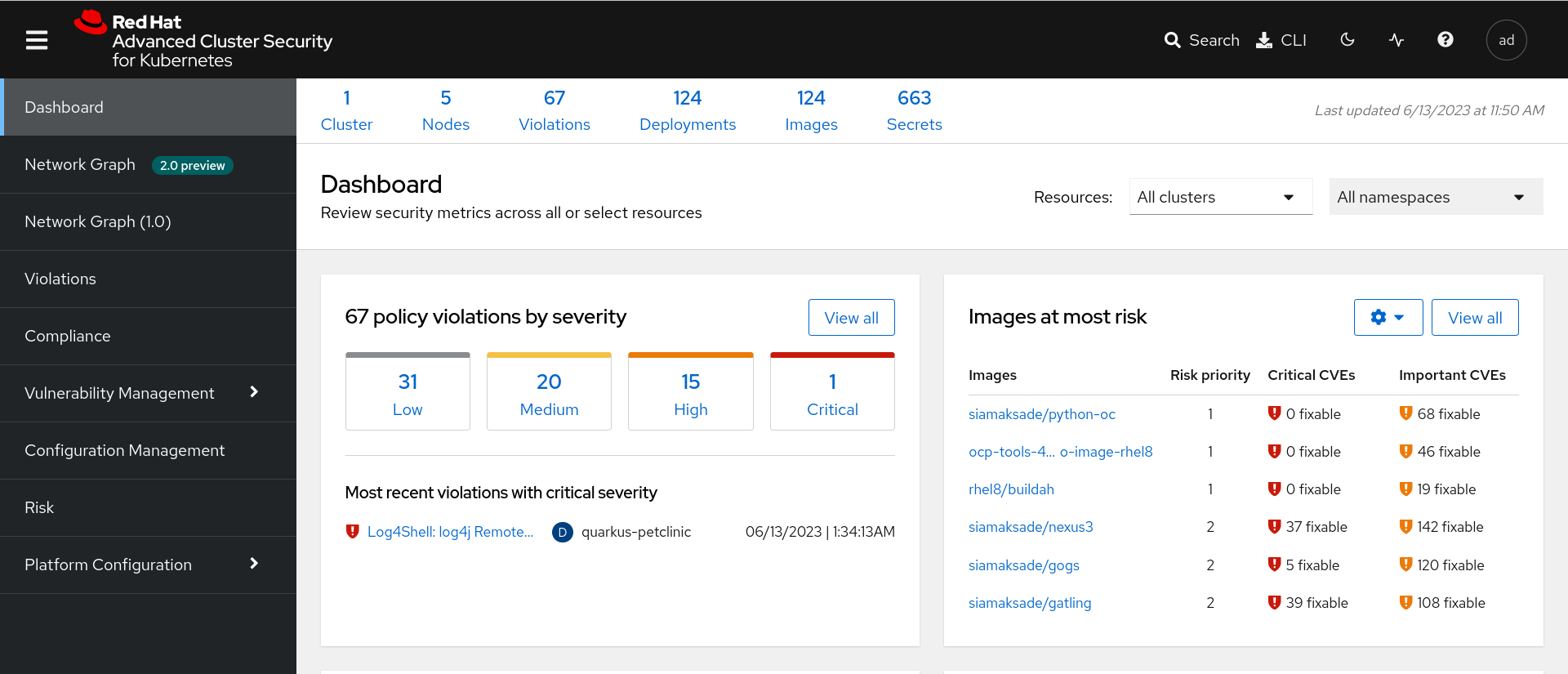
RHACS alerts at 2am usually mean something's actually wrong or your policies are garbage. The web interface times out when you have too many violations, so use roxctl instead of fighting with the browser:
## When the UI is being useless
roxctl central violations list --severity=CRITICAL --limit=50
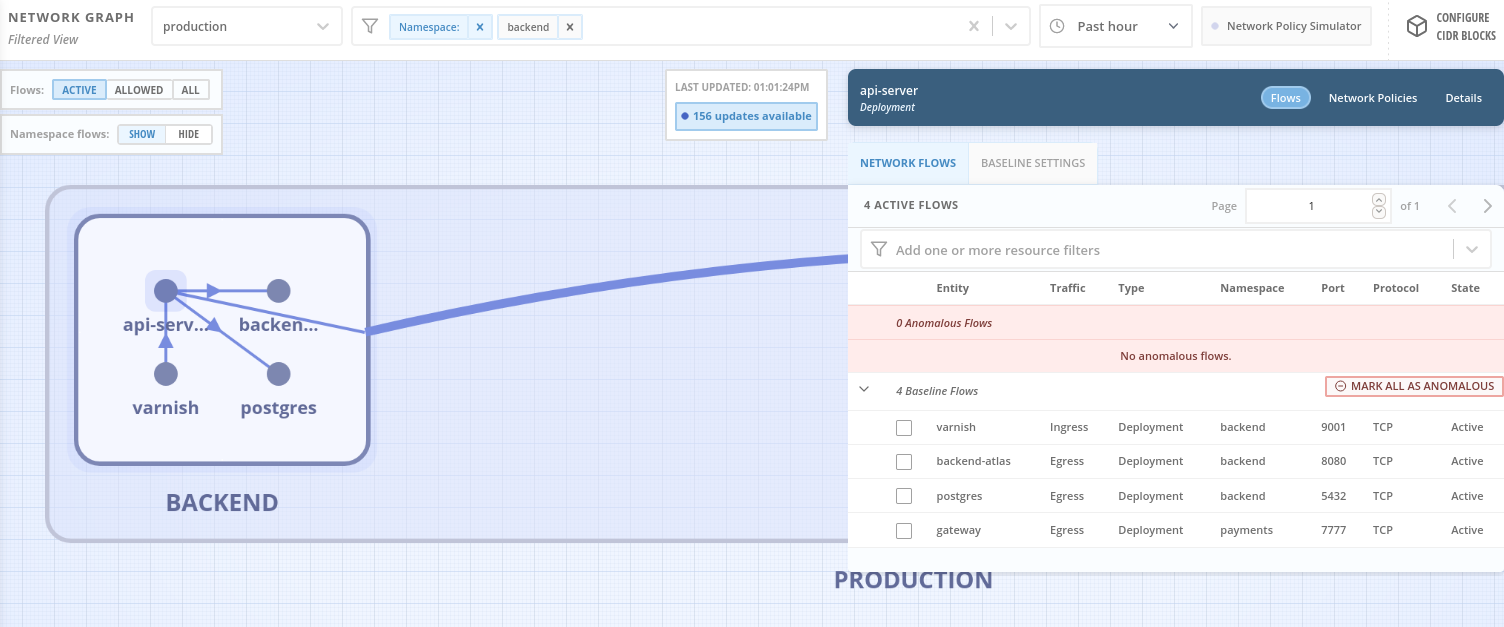
The network graph is slow as hell and will crash if you don't have enough memory. Image scanning chokes on anything bigger than a few GB.
