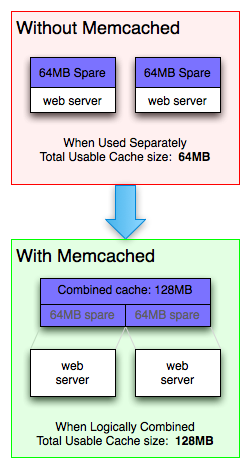
Memcached doesn't try to be clever. You stick data in RAM, you get it back fast. Brad Fitzpatrick wrote it in 2003 because LiveJournal's database was getting hammered by the same queries over and over. Instead of making the database cry, cache the results in memory. Revolutionary? No. Effective? Absolutely.

The "Shit, Our Database is Slow" Problem
Here's the thing - MySQL starts choking when you hit it hard enough with complex queries and high load. PostgreSQL handles more but still hits walls. Your database is designed for consistency and durability, not raw speed. So when your homepage makes 20 database calls and takes 2 seconds to load, that's not a database problem - that's a caching problem.
Had this exact problem at a startup - some Reddit post about our product hit the front page and our single MySQL instance just gave up. Couldn't remember the exact user count, but our monitoring showed database response times going from 50ms to 8 seconds. Threw Memcached in front of the product queries and bought ourselves time to fix the real problem. Setup took 45 minutes because I kept fucking up the cache key naming.
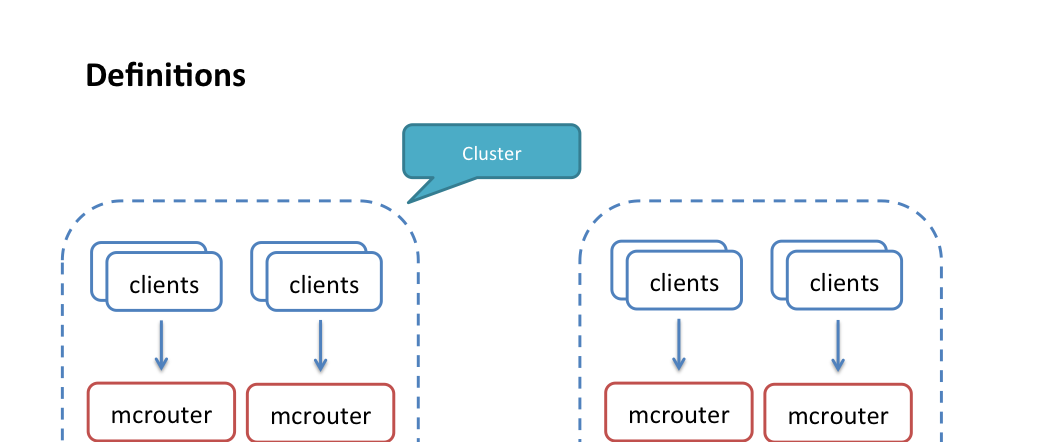
The Architecture is Stupidly Simple
Memcached servers don't talk to each other. At all. No clustering, no replication, no coordination. Your client library handles everything using consistent hashing. You hash your key, pick a server, done.
## This is literally all the complexity there is
telnet localhost 11211
set mykey 0 3600 5
hello
STORED
get mykey
VALUE mykey 0 5
hello
END
When a server dies, the client just redirects those keys to other servers. You lose that cached data, but cache is supposed to be disposable. If losing cache breaks your app, you're doing it wrong. Learned this when our primary Memcached node crashed at 2am and logged out 80% of our users because some genius was storing sessions without fallback to the database.
Memory Management (LRU or GTFO)
Memcached uses slab allocation which sounds fancy but isn't. It pre-allocates memory chunks of different sizes (64 bytes, 128 bytes, 256 bytes, etc.). When you store data, it goes in the smallest chunk that fits. This prevents memory fragmentation that would otherwise fuck you over after running for weeks.
