The 3AM War Stories Nobody Shares in Standup
I've been through the NoSQL trenches. Not the clean conference demo kind - the kind where you're frantically Googling error messages while the site is down and your manager is breathing down your neck asking for an ETA.
MongoDB SERVER-73397 nearly ended my career. We were running MongoDB 6.0.5 in production with a 2TB dataset spread across 12 shards. During a routine balancer operation, the sharding balancer bug corrupted chunks during migration. Lost 200GB of customer transaction data. Spent 18 hours restoring from backups while the CTO kept asking "how did this happen?" and "why don't we have better monitoring?" The post-mortem was brutal - turns out 6.0.4 and 6.0.6+ were fine, but nobody read the fucking JIRA tickets before upgrading.
DynamoDB's Black Friday massacre. Our e-commerce site's user activity tracking used user IDs as partition keys. Seemed logical, right? Wrong. When our top influencer posted about our product, their user ID became a hot partition that took down the entire recommendation system. DynamoDB couldn't redistribute the load fast enough - 3,000 RCU/WCU per partition sounds like a lot until one partition gets 50,000 requests per second. While DynamoDB was "working as intended" with adaptive capacity, our users couldn't see product recommendations for 6 hours. Lost $200k in sales. My manager asked me to "think about partition key design" in my performance review.
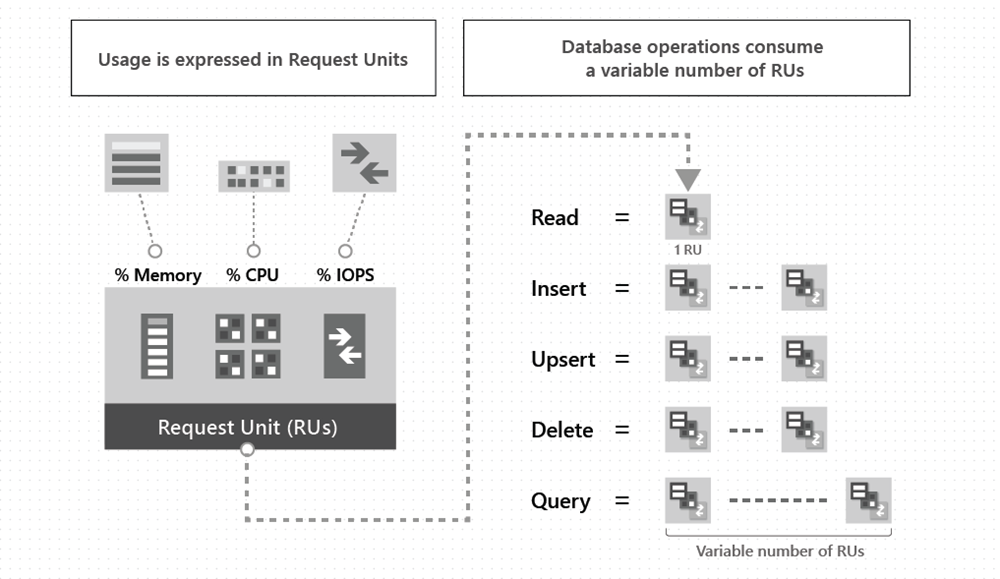
Cosmos DB's RU roulette destroyed our budget. Simple query: SELECT * FROM users WHERE active = true. Estimated cost: 5 RUs. Actual cost: 237 RUs because we forgot the container was partitioned by user ID and had to scan multiple partitions. Ran that query 10 million times over the weekend for a data export. Monday morning: $12k Azure bill. CFO called an emergency meeting. My explanation about Request Units got me a lecture about "technical decisions having business impact." Now I test every query's RU consumption before deploying. Every. Single. One.
MongoDB: The "Just Works" Option That Actually Does

MongoDB is what you choose when you want a database that doesn't make you hate your life. MongoDB 8.0 brought 36% faster read throughput, 56% faster bulk writes, and 20% faster concurrent writes, which means fewer angry Slack messages from your team about slow queries. Internal YCSB benchmarks show 54% improvement in write-heavy workloads compared to 7.0.
The good: It actually feels like a database. JSON documents, flexible schemas, aggregation pipelines that don't require a PhD to understand. ACID transactions that work across multiple documents - revolutionary, I know.
The bad: Dave left us a connection pool time bomb. Our M10 Atlas cluster has a default 100 connection limit. Dave (who no longer works here) deployed 8 Node.js microservices, each defaulting to 100 connections. Do the math: 800 connections trying to connect to a database that allows 100. During our biggest traffic spike of the year - naturally at 2AM on a Saturday - everything started failing.
// Dave's revenge code (don't do this)
const client = new MongoClient(uri); // Default: 100 connections max per service
// The fix that saved my weekend
const client = new MongoClient(uri, {
maxPoolSize: 12, // 100 total / 8 services = 12.5 per service
minPoolSize: 2, // Keep some warm
maxIdleTimeMS: 30000 // Close idle connections fast
});
When MongoDB runs out of connections, you get this useless error:
MongoNetworkError: connection 0 to localhost:27017 closed
Spent 3 hours at 2AM thinking it was network issues, DNS problems, or cosmic rays. Checked everything except the obvious. MongoDB's error message is about as helpful as a chocolate teapot. The real clue was buried in Atlas metrics showing 100/100 connections in use, but who checks those during an outage? The connection monitoring didn't alert until we were already fucked.
And don't get me started on aggregation pipelines that timeout in prod with real data - works perfectly with 1000 test documents, dies horribly with production's 50 million documents because someone forgot to add the right index.
DynamoDB: AWS Lock-in Disguised as Innovation