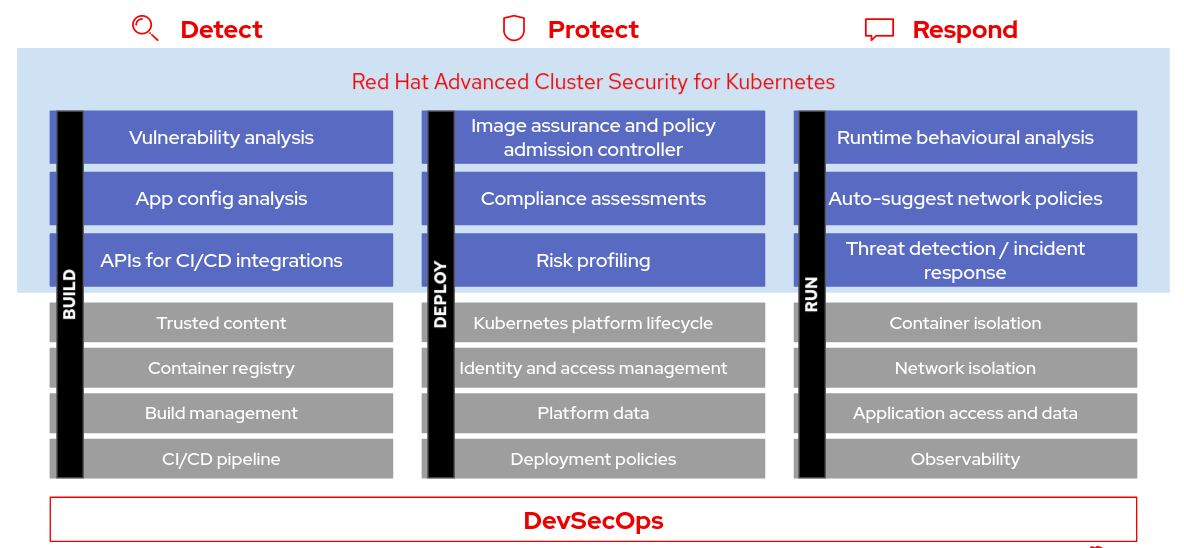
Finding the Real Problems
Default policies flag every init container as "Privilege Escalation" because they don't understand that init containers need to do setup work. Istio sidecars trigger "Unauthorized Network Flow" constantly because RHACS doesn't know about service mesh traffic patterns. CI pipelines running apt update get flagged as "Suspicious Process Execution" because the policy doesn't understand that package managers are normal in build environments.
