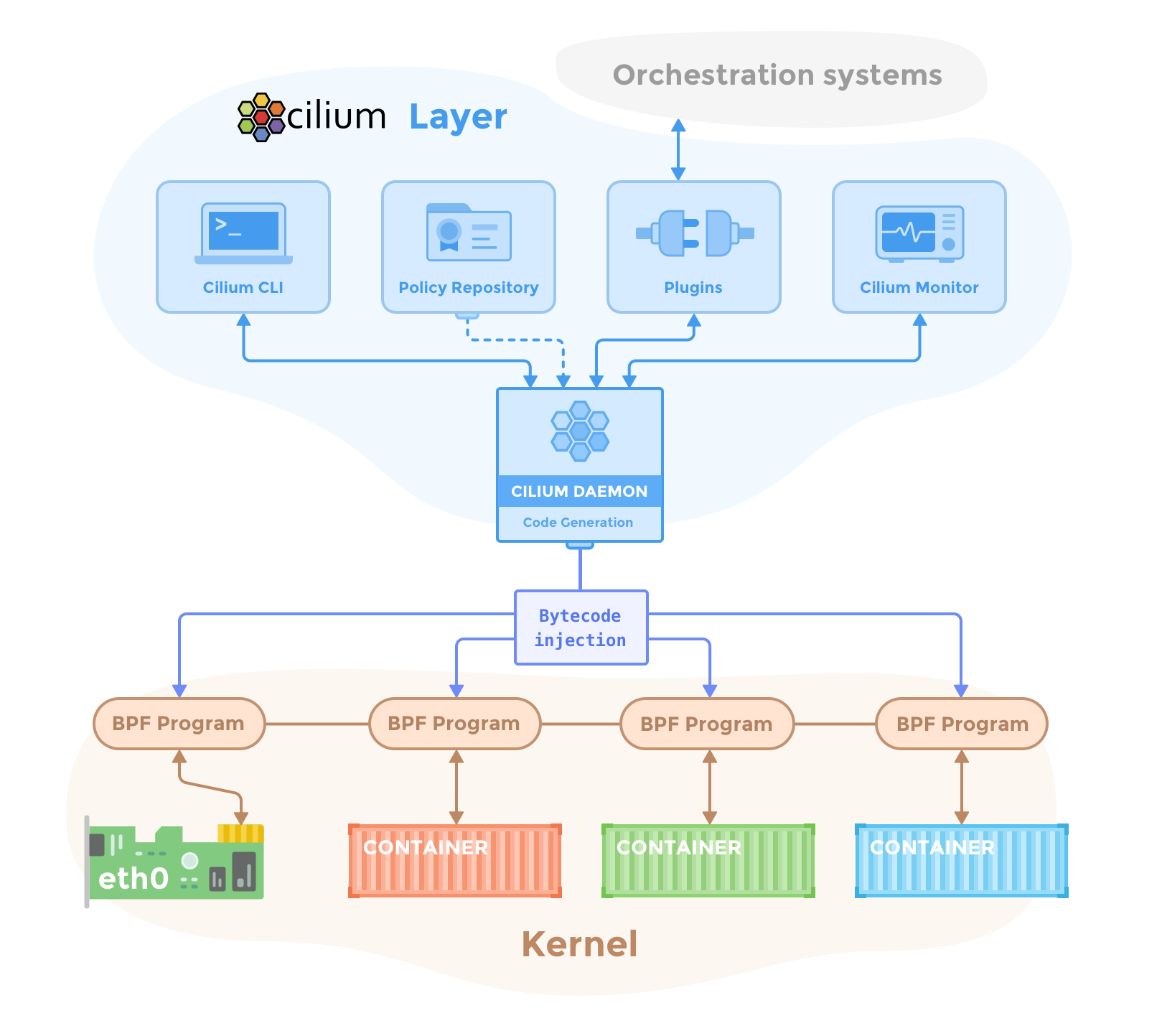
I've been paged at 3AM more times than I care to count because CNI plugins decided to shit the bed. Here's the playbook that's saved my ass repeatedly.
Step 1: Don't Panic (But Move Fast)
First rule of production debugging: check if you can schedule new pods. If you can't, you're dealing with cluster-wide CNI failure and you have minutes before people start screaming.
kubectl run test-pod --image=nginx --rm -it -- /bin/bash
If this fails with ContainerCreating stuck forever, your CNI is toast. If it works, the problem is localized to specific pods or nodes.
