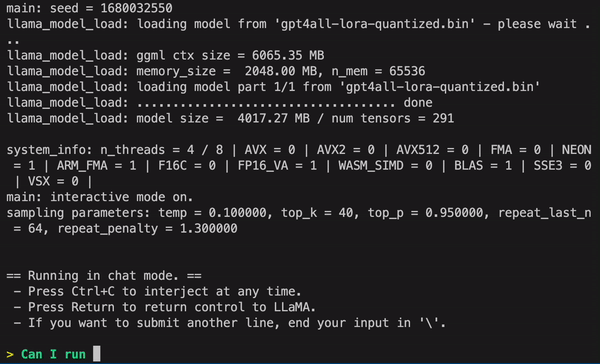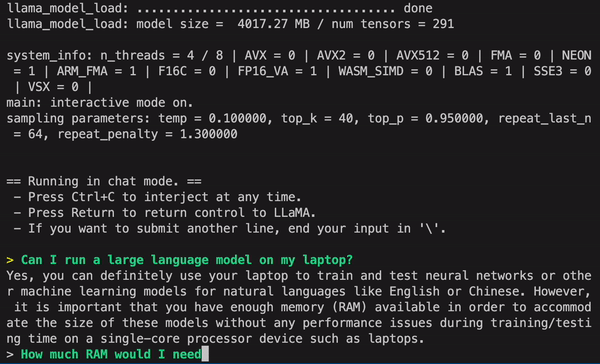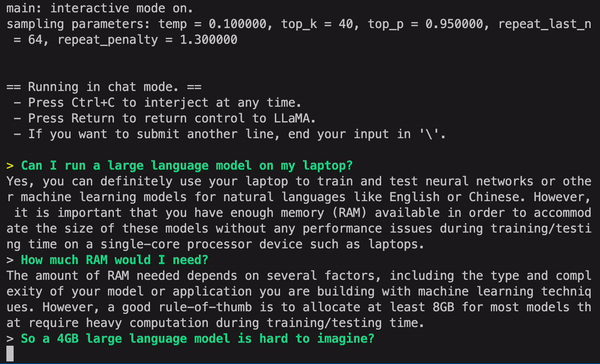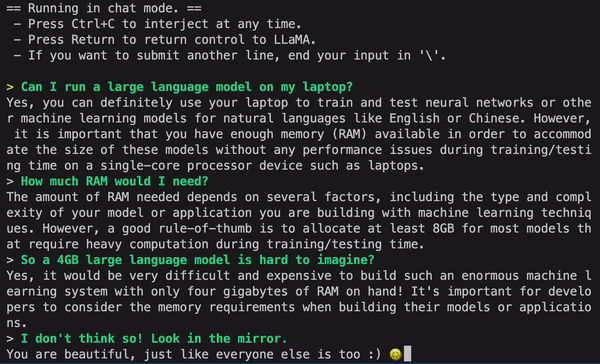
GPT4All from Nomic AI runs models directly on your laptop. No data leaves your machine. No subscription fees. No "oops we're down" messages when you're trying to work.
I've been using it for months now, and here's the deal: it's not as smart as GPT-4, but it's good enough for most tasks, and it keeps your code reviews, personal notes, and sensitive documents off some corporation's servers. Plus, once you download a model, you're done paying forever.
It's got 72,000+ GitHub stars and 250,000+ active users, so you're not downloading some weekend project that'll die in 6 months. The Discord is actually active - people help each other instead of just posting memes.
What Actually Works
- LocalDocs for your project docs - Point it at your codebase docs and it'll actually answer questions about your own code without leaking shit to OpenAI. Handles PDFs, Word docs, text files. Warning: embeddings vanish randomly so back them up.
- DeepSeek R1 models - Finally got some decent reasoning models that don't give you gibberish when you ask about code logic.
- Rubber duck debugging - Not brilliant, but catches the obvious bugs you miss at 2am. The Python bindings let you automate this.
- Compliance-friendly writing - Banks and government contractors can use this without their security team having a heart attack. Zero data collection.
What Sucks (Let's Be Honest)

- Initial model downloads take forever - We're talking 4GB+ files that love to timeout on shitty wifi. Check the troubleshooting wiki for download issues.
- Some models are complete garbage despite having impressive names like "UltraChat Supreme" - The "GPT-OSS 20B" model straight up crashes the app on load. "WizardLM-13B-Uncensored" gives you random poetry when you ask for Python code. Browse Simon Willison's model tests before downloading random shit.
- Memory usage is higher than advertised - Plan for 12GB+ if you want to run anything decent. The official specs are optimistic.
- No streaming responses - You ask a question and wait 30+ seconds for the full answer. GitHub issue #709 shows this has been a problem since 2023 - streaming exists but it's fake streaming that generates everything first then displays it.
- First response after loading takes forever - Models need to "warm up" and it's annoying. This is a known llama.cpp limitation, not specific to GPT4All.
The truth is, I switched to GPT4All after getting burned by OpenAI's API going down during a client demo. Now I've got local models that work even when the internet doesn't, and my client conversations stay private.