![]()
Node.js 22 became LTS on October 29, 2024. The V8 garbage collection improvements are nice, but they won't fix your shitty event listener cleanup or that database connection pool you're not closing properly.
The Real Failures You'll Hit
Spent the last 3 years debugging production Node.js apps. Here's what actually kills your uptime:
Event listeners that stack up like dirty dishes - Every WebSocket connection, every EventEmitter, every database pool event. You forget one `removeListener()` call and after a week your process is consuming 4GB RAM. I learned this when our chat app started eating memory after users would disconnect without closing properly.
Blocking the event loop like a jackass - One `fs.readFileSync()` in a hot path and your entire API stops responding. CPU hits 100% but nothing happens. Took me 8 hours to track down a single synchronous file read that was freezing 500 concurrent users. Use the goddamn async versions.
Unhandled promise rejections - Node 15+ will crash your process when promises reject without `.catch()`. One missing error handler in a database query chain and boom, your app exits with code 1 at peak traffic. Always add .catch() or wrap in try/catch with async/await.
Running node app.js without a process manager - Your app will crash. Not if, when. I watched a startup lose $50k in revenue because their payment API went down for 6 hours and nobody knew. Use PM2, Forever, or Docker with restart policies to restart processes automatically.
Version-Specific Gotchas
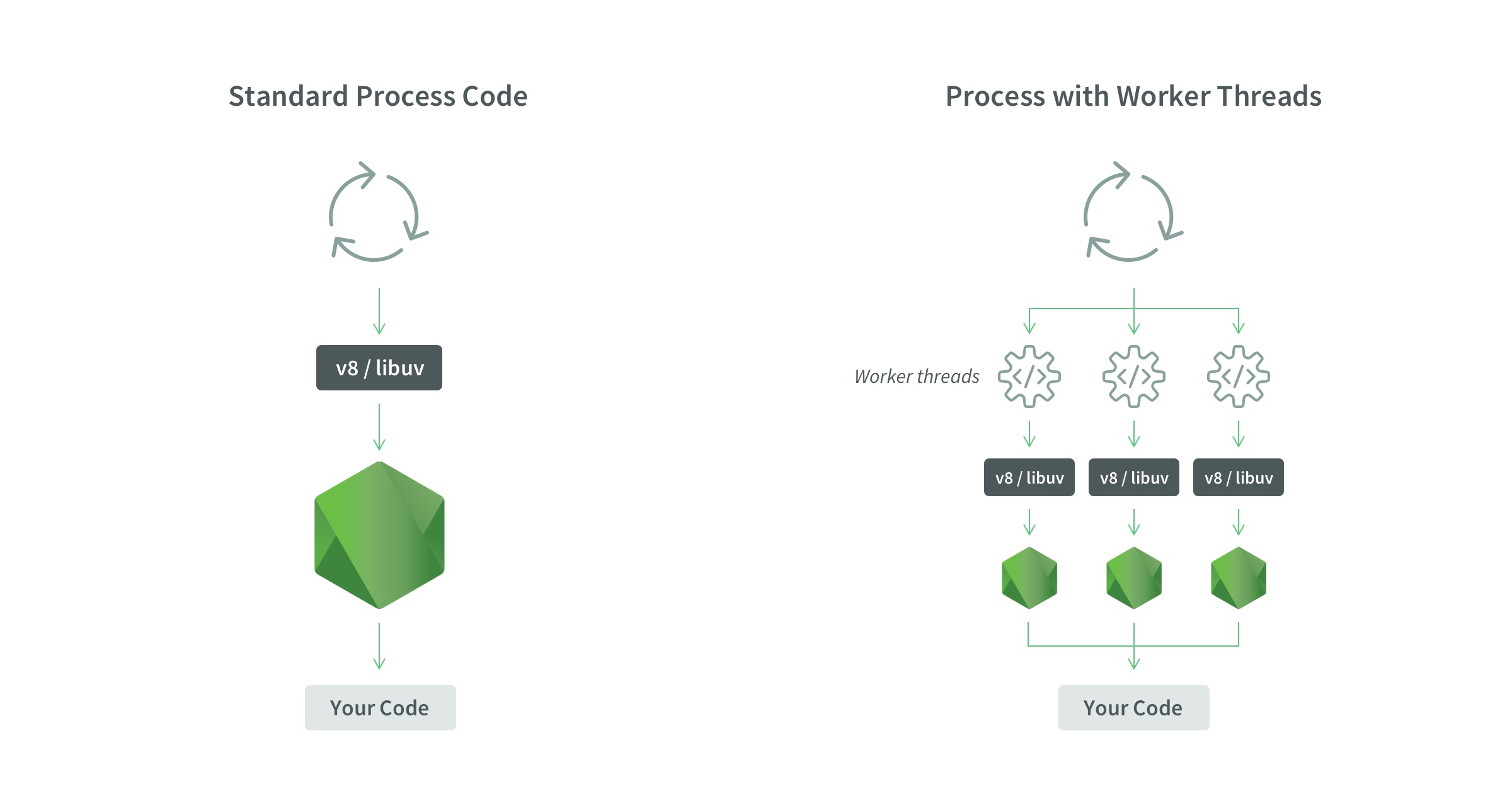
Node.js 18.0.0 had a memory leak in worker threads - Use 18.1.0 or later if you're using Workers. Found this the hard way when our background job processor started consuming 8GB RAM after 3 days.
Node.js 16.9.0 broke some crypto functions - If you're using legacy crypto code, test thoroughly before upgrading. Spent a weekend rolling back when our authentication stopped working.
The Money Reality
Look, that $301k/hour downtime number everyone quotes? Complete bullshit, but outages hurt. Our 2-hour outage in March cost us around 12 grand in lost sales plus whatever AWS charged us for the traffic backup - I think it was like 3k or something. A single memory leak ran up $800 in extra EC2 costs before we caught it.
One client's Node.js app was leaking 50MB per hour. Over 6 months, that extra memory usage cost them $2,400 in unnecessary cloud resources. Fixed it by adding proper connection pool cleanup - took 10 lines of code. Tools like Clinic.js and 0x help identify these memory leaks before they kill your budget.