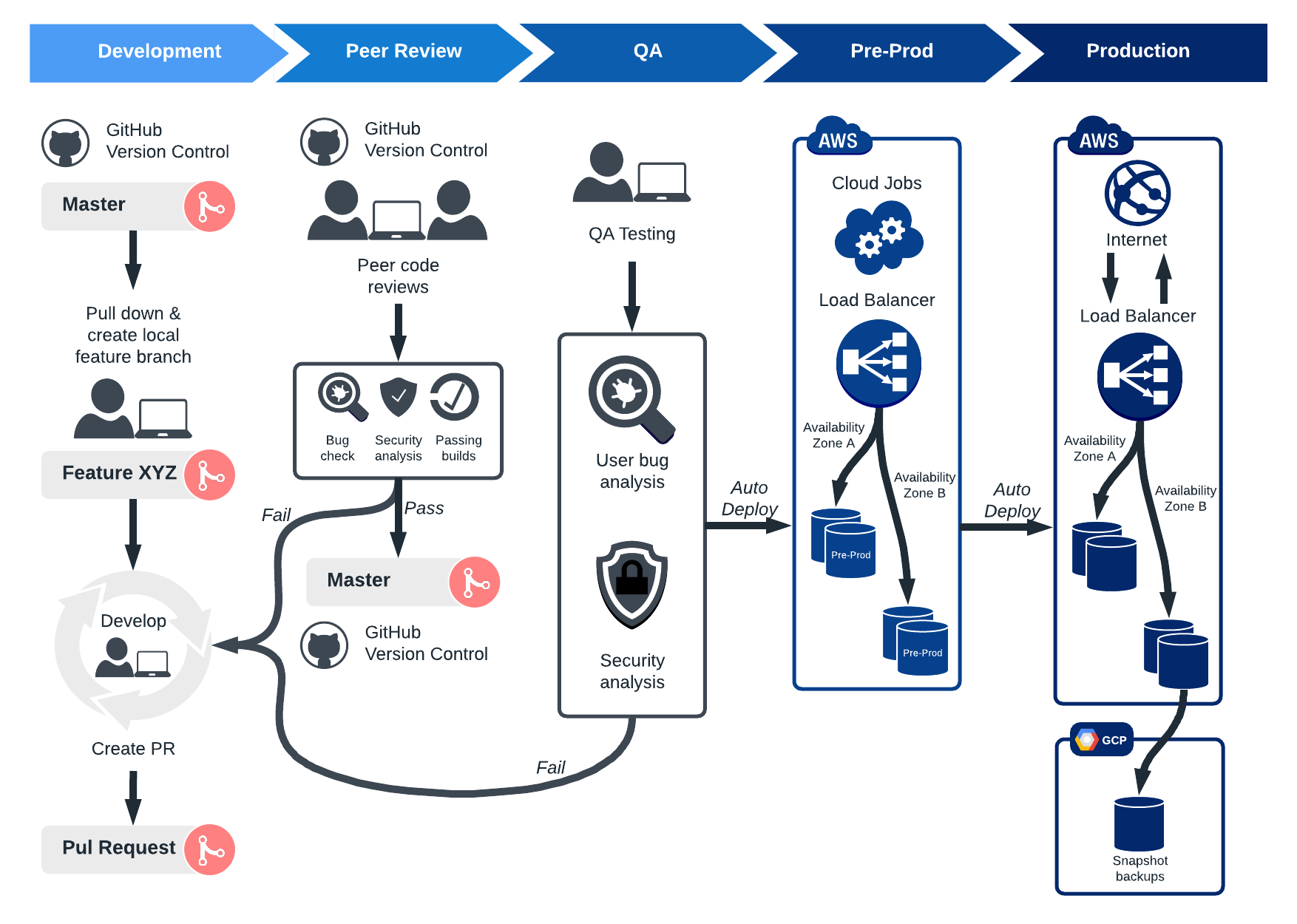
Manual deployment will slowly destroy your soul. I've watched teams waste 4 hours every Friday clicking through the same 47 fucking steps. Getting paged at 6 AM because your deployment shit the bed during "routine maintenance" isn't just unsustainable - it's what drove three engineers off our team last year.
The problem gets worse as your Mendix portfolio grows. With traditional deployment approaches, you're manually coordinating:
- Application builds across multiple Studio Pro environments
- Database migrations and dependency updates
- Configuration changes between development, staging, and production
- Rollback procedures when deployments fail
- Compliance requirements and approval workflows
Our 8-person team was spending 2.5 days per week just on deployments. That's not including the inevitable Saturday morning "why is production returning 503s" debugging sessions. When deployments shit the bed - which happened every third release - we'd blow entire weekends fixing stuff that worked fine in staging.