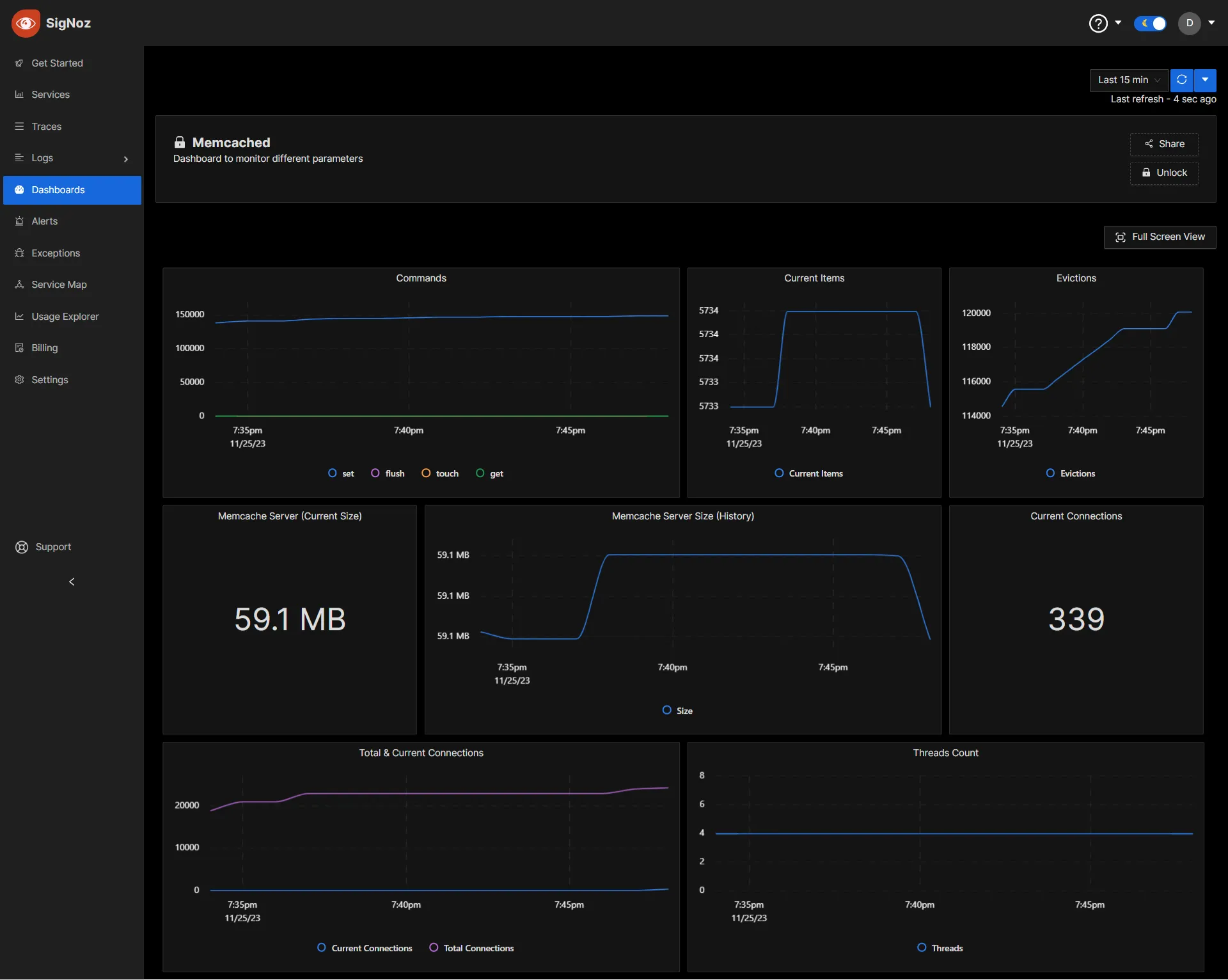
When memory fills up, LRU eviction kicks in. Least recently used data gets booted. No configuration needed - it just works. Want to see what's getting evicted? Check stats evictions and cry if it's high.
Performance Reality Check
The benchmarks claim 200K ops/sec, and they're not lying - on perfect hardware with perfect network conditions. In the real world:
- Your cloud VM with shared networking: 50K ops/sec if you're lucky
- Decent dedicated hardware with 1Gb network: 100K-150K ops/sec
- High-end server with 10Gb network: Yeah, you might hit 200K+ ops/sec
Sub-millisecond latency is real though. I've measured 0.1-0.5ms response times consistently on production systems. Compare that to database queries that take 5-50ms and you understand why caching works.
The multi-threaded model means you can use multiple CPU cores, unlike Redis which is single-threaded for data operations. More cores = more throughput, up to network limits.
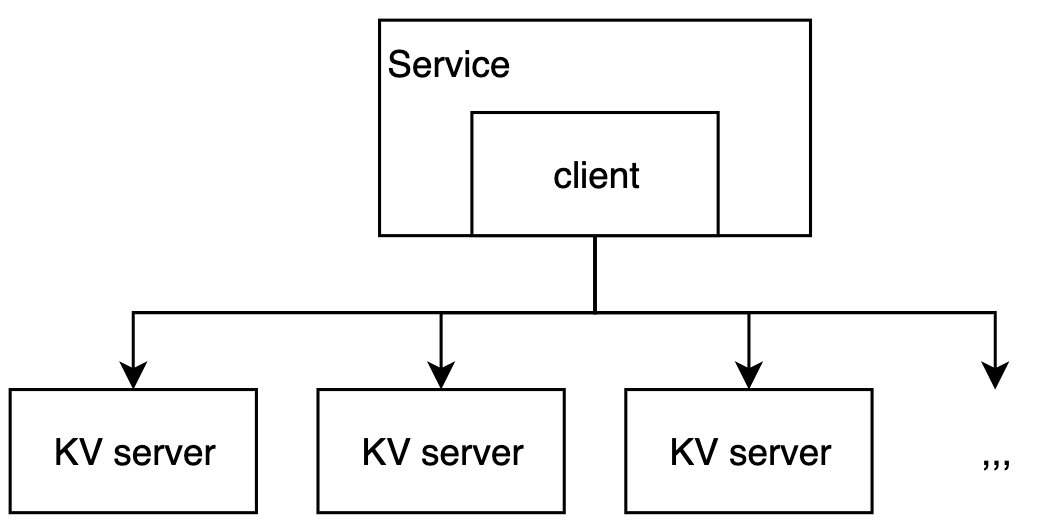
The Protocol (So Simple You Can Debug It With Telnet)
The text protocol is human-readable, which is amazing for debugging. When something's broken at 3am, you can literally telnet to port 11211 and see what's happening:
## Debug like a human
echo \"stats\" | nc localhost 11211
## See your hit rate, memory usage, connections, everything
Client libraries exist for every language that matters: Python, PHP, Java, Node.js, Ruby, Go, .NET, Rust. They all work the same way because the protocol is simple.