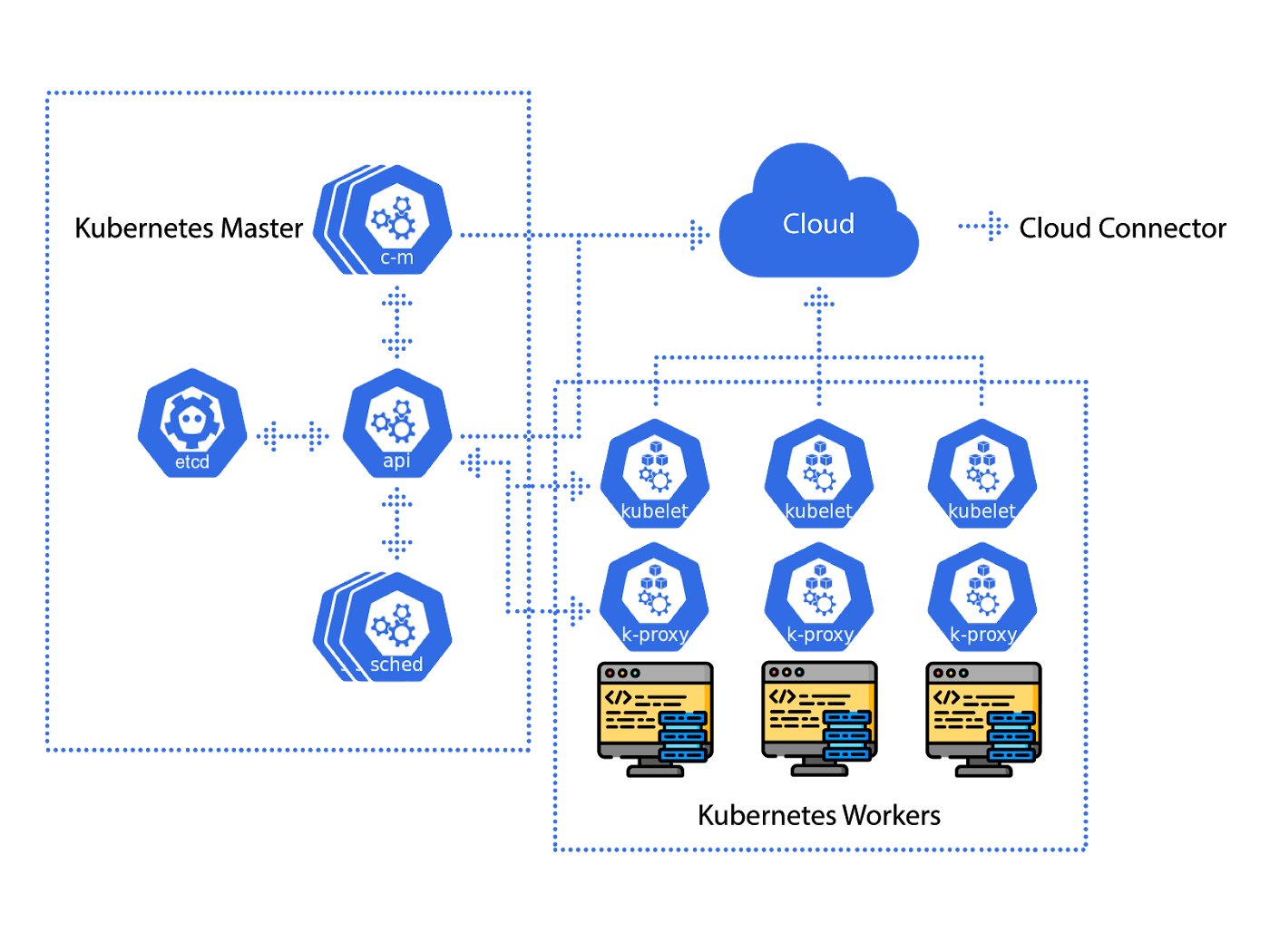
RHACS 4.8 is supposed to be more stable than previous versions, but shit still breaks in predictable ways. After dealing with dozens of production deployments, here are the issues that will ruin your week and how to fix them before your team starts planning a mutiny.