Why Standard CI/CD Falls Short with Low-Code
Standard DevOps tools like Jenkins, GitLab CI, or Azure DevOps can integrate with Mendix through APIs, but they require significant configuration overhead. You need to:
- Install and configure Git plugins for Mendix project structures (good luck with the XML parsing)
- Set up Maven builds with Mendix CLI or Cloud SDK
- Configure environment-specific deployment parameters (hope you like YAML)
- Handle Mendix-specific build artifacts and deployment packages
- Manage authentication and security credentials across tools (spoiler: it's a pain)
Most importantly, standard CI/CD tools don't understand Mendix's unique application model. They treat Mendix apps like traditional code repositories, missing critical low-code specific steps like model validation, dependency resolution, and platform-specific optimizations.
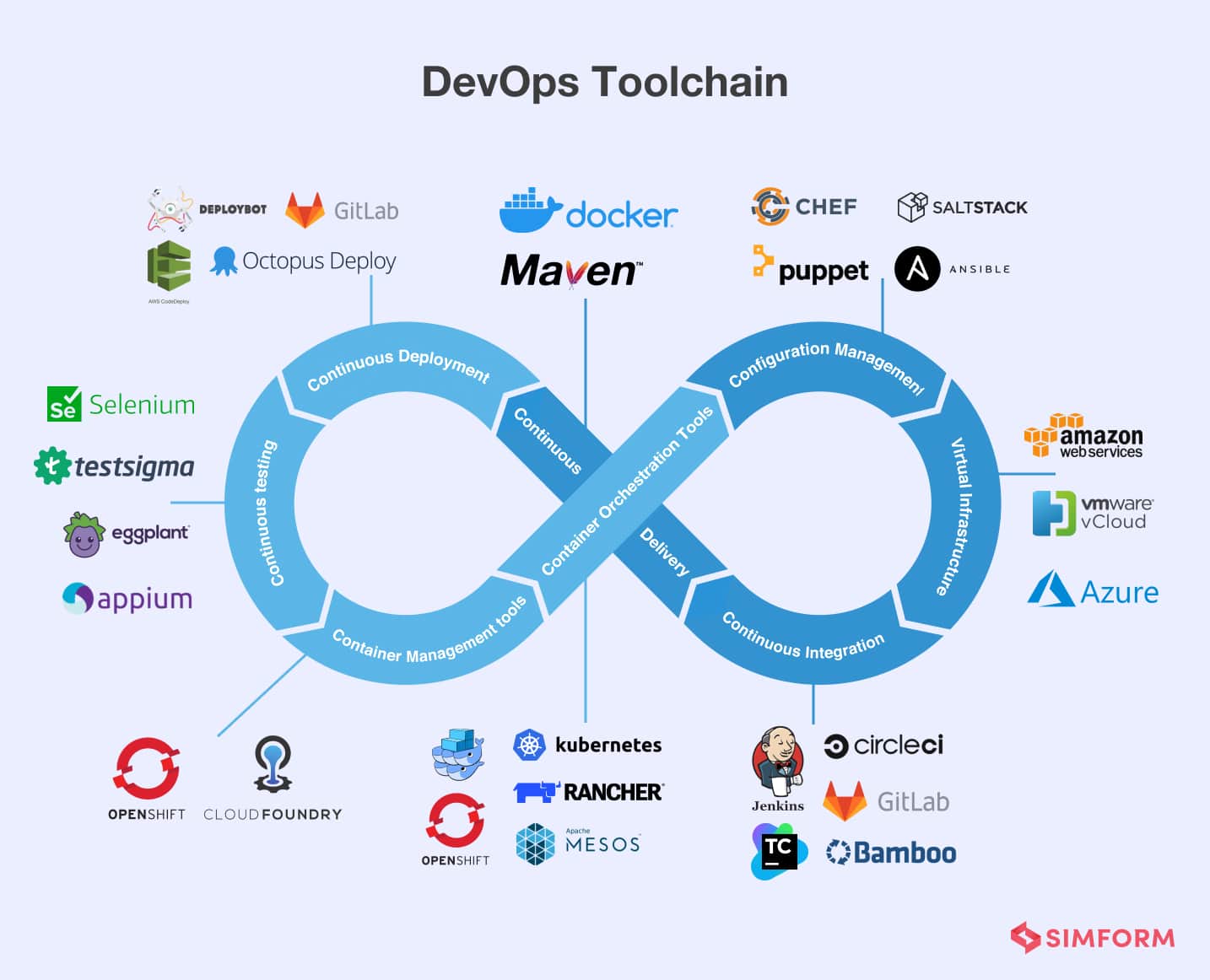
Enter Mendix Pipelines: CI/CD Built for Low-Code

Mendix Pipelines solves the low-code deployment problem by providing CI/CD automation specifically designed for the Mendix platform. Unlike generic DevOps tools, Pipelines understands Mendix application architecture natively.
Visual Pipeline Designer: Build deployment workflows using drag-and-drop components instead of writing YAML files. Configure pipeline steps like Checkout, Build, Deploy, and Backup through a visual interface that business users can understand.