The 3-Minute Triage
Check these in order - don't waste time on logs until you know what you're dealing with:
- CNI plugin pods status:
kubectl get pods -n kube-system | grep -E \"(cilium|calico|flannel)\" - Node status:
kubectl get nodes -o wide- look forNotReadynodes - Recent pod failures:
kubectl get events --sort-by='.lastTimestamp' | grep -i error | tail -10
The official Kubernetes troubleshooting guide covers this systematic approach, but here's the real-world version that actually works.
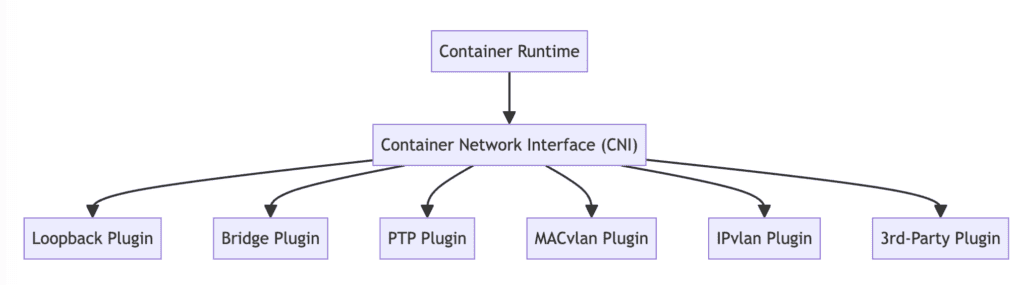
\"failed to setup CNI\" - The Most Common Nightmare
This error means the kubelet can't reach your CNI plugin. 95% of the time it's one of these:
The Kubernetes CNI troubleshooting documentation covers the theory, but James Sturtevant's debugging guide has the practical commands that actually work.
Missing CNI Binary
## Check if CNI binary exists on the failing node
kubectl get nodes
kubectl debug node/worker-node-1 -it --image=alpine
ls -la /opt/cni/bin/
If your CNI binary is missing (common after node updates), you need to reinstall:
## For Calico
kubectl rollout restart daemonset/calico-node -n kube-system
## For Cilium
kubectl rollout restart daemonset/cilium -n kube-system
## For Flannel
kubectl rollout restart daemonset/kube-flannel-ds -n kube-flannel
Corrupted CNI Config
Your CNI config lives in /etc/cni/net.d/ and if it's fucked, everything is fucked:
kubectl debug node/worker-node-1 -it --image=alpine
ls -la /etc/cni/net.d/
cat /etc/cni/net.d/*.conf
Look for:
- Invalid JSON (yes, this breaks everything silently)
- Wrong file permissions (needs to be readable by kubelet)
- Multiple configs with conflicting priorities
The fix is usually nuking the bad config and letting your CNI operator recreate it:
## Delete the broken config (do this on the node)
rm /etc/cni/net.d/10-broken.conf
## Restart CNI pods to regenerate
kubectl delete pod -n kube-system -l k8s-app=your-cni-plugin
The Dreaded \"No Route to Host\"
This is where shit gets real. Your pods can schedule but can't reach each other or external services.
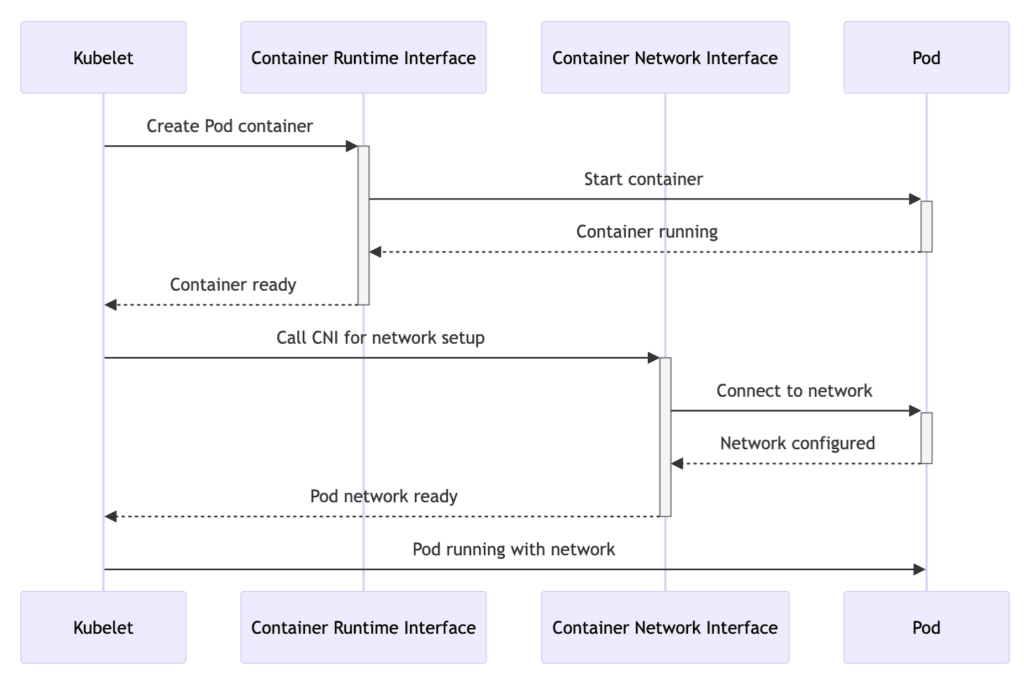
Quick Network Sanity Check
Get into a failing pod and run these commands:
kubectl exec -it failing-pod -- /bin/bash
ip route show
ping 8.8.8.8
nslookup kubernetes.default.svc.cluster.local
If ip route show is empty, your CNI plugin never set up routing. This usually means:
- CNI plugin crashed during pod creation
- IP address pool exhaustion
- Node network configuration is fucked
If external ping fails but internal DNS works, check your egress/masquerading rules.
If DNS fails, your CoreDNS pods probably can't reach the Kubernetes API. This is almost always a network policy issue. The Container Solutions debugging guide covers DNS troubleshooting in detail.
IP Address Exhaustion (The Silent Killer)
