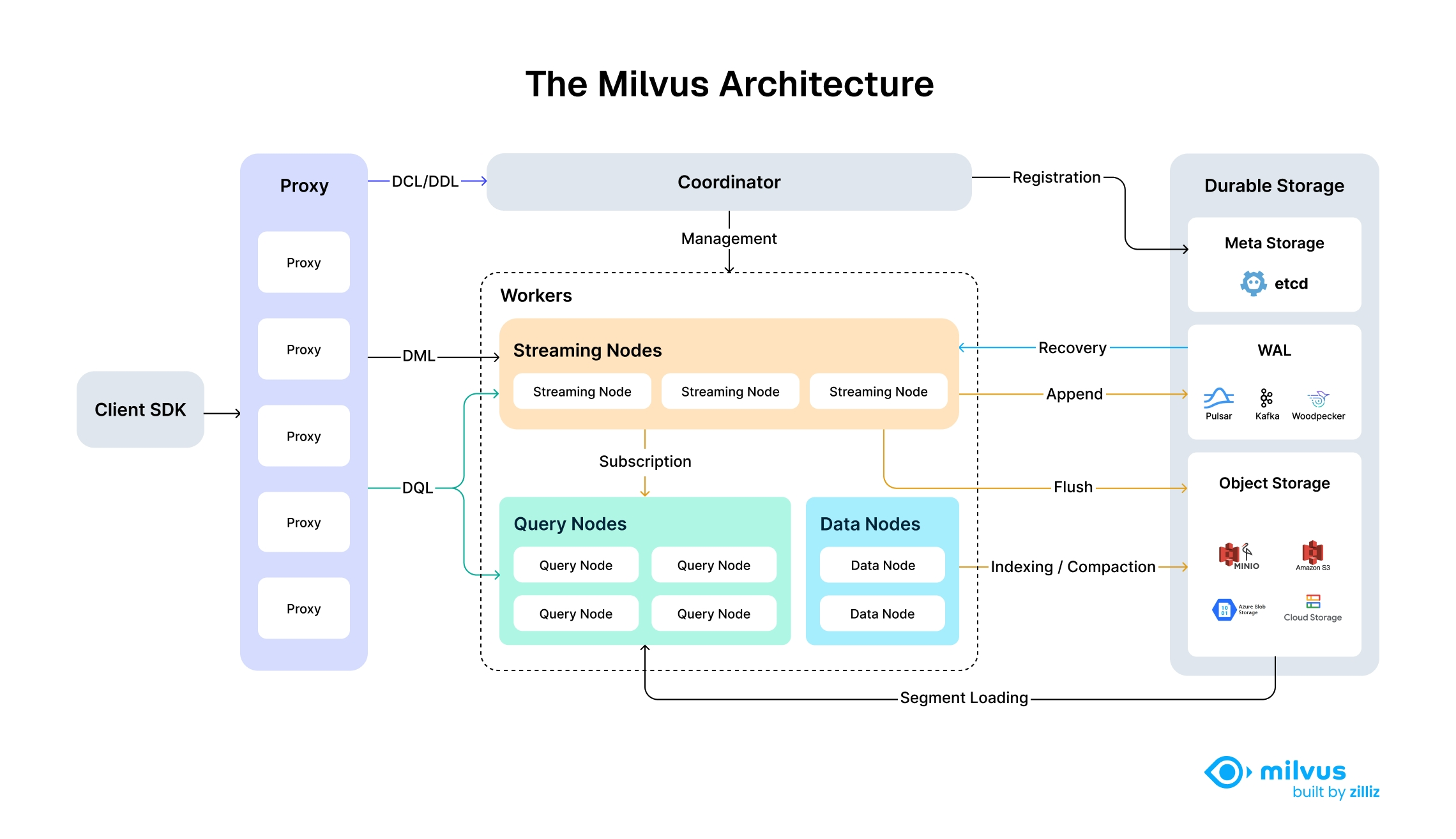
We've deployed vector databases in production for three years now, and here's the reality: running Milvus yourself is a nightmare. Zilliz Cloud is managed Milvus built by the same team that created the open-source version, which means they actually understand what breaks in production.
The Real Problem with Vector Databases
If you've tried to run a vector database in production, you know the pain.
Traditional SQL databases weren't built for high-dimensional embeddings, and setting up specialized vector infrastructure is harder than anyone admits:
- Your first Milvus deployment will take 3-5 days, not "30 minutes" like the docs claim
- Kubernetes networking issues will fuck up your weekend at least twice
- Index selection is black magic
- choose wrong and your queries take 10x longer
- Memory management is brutal
- one misconfigured collection can OOM your entire cluster
What Zilliz Cloud Actually Solves
The managed service handles all the shit that breaks when you scale.
We've seen production improvements like:
Real Performance Numbers:
In our tests, Zilliz Cloud handles 30K QPS consistently. The "50K QPS" marketing number is achievable but you need the right instance types and your queries can't be garbage. Expect 10-20ms P99 latency on realistic workloads
- not the sub-millisecond fantasy.
We learned this the hard way during a product launch when query latency jumped to 500ms+ because auto-scaling couldn't provision nodes fast enough for a traffic spike. Had to manually scale the cluster while customers were complaining about slow search results.
Migration That Doesn't Suck: Moving from self-hosted Milvus took us 2 weeks, not 2 hours.
But their migration tools actually work and don't corrupt data, which is more than we can say for other providers.
Security That's Not an Afterthought: SOC 2 compliance is real, VPC networking works correctly, and RBAC doesn't randomly break like it does in DIY setups.
When to Use Zilliz vs Alternatives
Use Zilliz Cloud if:
- You're already running Milvus and tired of managing it
- You need >10M vectors and Pinecone is getting expensive
- Your team understands vector databases but hates DevOps
Skip it if:
- You're just prototyping (free tier is limited
- use Pinecone)
- You need hand-holding support (Pinecone's docs are better)
- You're storing <1M vectors (overkill for small use cases)
Production Reality Check
The "AI-powered AutoIndex" is marketing speak for decent defaults.
It works fine for most use cases but you'll still need to tune for optimal performance. Budget 2-3 days for proper configuration, not the "5 minutes" they advertise.
Cost-wise, you'll pay about $200-400/month for a real production workload with millions of vectors. The free tier is good for demos but hits limits fast. Serverless pricing sounds great until you realize bulk imports can spike your bill to $1000+ if you're not careful.
The bottom line: if you need a vector database that just works and you don't want to become a Milvus expert, Zilliz Cloud is solid. Just don't believe the marketing numbers
- expect typical cloud database performance and pricing.