Mendix-Native Intelligence: Pipelines handles the weird shit that breaks normal CI/CD:
- Model compilation and validation (translation: checks if your app is completely fucked before deployment)
- Dependency resolution when marketplace modules hate each other
- Environment configs that don't randomly break between dev and prod
- Database migrations that won't corrupt your data at 3 AM
- Platform compatibility so you don't deploy Java 11 code to Java 17 runtime
Integration with MAIA: The AI-powered Best Practices Recommender integrates directly into pipeline quality gates, catching deployment issues before they cause production failures. MAIA analyzes your application model and flags potential performance problems, security risks, or compatibility issues as an automated step in your deployment workflow.
Real-World Deployment Patterns That Work
Based on implementations at enterprise customers, these pipeline patterns deliver the best results:
Build-Test-Deploy Pipeline: Automatically triggered on Git commits. Went from 45-minute manual deployments to 8 minutes automated - when it doesn't randomly fail with Error: Build process terminated unexpectedly (exit code 137) because someone deployed during peak memory usage hours. Success rate is about 85% on weekdays, 60% on Fridays after 3 PM because apparently the build servers also hate working weekends.
Promotion Pipeline: For controlled releases between environments. Includes approval gates, automated testing, and rollback capabilities. Critical for regulated industries requiring audit trails.
Production Deployment Pipeline: Features blue-green deployments, database migration coordination, and monitoring integration. Includes automatic rollback triggers if health checks fail.
Multi-Cloud Deployment Reality
Mendix's deployment flexibility is genuine - you can run on AWS, Azure, Google Cloud, or private Kubernetes clusters. However, multi-cloud automation requires careful planning:
Cloud-Specific Considerations: Each cloud platform has unique requirements for networking, storage, and security. Pipelines can handle these differences, but you'll need separate pipeline configurations for each target environment.
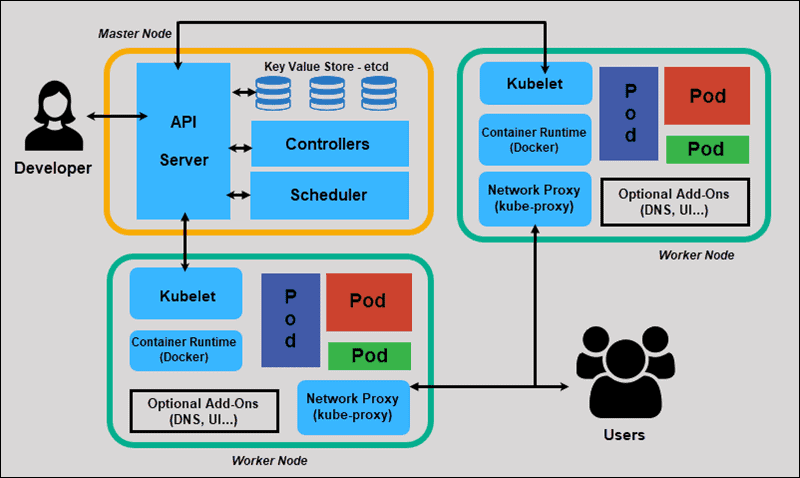
Container Orchestration: Mendix apps deploy as Docker containers, making Kubernetes deployment straightforward. The Mendix Operator handles container lifecycle management, scaling, and health monitoring.
Network and Security: Multi-cloud deployments require consistent security policies and network configurations. Plan for VPN connections, certificate management, and identity provider integration across cloud boundaries.
Multi-cloud looks sexy in PowerPoint but sucks when you're debugging network timeouts at midnight. Setup took us 6 weeks, not the "2-4 weeks" everyone promises, mostly because AWS security groups and Azure network policies hate each other. Pro tip: Keep Mendix Expert Services on speed dial because "Network error (connection timeout)" tells you nothing about which firewall rule is blocking your shit.
Version-Specific Gotchas That Will Ruin Your Day:
- Java 11 → 17 upgrade pain: Custom Java actions blow up with
java.lang.NoClassDefFoundError: org/apache/commons/lang3/StringUtils. Happened on our Mendix 10.6.0 → 10.8.1 upgrade. Fix: Update all marketplace modules OR stick with Java 11 until you have time to fix everything - Studio Pro 10.7.0 is cursed: Git sync randomly corrupts project files with "Unable to merge changes" errors. Use 10.6.3 or wait for 10.8.x. Trust me on this one
- Kubernetes 1.28+ security contexts: New securityContext requirements break Mendix containers. You'll get
container has runAsNonRoot and image has non-numeric user (mendix), cannot verify user is non-rooterrors - Build API timeout changes: Mendix Cloud changed timeout from 30 to 15 minutes in late 2024. Long builds now fail with "Build exceeded maximum duration" - optimize your build process or cry