Once you know what's broken, here's how to actually fix it without making everything worse. These solutions work because I've used them to fix broken production environments at 3am.
Fix #1: Stop Fat-Fingering Your Labels
Label consistency is the #1 cause of network policy pain. Here's how to unfuck your labels:
First, standardize everything NOW:
## Use these exact labels everywhere or you'll hate yourself later
apiVersion: v1
kind: Pod
metadata:
labels:
app: frontend # Keep it simple, no \"application\"
version: v1.2.1 # For rolling updates
tier: web # web/api/db - nothing fancy
env: prod # prod/staging/dev - short and sweet
Audit your existing mess:
## See all the different app labels in your cluster (prepare to be horrified)
kubectl get pods --all-namespaces -o jsonpath='{range .items[*]}{.metadata.labels.app}{"
"}{end}' | sort | uniq
## Fix them all or you'll be debugging this shit forever
Don't forget namespace labels (everyone does):
apiVersion: v1
kind: Namespace
metadata:
name: production-frontend
labels:
env: prod # Match your pod labels exactly
tier: frontend
name: production-frontend # Some CNIs need this
Spent most of a day debugging a policy that looked perfect but didn't work. Turns out someone used environment: production in the namespace but env: prod in the pods. Kubernetes label selectors are case-sensitive and exact-match only. Use label standardization tools and policy validation to prevent this.
Fix #2: Unfuck Your DNS (The Thing Everyone Breaks First)
DNS breaks the moment you apply your first network policy. Your apps can reach each other by IP but not by service name. Here's the fix that actually works:
## Copy this exactly - don't get creative
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-dns-egress
namespace: your-namespace # Apply this to EVERY namespace
spec:
podSelector: {} # Applies to ALL pods in namespace
policyTypes:
- Egress
egress:
# Allow DNS to CoreDNS/kube-dns pods (you need both UDP and TCP)
- to:
- namespaceSelector:
matchLabels:
name: kube-system # This label must exist on kube-system namespace
- podSelector:
matchLabels:
k8s-app: kube-dns # Check what label your DNS pods actually have
ports:
- protocol: UDP
port: 53
- protocol: TCP
port: 53 # TCP for large DNS responses - don't skip this
Important gotchas that will waste your time:
- Check your kube-system namespace has
name: kube-system label: kubectl get namespace kube-system --show-labels
- Check your DNS pod labels:
kubectl get pods -n kube-system -l k8s-app=kube-dns --show-labels
- If you're using NodeLocal DNSCache, you need different rules
For NodeLocal DNSCache clusters, add this:
# Allow access to node-local DNS cache on each node
- to: [] # Allows access to any IP (node IPs)
ports:
- protocol: UDP
port: 53
- protocol: TCP
port: 53
Had a cluster with intermittent DNS failures for days. Turned out NodeLocal DNSCache wasn't documented anywhere in our setup. Random DNS failures are horrible to debug.