Based on Red Hat's official troubleshooting documentation and real-world incident reports from Stack Overflow RHACS discussions, these problems consistently surface in production environments.
Scanner V4 Memory Issues: The OOMKilled Nightmare
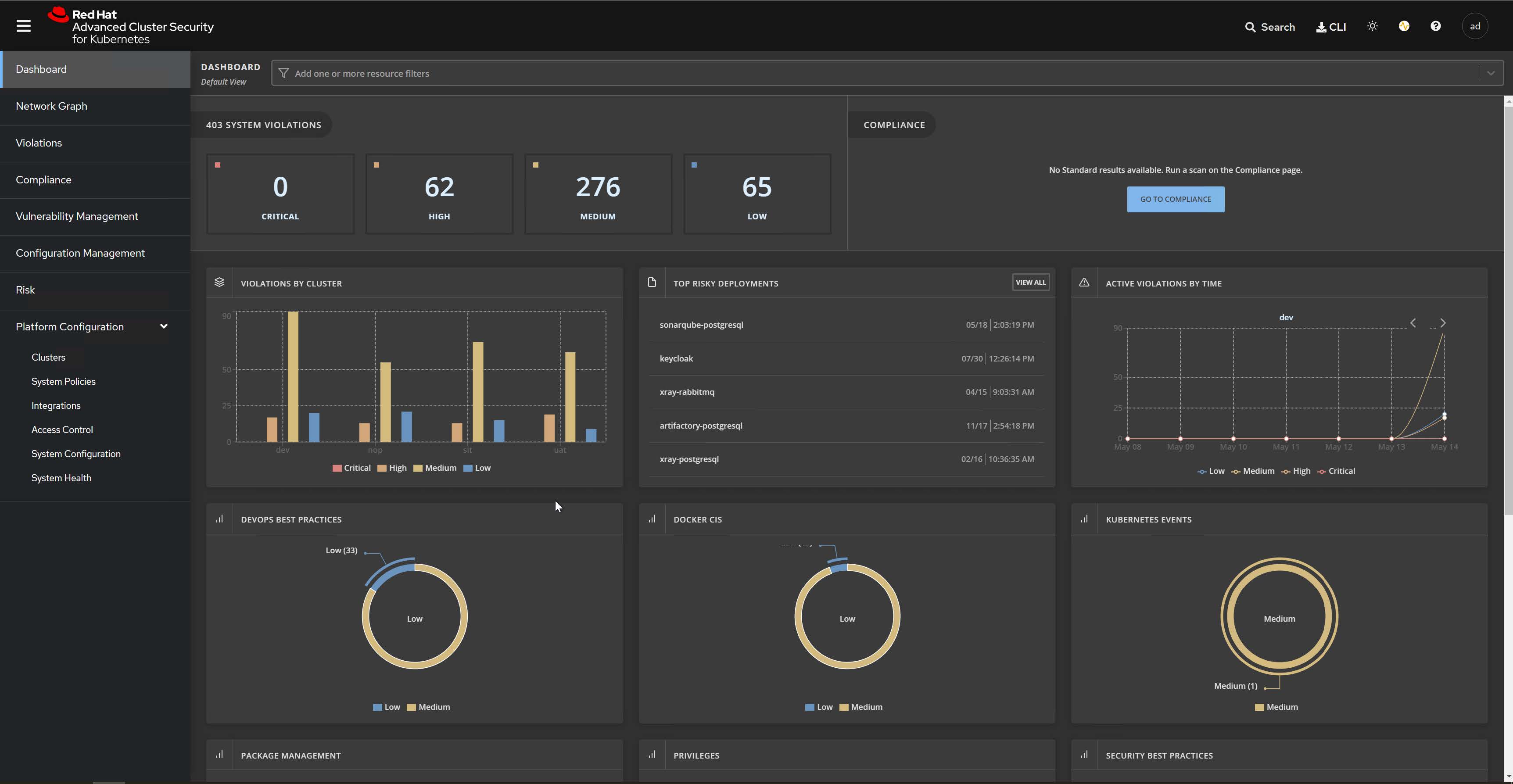
Scanner V4 became the default in RHACS 4.8, and while it's better than the old StackRox scanner that would randomly crash, it still has a healthy appetite for memory when scanning large images. According to Red Hat's RHACS 4.8 release notes, Scanner V4 supposedly improved performance, but they don't mention it'll eat 8GB RAM scanning a bloated Node.js container.