This one is sneaky - existing pods work fine, new ones get stuck in ContainerCreating. Check your IP allocation:
## For Calico
kubectl exec -n kube-system calico-node-xxxxx -- calicoctl ipam show
## For Cilium
kubectl exec -n kube-system cilium-xxxxx -- cilium status --verbose
## For AWS VPC CNI
kubectl describe configmap aws-node -n kube-system
If you're out of IPs, you have a few options:
- Expand your pod CIDR (cluster restart required - good luck)
- Enable IP prefix delegation (AWS only) - check the AWS EKS IP allocation guide
- Clean up unused pods and hope for the best
The Kubernetes troubleshooting guide has practical examples of IP exhaustion scenarios.
When Your CNI Plugin is Completely Fucked
Sometimes you just need to burn it all down and start over. Here's the nuclear option:
## Save this script - you'll need it eventually
#!/bin/bash
echo \"Nuking CNI configuration...\"
## Delete all CNI-related DaemonSets and Deployments
kubectl delete ds -n kube-system -l k8s-app=cilium
kubectl delete ds -n kube-system -l k8s-app=calico-node
kubectl delete ds -n kube-flannel -l app=flannel
## Clean up node-level networking (run this on each node)
for node in $(kubectl get nodes -o name); do
kubectl debug $node -it --image=alpine -- sh -c \"
rm -rf /etc/cni/net.d/*
rm -rf /opt/cni/bin/*
ip link delete cilium_host 2>/dev/null || true
ip link delete cilium_net 2>/dev/null || true
iptables -F -t nat
iptables -F -t filter
iptables -F -t mangle
\"
done
## Reinstall your CNI (example for Cilium)
helm upgrade --install cilium cilium/cilium --namespace kube-system
This is the equivalent of turning it off and on again, but for networking. It'll cause downtime, but sometimes it's the only way.
Pro Tips from the Trenches
Always keep a debug pod running in each namespace with network tools installed. When shit hits the fan, you don't want to wait for image pulls.
Monitor CNI plugin resource usage. I've seen Cilium eat 4GB RAM and bring down nodes. Set proper limits. The container runtime documentation covers resource limits for both containerd and CRI-O.
Test your CNI failure scenarios in dev. Most people only find out their monitoring is broken when production is on fire. For container runtime debugging, use the crictl debugging guide to interact directly with the container runtime.
Keep the previous CNI version ready to deploy. Rollbacks are faster than debugging new bugs at 3AM.
The key to CNI debugging is systematic elimination. Start with the basics (can pods schedule?), then work your way up the network stack. Don't get caught up in fancy eBPF traces until you've confirmed the fundamentals work.
For comprehensive logging strategies, check the Kubernetes logging guide and basic troubleshooting fundamentals. The CNI Kubernetes guide also provides solid fundamentals for understanding networking failures.