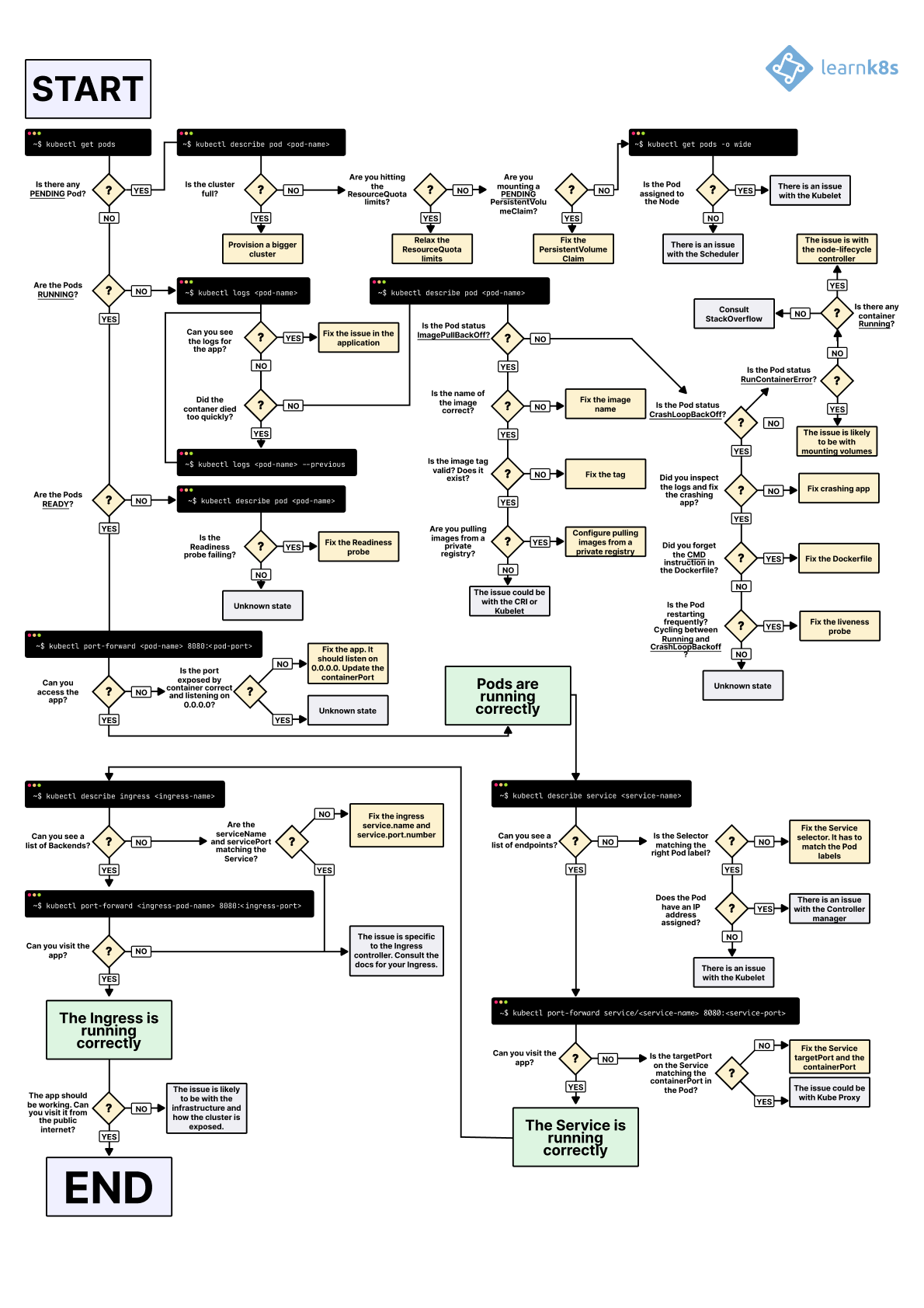
Fix #3: The Bidirectional Policy Dance (Both Directions or It Doesn't Work)
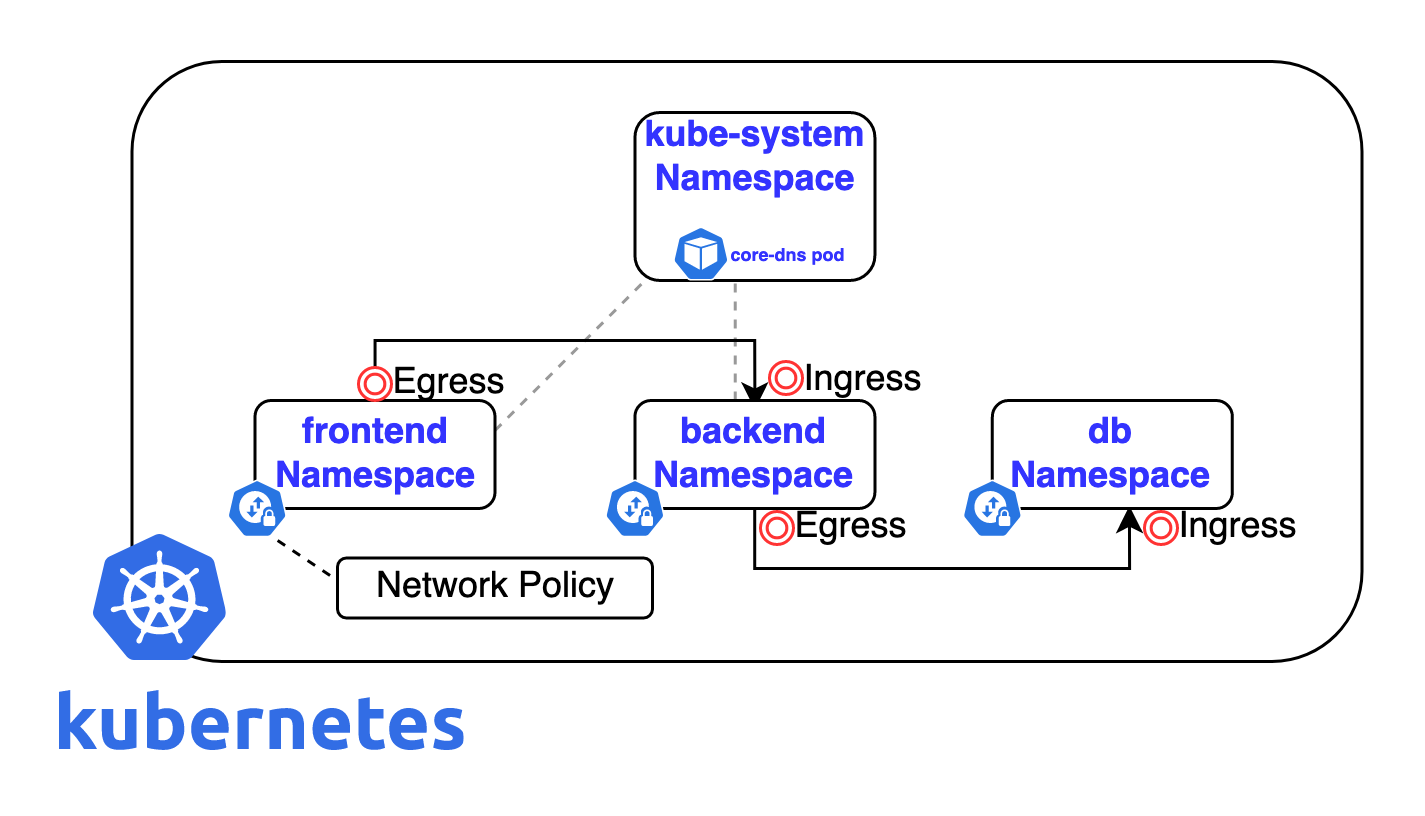
This is where everyone gets confused. You need TWO policies for every connection: one for sending and one for receiving. Miss either one and your app will fail in mysterious ways.