The Scanner V4 architecture guide explains the memory requirements, but production reports on GitHub show memory usage spikes during complex image analysis.
Symptoms:
- Scanner pods showing
OOMKilledstatus - Image scans timing out or failing with memory errors
- Central logs showing Scanner V4 connection failures
- CI/CD pipelines hanging on image scanning steps
The Fix That Actually Works:
Red Hat's support docs say increase memory limits, but their generic advice is useless for Scanner V4's actual requirements.
## Increase Scanner V4 memory limits in Central
apiVersion: apps/v1
kind: Deployment
metadata:
name: scanner-v4
namespace: stackrox
spec:
template:
spec:
containers:
- name: scanner-v4
resources:
limits:
memory: 8Gi # Start here, may need 16Gi for large images
cpu: 4000m
requests:
memory: 4Gi
cpu: 2000m
Pro Tips:
- Monitor Scanner V4 memory usage during peak scanning periods using Prometheus RHACS metrics
- Large images (>2GB) can spike memory usage to 10GB+ during scanning, as documented in Red Hat's sizing guidelines
- Enable delegated scanning for clusters with local registries to distribute load
- Scanner V4 database needs 50-100GB storage - Red Hat's estimates are bullshit, budget double based on community feedback
- Monitor memory spikes during busy scanning periods - I've seen 16GB disappear in minutes scanning a fat Java container
- Check RHACS memory troubleshooting guide for official Red Hat recommendations
Central Database Growth: The AWS Bill Surprise
RHACS Central uses PostgreSQL 15 as of version 4.8, and the database grows faster than your cloud bill. According to PostgreSQL 15 documentation, the latest version offers better performance, but RHACS database management practices are critical for controlling growth. The 4.8.3 release supposedly fixed a database growth bug reported in Red Hat Bugzilla, but many teams hit storage limits before applying patches.
Symptoms:
- Central pods failing with "no space left on device" errors
- Database queries timing out during compliance scans
- Exponentially growing storage costs (saw one team go from 100GB to 500GB overnight)
- PostgreSQL vacuum processes failing
Database Retention Configuration:
## Configure data retention in Central
apiVersion: v1
kind: ConfigMap
metadata:
name: central-config
namespace: stackrox
data:
retention.yaml: |
alertRetentionDays: 30 # Default 365 will bankrupt you
imageRetentionDays: 7 # Keep recent only or your storage costs will explode
auditLogRetentionDays: 90 # Compliance says 90 days, no more
processIndicatorRetentionDays: 7
Database Maintenance Commands:
## Check database size and growth
kubectl exec -n stackrox central-db-0 -- psql -U postgres -d stackrox -c "
SELECT
schemaname,
tablename,
pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) as size
FROM pg_tables
WHERE schemaname = 'public'
ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC;
"
## Manual vacuum if automatic vacuum fails
kubectl exec -n stackrox central-db-0 -- psql -U postgres -d stackrox -c "VACUUM ANALYZE;"
Network Connectivity Hell: When Sensors Go Dark
Network issues between Central and Sensors are responsible for most "RHACS is broken" tickets. Corporate firewalls, proxy configurations, and undocumented network policies will bite you. According to Kubernetes networking troubleshooting guides and OpenShift network security documentation, network configuration is often overlooked. I've seen entire deployments fail because some network admin forgot to mention the corporate proxy requires auth, which Red Hat's proxy configuration guide addresses.
