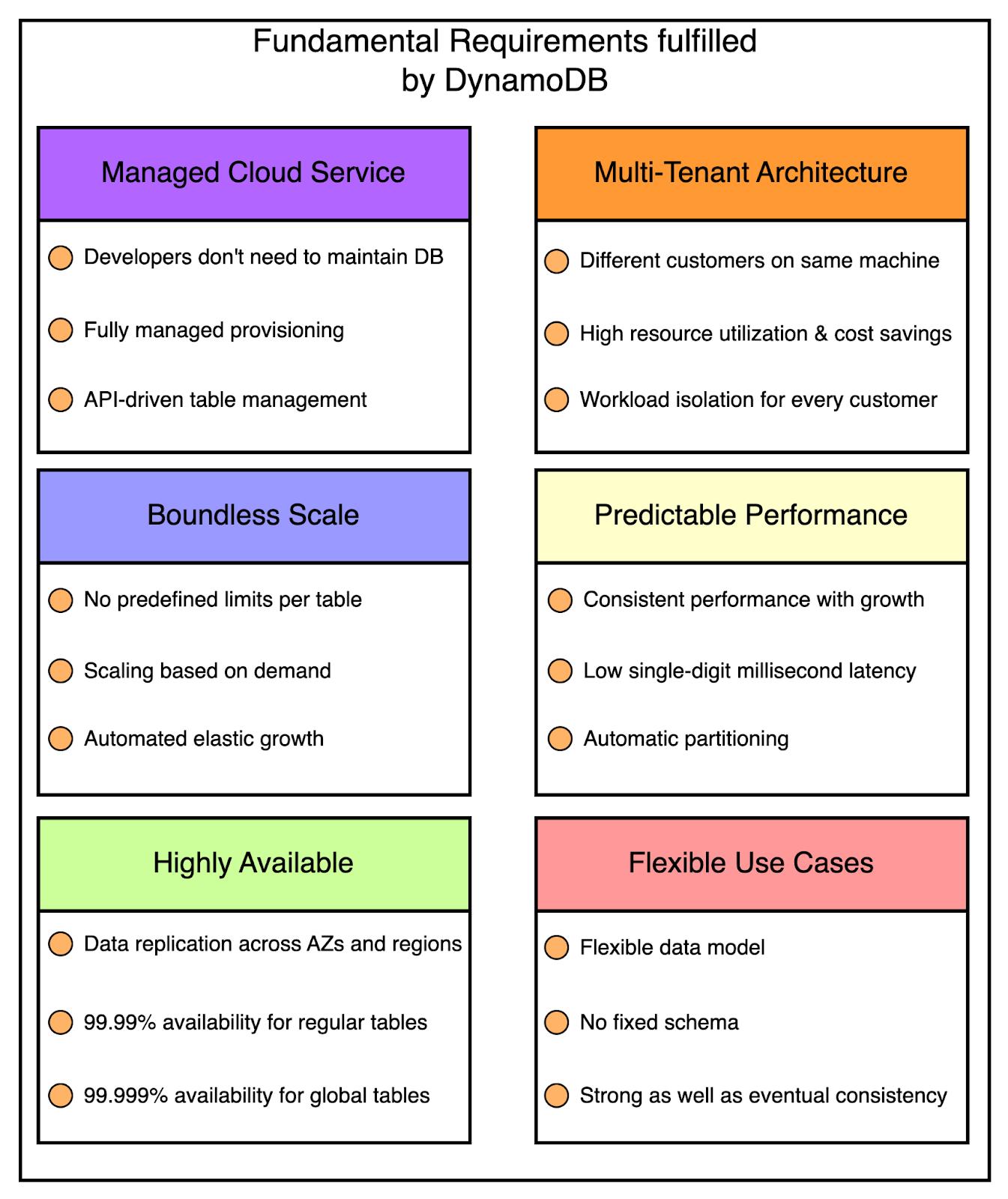
DynamoDB is Amazon's NoSQL database that handles all the server shit for you. No patching, no version upgrades, no 2am maintenance windows. Sounds too good to be true? It mostly isn't, but there are gotchas that'll bite you in the ass if you're not careful.
The Serverless Reality
The serverless part is real - you don't manage any servers. When your app isn't getting traffic, you pay almost nothing. When traffic spikes, it scales automatically. I've seen it handle massive traffic surges during Black Friday sales without breaking a sweat - we're talking 10x normal load with zero intervention.
But "serverless" doesn't mean "zero work." You still need to design your access patterns correctly from day one. Get this wrong, and you'll either pay through the nose or your queries will be painfully slow. There's no going back and adding an index like you would with PostgreSQL - that's just not how DynamoDB works.
Performance: Fast When Done Right
DynamoDB is genuinely fast - usually 1-5ms for simple key lookups. The performance stays consistent whether you're doing 100 requests or 100,000 requests per second. This happens because it partitions your data across multiple machines automatically.
Here's the catch: that performance only applies to simple key-value lookups. Try to do complex queries and you're fucked. No JOINs, no complex WHERE clauses, no ad-hoc queries. If you didn't plan for a specific query pattern upfront, you'll need to scan the entire table - which is both slow and expensive as hell. I've seen developers try to run analytics queries and burn through $500 in a morning.
The AWS Integration Trap

DynamoDB works amazingly well with other AWS services like Lambda and API Gateway. You can build entire serverless applications without thinking about servers. DynamoDB Streams let you trigger Lambda functions when data changes, which is actually pretty fucking cool for real-time processing.
But here's the thing - this tight integration means you're locked into AWS like a hostage. Moving off DynamoDB later is a massive pain because your application architecture becomes tied to AWS-specific patterns. I've seen companies spend 8+ months trying to migrate away, rewriting half their codebase in the process. One startup I worked with had to raise another funding round just to afford the migration costs.
Query Patterns Are Everything

DynamoDB forces you to think about your access patterns upfront. You design your table structure around how you'll query the data, not around the data itself. This feels backwards if you're coming from SQL databases, and it is. But it's also what makes DynamoDB scale.
The partition key determines which physical storage partition your data lives on. Get this wrong and you'll have hot partitions that throttle even when you haven't hit your table limits. This is the #1 mistake I see developers make - they use something like userId as a partition key, then wonder why their app slows to a crawl when their top user gets active.
Think of it this way: DynamoDB takes your partition key, runs it through a hash function, and that determines which physical machine your data lives on. If all your queries use the same partition key value, all your traffic hits one machine. That machine gets overwhelmed and throttles your requests, even if the other 99 machines are sitting idle.
The recent PartiQL support helps a bit - you can write SQL-like queries - but it's still limited compared to a real SQL database. And transactions work, but they're limited to 100 items max and cost more than regular operations. I learned this the hard way when a transaction-heavy feature pushed our AWS bill from $200 to $800 per month.