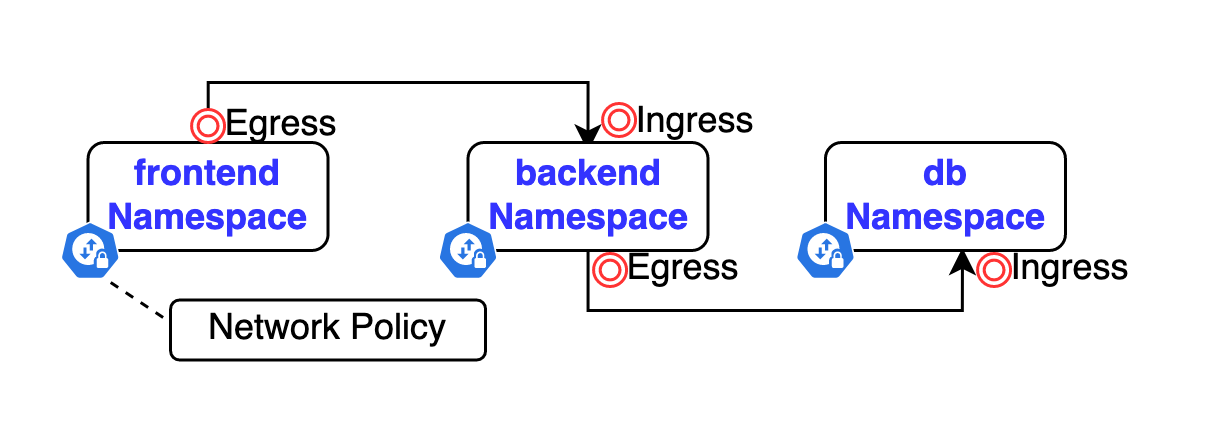
Frontend needs permission to SEND to backend:
## Frontend egress (outbound) policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: frontend-can-call-backend
namespace: frontend
spec:
podSelector:
matchLabels:
app: web-frontend # Only apply to frontend pods
policyTypes:
- Egress # This is OUTBOUND rules
egress:
- to:
- namespaceSelector:
matchLabels:
name: backend # Must match backend namespace label exactly
- podSelector:
matchLabels:
app: api-service # Must match backend pod labels exactly
ports:
- protocol: TCP
port: 8080 # The actual port your backend listens on
Backend needs permission to RECEIVE from frontend:
## Backend ingress (inbound) policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-allows-frontend
namespace: backend
spec:
podSelector:
matchLabels:
app: api-service # Only apply to backend pods
policyTypes:
- Ingress # This is INBOUND rules
ingress:
- from:
- namespaceSelector:
matchLabels:
name: frontend # Must match frontend namespace label exactly
- podSelector:
matchLabels:
app: web-frontend # Must match frontend pod labels exactly
ports:
- protocol: TCP
port: 8080 # Same port as above
Pro tip:
Start with just the ingress policy on the backend. If that works, add the egress policy on the frontend. This way you can tell which direction is broken.
Had our entire microservices stack break because of missing egress rules. Connections worked FROM the API gateway but not TO it. Took forever to figure out we only had half the required policies.
Fix #4: CNI-Specific Bullshit That Will Break Your Day
AWS VPC CNI (Expect Pain and Suffering)
AWS VPC CNI network policies are a special kind of broken. The AWS documentation is scattered across 47 different pages and half of it is wrong.
First, check if network policies are even enabled:
## Check if your VPC CNI actually supports network policies (spoiler: maybe)
kubectl describe daemonset -n kube-system aws-node | grep -i network-policy
## Look for PolicyEndpoints CRD (if this doesn't exist, nothing works)
kubectl get crd policyendpoints.networking.k8s.aws
## Check if the network policy agent container is crashing
kubectl logs -n kube-system -l app=aws-node -c aws-network-policy-agent --tail=50
Common AWS VPC CNI failures:
- The network policy agent isn't installed (you need to enable it manually)
- Your cluster doesn't have the right IAM permissions
- Your VPC CNI version is too old (needs 1.14.0+ for network policies)
- PolicyEndpoints aren't being created (check your node group permissions)
Spent way too long debugging a cluster where policies were silently ignored because the addon wasn't installed. AWS doesn't warn you - it just quietly does nothing. Found out after 3 hours that our cluster was running VPC CNI 1.12.0, which predates network policy support by about 6 months.