Symptoms:
- Sensors appearing offline in Central console
- Inconsistent policy enforcement across clusters
- roxctl commands timing out with connection errors
- Deployment admissions failing intermittently
Network Troubleshooting Checklist:
## Test basic connectivity from Sensor to Central
kubectl exec -n stackrox sensor-xxx -- curl -k $CENTRAL_ENDPOINT/v1/ping
## Replace $CENTRAL_ENDPOINT with your actual Central endpoint URL
## Check required ports are open
## Port 443: Sensor to Central communication (mandatory)
## Port 8443: roxctl and API access (mandatory)
telnet central-endpoint 443
telnet central-endpoint 8443
## Verify DNS resolution
kubectl exec -n stackrox sensor-xxx -- nslookup central.stackrox.svc.cluster.local
## Check proxy configuration if using corporate proxy
kubectl exec -n stackrox sensor-xxx -- env | grep -i proxy
Common Network Fixes:
- Corporate Proxy Issues:
# Add proxy configuration to Sensor deployment
env:
- name: HTTPS_PROXY
value: "http://proxy.company.com:8080" - name: NO_PROXY
value: "central.stackrox.svc.cluster.local,cluster.local"
Firewall Rules:
# Required firewall rules for RHACS # Inbound to Central: 443, 8443 # Outbound from Sensors: 443 to Central # Scanner database access: 5432 (internal only)Certificate Issues:
# Check certificate validity
kubectl exec -n stackrox sensor-xxx -- openssl s_client -connect central-endpoint:443 -verify_return_error
Trust custom CA certificates
kubectl create configmap custom-ca --from-file=ca.crt=company-ca.crt -n stackrox
```
roxctl Authentication Failures: Exit Code 13 Blues
The roxctl CLI fails authentication more often than it should, usually with unhelpful error messages like "exit code 13". This breaks CI/CD pipelines and pisses off developers who just want to scan a fucking image. The roxctl CLI documentation covers authentication, but GitHub Actions integration examples and Jenkins plugin troubleshooting provide practical solutions.
Common roxctl Issues:
## Test roxctl connectivity
roxctl central whoami --endpoint $RHACS_CENTRAL_ENDPOINT --token $RHACS_API_TOKEN
## Common error: "UNAUTHENTICATED: invalid credentials"
## Solution: Token expired or has wrong permissions
Authentication Debugging:
## Check token expiration
curl -k -H "Authorization: Bearer $RHACS_API_TOKEN" \
"$RHACS_CENTRAL_ENDPOINT/v1/auth/status"
## Generate new API token with correct permissions
## Central UI → Platform Configuration → Integrations → API Token
## Required permissions: Image scanning, Policy management
CI/CD Integration Fixes:
## GitHub Actions example with retry logic
- name: RHACS Image Scan with Retry
run: |
RETRY_COUNT=0
MAX_RETRIES=3
until roxctl image scan --image $IMAGE_NAME --endpoint $RHACS_CENTRAL_ENDPOINT --token $RHACS_API_TOKEN; do
RETRY_COUNT=$((RETRY_COUNT+1))
if [[ $RETRY_COUNT -gt $MAX_RETRIES ]]; then
echo "Max retries exceeded for image scan"
exit 1
fi
echo "Scan failed, retrying in $((RETRY_COUNT * 30)) seconds..."