DynamoDB's architecture: A distributed key-value store where your data gets scattered across multiple partitions based on a hash of your partition key. Each partition can handle 3,000 RCUs or 1,000 WCUs and stores up to 10GB. When you exceed those limits, DynamoDB splits partitions, which can cause hot partition hell if your partition key design sucks.
DynamoDB is AWS lock-in dressed up as innovation. Hope you like learning their bullshit query language. Recent DynamoDB updates include enhanced multi-region consistency and improved analytics integration, which sounds great until you see the latency hit and realize you still can't escape the single-table design hell.
The good: Single-digit millisecond latency that actually delivers. Auto-scaling that works (eventually). No servers to manage, which means no SSH keys to lose.
The bad: Single-table design made our senior architect quit. Seriously. Mark had 15 years of database experience, mostly PostgreSQL. Spent 3 weeks trying to model our e-commerce catalog in DynamoDB. Users, products, orders, reviews - all in one table with composite sort keys like USER#123, PRODUCT#456, ORDER#USER#123#789. Every time the product team wanted a new query pattern, Mark had to redesign the entire schema. After the fourth complete rewrite, he said "this isn't database design, it's performance art" and took a job at a SQL shop.
GSI propagation delays destroyed our real-time features. Customer adds item to cart, immediately checks cart contents - item's not there. GSI takes 15-30 seconds to propagate the new cart data. Customer adds the same item again. Now they have 2 of everything. Customer service gets pissed, developers get blamed, product team demands "real-time consistency." Solution: read from the main table AND the GSI, dedupe client-side. Feels like building a race car with square wheels.
When DynamoDB throttles (and it will), you get this helpful error:
ProvisionedThroughputExceededException:
User defined throttling limit exceeded.
The stack trace doesn't tell you WHICH partition is hot or WHY it's hot. AWS CloudWatch metrics are 5 minutes behind reality. By the time you see the throttling metrics, customers are already complaining. Debugging hot partitions requires basically prayer and reading the tea leaves of access patterns.
Cosmos DB: The Swiss Army Knife That Cuts You

Cosmos DB is Microsoft's attempt to be everything to everyone. It supports multiple APIs (MongoDB, Cassandra, SQL, Gremlin) because apparently choosing one wasn't confusing enough.
The good: Five consistency levels give you granular control over the CAP theorem trade-offs. Global distribution with 99.999% SLA that actually means something.
The bad: RU consumption is a fucking slot machine. We built a search feature that looked innocent: SELECT * FROM products WHERE CONTAINS(description, "laptop"). In testing with 1,000 products: 8 RUs per query. In production with 2 million products: 847 RUs per query. Same exact query, 100x cost difference. Nobody at Microsoft could explain why. Their answer: "RU consumption depends on data distribution and query complexity." Thanks, that's as useful as "it depends" at a technical interview.
Multi-region conflicts murdered our user profiles. User updates their shipping address in US-East. Same user simultaneously updates their phone number in EU-West. Last-writer-wins means one update disappears. Customer calls screaming that their address got reset to their old apartment. We implemented custom conflict resolution with timestamps, but it took 2 weeks and made the codebase a nightmare.
The partition key trap almost killed our launch. Started with user ID as partition key - seemed logical for a user management system. Worked fine in testing with 100 users. In production, our power users (admins, support staff) became hot partitions. One admin's queries were throttling the entire system. Can't change partition keys without migrating all data. Took 3 days of downtime to re-partition by geographic region. CEO asked why we didn't test with realistic usage patterns. Good fucking question.
The Truth About Database Selection That'll Save Your Career
After deploying these databases in production systems and being paged at 3AM by all of them, here's what nobody tells you during the sales pitch:
MongoDB wins for keeping your sanity. Your team can ship features without existential database anxiety. Queries work like you expect, documents look like the JSON your frontend uses, and when something breaks, the error messages don't require a fucking decoder ring.
DynamoDB wins if you're AWS-committed and enjoy explaining partition keys. If you're already locked into the AWS ecosystem and have someone who can model single-table designs without crying, the performance is legitimately fast. Sub-10ms reads aren't marketing lies.
Cosmos DB wins if you need global distribution and Microsoft's budget. The feature set is genuinely impressive, global distribution works as advertised, and five consistency levels give you granular control over distributed systems trade-offs. But RU pricing will bankrupt smaller teams.
The inevitable breakdown pattern: MongoDB connection pools exhaust during traffic spikes. DynamoDB hot partitions throttle your highest-value users. Cosmos DB queries randomly cost 50x more RUs than your testing predicted.
The difference is damage control. MongoDB breaks predictably - you see connection exhaustion coming and can fix it. DynamoDB breaks mysteriously - good luck debugging which partition key design is fucking you. Cosmos DB breaks expensively - your Azure bill spikes before your monitoring even notices.
Pick the database whose failure mode won't get you fired. Not the one with the prettiest marketing slides.