Calico (Works but the Logs are Cryptic as Hell)
Calico actually enforces network policies, but good luck debugging when they don't work:
Check if Calico is translating your policies correctly:
kubectl exec -n kube-system <calico-node-pod> -- calicoctl get networkpolicy -o wide
## See the actual iptables rules Calico created (prepare for hell)
kubectl exec -n kube-system <calico-node-pod> -- calicoctl get policy --output=yaml
Calico-specific gotchas:
- Calico creates its own policy objects alongside Kubernetes NetworkPolicy objects
- iptables rules are generated per-node and can get out of sync
- Felix logs are verbose but not particularly helpful for debugging policy issues
Cilium has the best debugging tools, but they only work when Cilium itself is healthy:
Test a specific connection policy decision:
kubectl exec -n kube-system <cilium-pod> -- cilium policy trace --src-k8s-pod=frontend:web-pod --dst-k8s-pod=backend:api-pod --dport=8080
## Monitor policy decisions in real-time (this is actually useful)
kubectl exec -n kube-system <cilium-pod> -- cilium monitor --type=policy-verdict
Cilium-specific gotchas:
- eBPF programs can fail to load on older kernels (check kernel version)
- Cilium policies interact weirdly with kube-proxy in some configurations
- Policy trace only works if you have the exact pod names and namespaces
Fix #5: How to Lock Down Your Cluster Without Breaking Everything
The nuclear option is a default-deny policy that blocks everything, then you allow specific traffic. This works great until you realize you blocked health checks, DNS, API server access, and 47 other things you forgot about.
Here's a default-deny policy that doesn't completely destroy your cluster:
## Copy this but test it in staging first (seriously)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-but-allow-basics
namespace: production # Apply to each namespace separately
spec:
podSelector: {} # Affects ALL pods in namespace
policyTypes:
- Ingress # Block all inbound
- Egress # Block all outbound
egress:
# Allow DNS (or everything breaks immediately)
- to:
- namespaceSelector:
matchLabels:
name: kube-system
ports:
- protocol: UDP
port: 53
- protocol: TCP
port: 53
# Allow Kubernetes API access (for health checks and service discovery)
- to: [] # Any destination
ports:
- protocol: TCP
port: 443 # Kubernetes API server port
# Allow common health check ports (adjust for your apps)
- to: []
ports:
- protocol: TCP
port: 8080 # Common health check port
- protocol: TCP
port: 9090 # Prometheus metrics port
Things this policy will still break:
- Anything that uses non-standard health check ports
- Applications that need to talk to external services
- Monitoring that scrapes metrics on non-standard ports
- Any inter-pod communication you haven't explicitly allowed
Test this everywhere first. Seen this policy break entire environments because monitoring used port 9100 instead of 9090, or some random app needed a weird port nobody documented.
Advanced Troubleshooting for Complex Policy Interactions
Policy Overlap Resolution
When multiple policies apply to the same pods, understanding their combined effect requires systematic analysis:
## List all policies affecting a specific pod
kubectl get networkpolicy --all-namespaces -o json | jq -r '.items[] | select(.spec.podSelector.matchLabels | keys | length > 0) | .metadata.namespace + "/" + .metadata.name'
## Create policy effectiveness matrix
for policy in $(kubectl get networkpolicy -n <namespace> -o name); do
echo "=== $policy ==="
kubectl describe $policy -n <namespace>
done
When Your Cluster is Slow as Hell
Too many network policies can make your cluster perform like shit. Each policy creates iptables rules or eBPF programs, and too many rules slow down packet processing.
- Consolidate policies: If you have 5 policies with the same selectors, combine them
- Use namespace selectors: One policy for a whole namespace beats 20 pod-specific policies
- Monitor your CNI: Check if Calico Felix or Cilium agent is eating CPU
Test Your Policies Before They Break Production
Write simple tests so you know if your policies actually work:
#!/bin/bash
## Test if your policy actually blocks what it should block
test_connection() {
local source_pod=$1
local target_host=$2
local target_port=$3
local should_work=$4
echo "Testing: $source_pod -> $target_host:$target_port"
if kubectl exec $source_pod -- nc -zv $target_host $target_port 2>/dev/null; then
result="WORKS"
else
result="BLOCKED"
fi
if [ "$result" = "$should_work" ]; then
echo "✓ PASS: $result (expected $should_work)"
else
echo "✗ FAIL: $result (expected $should_work)"
return 1
fi
}
## Test that frontend can reach backend
test_connection "frontend-pod" "backend-service" "8080" "WORKS"
## Test that frontend cannot reach database directly
test_connection "frontend-pod" "database-service" "5432" "BLOCKED"
Run these tests every time you change policies. Trust me, you'll catch policy mistakes before they hit production.