pg_basebackup is PostgreSQL's built-in backup tool that copies your entire database cluster while it's running. Sounds simple, right? Well, it is and it isn't.
pg_basebackup creates what's called a "physical backup," which means it's copying the actual data files on disk, not dumping SQL like pg_dump does. This makes it fast as hell for large databases (we're talking 500GB+ where pg_dump would take 12 hours and pg_basebackup finishes in 2), but it also means you're stuck with some annoying limitations.
The Good News
When pg_basebackup works, it fucking works. I've seen it backup a 2TB production database in under 6 hours over gigabit ethernet. Try doing that with pg_dump and you'll be waiting until next Tuesday.
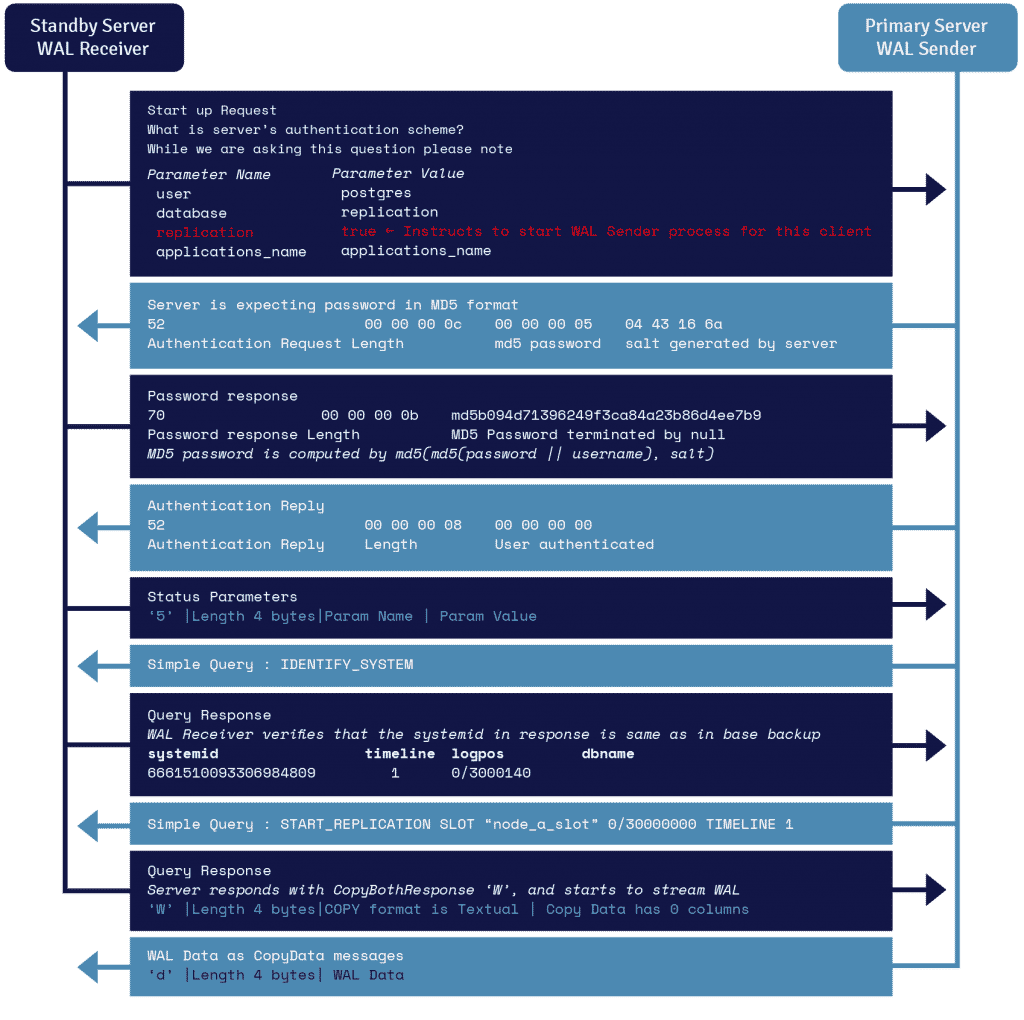
The backup happens while your database is running - no downtime, no locking users out, no "sorry the app is down for maintenance" emails. It uses PostgreSQL's replication protocol (the same one streaming replicas use) so your database thinks it's just sending data to another server.
The Reality Check
But here's where things get interesting. pg_basebackup will absolutely murder your production server's performance if you don't rate-limit it. I learned this the hard way when a 3AM backup brought our entire API to its knees because I forgot the --max-rate flag.
The tool includes WAL (Write-Ahead Log) files, which is what makes the backup consistent. Without WAL files, your backup is just a bunch of data files that were copied at different times - completely useless. The '-X stream' option streams WAL files during the backup, which doubles your network usage but prevents the "backup looks successful but is actually corrupted" nightmare.
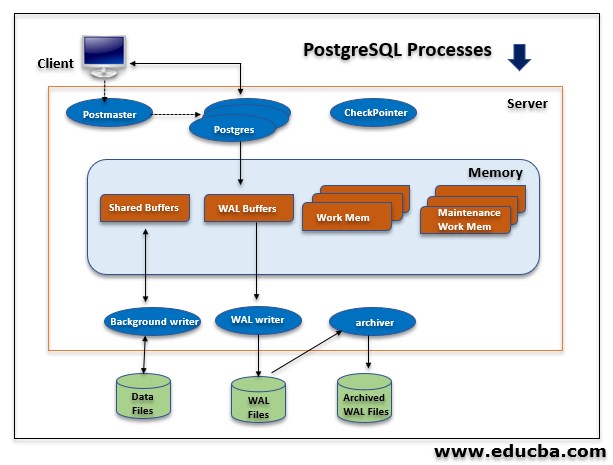
Understanding the PostgreSQL backup architecture is crucial - pg_basebackup leverages the same replication protocol used by streaming replicas, which explains why it requires replication slots and proper connection authentication.
Version-Specific Gotchas
PostgreSQL 13 changed how WAL files are named, breaking backup scripts that depended on the old naming scheme. Fun times.
PostgreSQL 14 added compression options, but the built-in compression is single-threaded and slower than just piping the output through gzip.
PostgreSQL 17 introduced incremental backups, which sound amazing until you realize they're buggy as hell and the tooling around them is still half-baked. The PostgreSQL 17 release notes detail the new features, but real-world testing shows issues with incremental manifests and block tracking overhead. Stick with pgBackRest if you need reliable incrementals.
What You Actually Get
pg_basebackup gives you either:
- A directory that looks exactly like your PostgreSQL data directory (plain format)
- A tar file containing the same (tar format)
The plain format is what you want 99% of the time. Tar format is only useful if you're copying backups around, and even then it's a pain in the ass to restore from - you have to extract the entire thing before PostgreSQL can read it.
The backup is only valid for the same PostgreSQL major version. You can't backup PostgreSQL 15 and restore it on PostgreSQL 16. That's what pg_dump is for.
Anyway, here's how to actually use this without destroying your production environment.