sleep $((RETRY_COUNT * 30))
done
Policy Enforcement Breaking Deployments
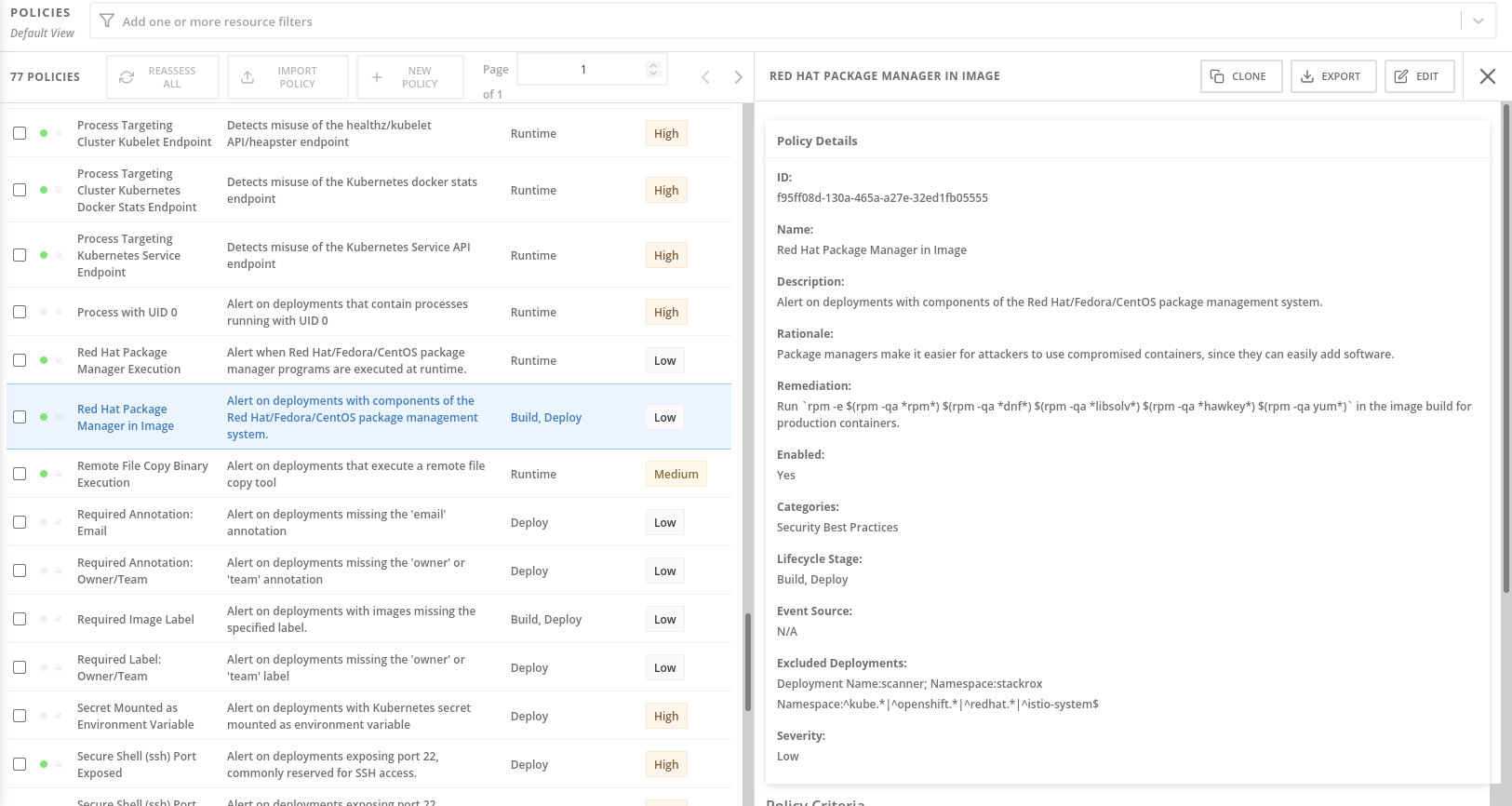
RHACS ships with 375+ security policies, and the defaults will break legitimate deployments on day one. According to the RHACS policy reference, these policies implement CIS Kubernetes Benchmark and NIST cybersecurity framework standards. The Policy as Code feature in RHACS 4.8 helps manage this chaos, but policy tuning remains an art form based on Kubernetes security best practices. I've seen teams spend weeks just trying to deploy a basic web app because policies flagged everything from root filesystem access to missing security contexts.
Policy Debugging Commands:
## Check which policies are failing
roxctl deployment check --file deployment.yaml \
--endpoint $RHACS_CENTRAL_ENDPOINT \
--token $RHACS_API_TOKEN \
--output json | jq '.alerts[] | {policy: .policy.name, violation: .violations[].message}'
## Test policy impact before enforcement
## Set policies to "inform" mode first, monitor violations for 1-2 weeks
Emergency Policy Bypass:
## Add annotation to bypass specific policies temporarily
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
admission.stackrox.io/break-glass: "emergency-deployment"
admission.stackrox.io/break-glass-justification: "Critical security patch"
spec:
# Your deployment spec
These are the issues that will make or break your RHACS deployment. When you're knee-deep in a production incident, you don't want to read through explanations - you want immediate answers. The next section covers the most common RHACS failures with quick, copy-paste solutions.