Crypto miners actually running vs build noise:
## Real threat - mining processes
roxctl central deployments get-processes --deployment=suspicious-app
## Look for: xmrig, cpuminer, stratum connections
## False positive - package installs
roxctl central violations list --policy="Privilege Escalation"
## Usually just containers needing CAP_CHOWN
Baseline learning takes 2-3 weeks minimum if you're lucky, longer if your traffic patterns are weird. CDN traffic from Cloudflare and AWS gets flagged as suspicious for 3-4 weeks until the system learns your patterns.
Process Analysis and Network Flows
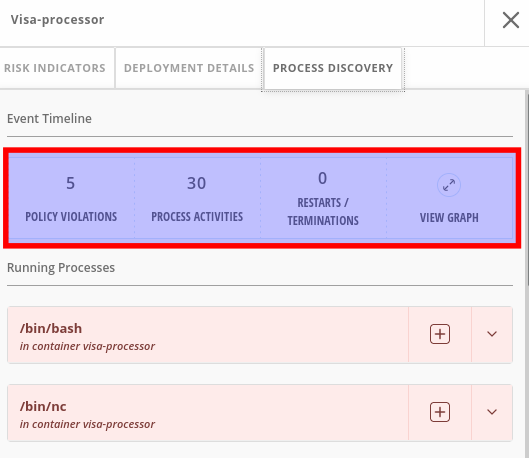
Process detection is delayed a few seconds. The UI truncates long process lists, so use --limit=0:
## See all processes, not just the first few
roxctl central deployments get-processes --deployment=compromised-app --limit=0
Look for shells (/bin/bash, /bin/sh) in production containers, download tools (curl, wget), or reverse shells (nc). Network flow detection is slower than process monitoring. External IP classification depends on threat feeds that update sporadically.
Containment Reality
RHACS can't automatically apply network policies. Network isolation depends on your CNI - Calico works, Flannel doesn't support policies.
## Quick network isolation - blocks everything
kubectl patch deployment compromised-app -p '{"spec":{"template":{"metadata":{"labels":{"quarantine":"true"}}}}}'
Then create a network policy blocking all traffic to pods with quarantine: "true". This breaks health checks and load balancers immediately. Downstream services will fail. Even RHACS Sensor loses contact after network isolation. We once quarantined a database pod during an incident and took down the entire application for 2 hours because nothing could reach the DB.
Evidence Collection Before Container Restart
Container restarts wipe RHACS data. Collect evidence fast before liveness probes restart everything:
## Export violations before container dies
roxctl central violations list --deployment=compromised-app --output=json > violations-$(date +%Y%m%d-%H%M).json
## Get process list while it still exists
roxctl central deployments get-processes --deployment=compromised-app > processes-$(date +%Y%m%d-%H%M).txt
Process data disappears after about a day. Network flows get purged faster in large clusters. Violation data sticks around for a month or two depending on retention settings.
RHACS Sensor Connectivity Issues
Sensors fail silently when Central goes down. Pods show "Running" but stop collecting data. No automatic failover exists.
## Check if sensors are actually working
roxctl sensor get-health
## Sensor logs usually have the real error
kubectl logs -n stackrox deploy/sensor | grep -i error
Sensor storage fills up without Central connectivity. Pod restarts and loses data when storage is full. Manual intervention required during incidents.
What RHACS Actually Records
Process execution shows command arguments but truncates long ones. Base64 payloads get cut off when you need them. Network flows show IPs but not packet contents. You get source/destination but no payload data - like seeing someone walked into a building but not knowing what they did inside.
Process timestamps use container timezone, not UTC - learned this the hard way during a 3am investigation when everything was off by 8 hours. Parent-child relationships break on container restarts. File system monitoring needs privileged containers, which security policies usually block. No memory dumps - crashes leave no traces. RHACS 4.8.x has a bug where process arguments get truncated at 256 characters, so base64 payloads in environment variables get cut off right when you need them.
Common RHACS CLI Failures During Incidents
roxctl auth expires daily, usually during incidents. Token refresh fails during maintenance windows.
## Keep auth token backed up
roxctl auth export --output=auth-token.json
## Direct API when roxctl breaks - replace URL with your RHACS Central endpoint
curl -k -H "Authorization: Bearer $RHACS_TOKEN" \
$RHACS_CENTRAL_URL/v1/violations
API rate limiting kicks in fast. Multiple people running roxctl triggers limits with "429 Too Many Requests" errors that don't explain how long to wait. Responses timeout on large datasets with "context deadline exceeded" after exactly 30 seconds.
Dashboard links break between versions. Saved searches don't survive upgrades. Use roxctl commands instead of UI bookmarks.