I spent my first three years deploying manually like a fucking caveman. Every Friday became a nightmare because someone would inevitably push a "quick fix" that broke everything. Here's what manual deployment hell looks like:
![]()
You ssh into the production server. You pull the latest code. You restart services in the right order (you think). Something breaks. You spend two hours figuring out which of the 47 changes deployed since last Tuesday caused the issue. Users are pissed. Your weekend is ruined.
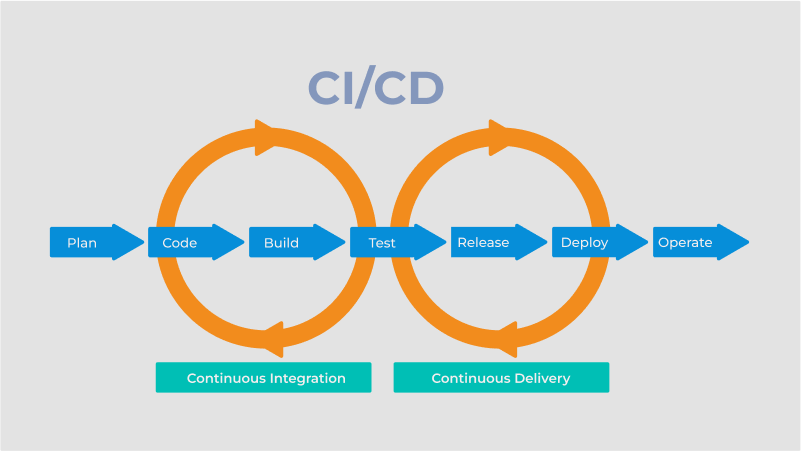
The Three Ways to Not Screw Yourself
Continuous Integration means your code gets built and tested every time someone pushes. No more "it works on my machine" bullshit. If the tests fail, the build fails. If the build fails, no one can deploy broken code to production.
I learned this the hard way when our team lead pushed code that compiled fine on his MacBook but failed on our Ubuntu production servers. The fix? CI builds on the same OS as production. Problem solved.
Continuous Delivery means your code is always ready to deploy, but you still need to click a button. It's CI plus automatic deployment to staging. You get to test the real deployment process without risking production.
Continuous Deployment is for teams with their shit together. Code goes straight to production after passing tests. Sounds scary, but it's actually safer than manual deployment because you're forced to have good tests and monitoring.
Why Most Teams Fuck This Up
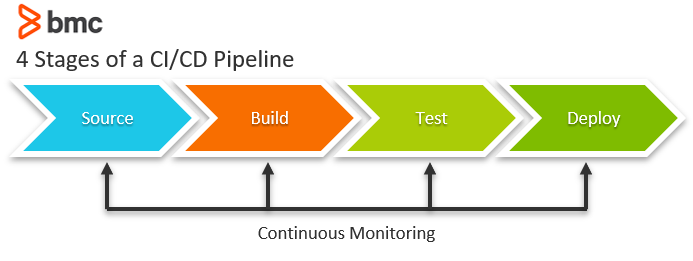
Most companies buy a CI/CD tool and expect magic. They don't realize that you can't just automate broken processes and expect good results. Here's what I've seen go wrong:
![]()
Your Tests Suck: You set up CI but your test coverage is 12% and half the tests are flaky. Now your pipeline fails randomly and everyone ignores the red builds. Congrats, you've automated failure.
I worked on a team where tests failed every fucking Tuesday because they depended on some external API that went down for maintenance. Took us three weeks to figure out why our "reliable" test suite had a 50% success rate on Tuesdays. The solution wasn't better CI - it was mocking the API calls using tools like WireMock or MSW.
Environment Differences: Your app works locally, passes CI, then crashes in production with ECONNREFUSED 127.0.0.1:5432 because production has PostgreSQL 12 while your local setup has PostgreSQL 14. This exact bullshit cost me an entire Saturday debugging connection issues and getting yelled at by the on-call manager. Docker containers fix this, but only if you actually use the same container in all environments instead of the classic "oh it's just a small difference, what could go wrong?"
I learned this when our app worked perfectly until we deployed and got Error: relation "users_new_column" does not exist because production was running PostgreSQL 12.8 while local/CI used 14.2. The migration scripts behaved differently between versions. The fix: containerize everything with docker-compose up using identical versions:
## docker-compose.yml
version: '3.8'
services:
postgres:
image: postgres:12.8-alpine # Exact prod version
environment:
POSTGRES_DB: myapp
POSTGRES_USER: postgres
POSTGRES_PASSWORD: localpass
Database migration tools like Flyway prevent these disasters by versioning your schema changes.
![]()
No Rollback Plan: You can deploy in 30 seconds but it takes 2 hours to roll back when shit hits the fan. I've watched teams frantically running git log --oneline | grep -v "fix" | head -20 trying to figure out which commit broke prod while customers are losing their minds on Twitter and the CEO is blowing up Slack asking why our "deploy fast" strategy doesn't include an "unfuck production fast" button.
Real CI/CD includes automated rollback. Here's what works:
Kubernetes rollback: kubectl rollout undo deployment/myapp brings back the previous version in under 30 seconds. Check rollout status with kubectl rollout status deployment/myapp --timeout=300s.
Docker with specific tags: Never use latest. Tag builds with git commit SHA: myapp:a1b2c3d4, then rollback becomes docker service update --image myapp:previous-working-sha my-service.
Database rollbacks: This is where most teams fuck up. You can't just rollback code if your schema changed. Use Flyway repair for forward-only migrations or have dedicated rollback scripts.
Blue-green deployments aren't fancy - they're survival tools for when your users are on Twitter complaining.
The Tools That Don't Completely Suck
Jenkins: Maximum flexibility, maximum pain. You can make it do anything, but you'll spend weekends maintaining plugins and dealing with security updates. Jenkins still has 45% market share because it works, even if it's a maintenance nightmare.
GitHub Actions: Simple to set up if your code is already on GitHub. Works great until you need anything more complex than "run tests, deploy to Heroku." The minute pricing will surprise you once you have real builds - check out the Actions marketplace for pre-built workflows.
GitLab CI: Pretty solid if you don't mind vendor lock-in. The integrated approach means less configuration hell, but good luck migrating if you ever want to leave. Their CI/CD templates save setup time.
Look, setting up the pipeline isn't what's killing you. The real problem is you're trying to automate a deployment process that was already completely fucked. You can't just throw GitHub Actions at broken shit and expect it to magically start working. Fix your process first, then automate it.