name })
.from(usersTable)
.where(eq(usersTable.email, sql.placeholder('email')))
.prepare('getUserByEmail');
// Reuse for significant performance gains
const user = await getUserByEmail.execute({ email: userEmail });
Prepared statements provide significant performance improvements by avoiding query parsing overhead.
2. Schema Design
Identity columns work better than serial in most cases - they're faster and handle connection pooling better. PostgreSQL identity columns provide better concurrency than serial columns:
import { pgTable, integer, varchar, timestamp } from 'drizzle-orm/pg-core';
// Identity columns that actually work
export const users = pgTable('users', {
id: integer('id').primaryKey().generatedAlwaysAsIdentity(),
email: varchar('email', { length: 320 }).notNull().unique(),
createdAt: timestamp('created_at', {
mode: 'date', // Way faster than string parsing
precision: 3, // Milliseconds matter in logging
withTimezone: true // Saves you from timezone hell
}).notNull().defaultNow(),
});
3. Index Strategy
Production-tested indexing patterns that actually improve performance. PostgreSQL indexing best practices and index types matter for query performance:
export const orders = pgTable('orders', {
id: integer('id').primaryKey().generatedAlwaysAsIdentity(),
customerId: integer('customer_id').notNull(),
status: varchar('status', { length: 20 }).notNull(),
orderDate: timestamp('order_date').notNull(),
}, (table) => [
// Composite index - column order matters for performance
index('orders_customer_status_date_idx')
.on(table.customerId, table.status, table.orderDate.desc()),
// Partial index - can improve performance significantly for filtered queries
index('orders_active_idx')
.on(table.customerId, table.orderDate.desc())
.where(sql`${table.status} = 'active'`),
]);
Migration Management in Production
Migration mistakes can bring down production. Teams sometimes mix push and migrate commands and end up with inconsistent schemas. Database migration strategies and zero-downtime deployments require careful planning:
Development to Production Pipeline:
- Development: Use
drizzle-kit pushfor rapid iteration - Staging: Generate clean migrations with drizzle-kit generate
- Production: Apply migrations with drizzle-kit migrate
## Development - instant schema updates
npx drizzle-kit push --verbose
## Before production deployment - generate clean migration files
npx drizzle-kit generate --name add_user_preferences
## Production deployment - apply migrations safely
npx drizzle-kit migrate --config production.config.ts
Critical Migration Safety Pattern:
// production.config.ts
import { defineConfig } from 'drizzle-kit';
export default defineConfig({
dialect: 'postgresql',
schema: './src/schema.ts',
out: './migrations',
dbCredentials: {
url: process.env.DATABASE_URL!,
},
// Production safety settings
strict: true, // Fail on unsafe migrations
verbose: true, // Detailed logging
migrations: {
schema: 'drizzle', // Separate schema for migration tracking
table: '__drizzle_migrations',
},
});
Error Handling That Actually Helps
Drizzle 0.44.0 added DrizzleQueryError which gives better error details than generic "query failed" messages:
import { DrizzleQueryError } from 'drizzle-orm';
try {
const result = await db.query.users.findFirst({
where: eq(users.id, userId),
});
} catch (error) {
if (error instanceof DrizzleQueryError) {
// Log the actual SQL and parameters for debugging
console.error('Database query failed:', {
sql: error.sql,
params: error.params,
originalError: error.originalError,
stack: error.stack,
});
// Send to your monitoring service
// Sentry, DataDog, etc.
}
throw error;
}
The next section covers specific deployment platform configurations and the gotchas that will save you hours of debugging time.