Today is Friday, September 6, 2025. Based on this current date, JupyterLab 4.4.7 is the latest stable version (released September 3, 2025), with JupyterLab 4.5.0 development versions available. Here's how to install it without the common headaches that frustrate beginners.
The Installation Methods That Don't Suck
Method 1: Conda (Recommended for Beginners)
Conda manages both Python and system dependencies, making it the safest choice for data science environments:
## Install Miniconda first if you don't have it
conda install -c conda-forge jupyterlab
## Or with mamba (faster)
mamba install -c conda-forge jupyterlab
Why conda over pip? Data science packages like NumPy, SciPy, and scikit-learn have complex dependencies that conda handles automatically. Pip can create dependency hell when packages require different versions of the same library.
Method 2: Pip (If You Know What You're Doing)
## Create a virtual environment first (CRITICAL)
python -m venv jupyterlab-env
source jupyterlab-env/bin/activate # On Windows: jupyterlab-env\Scripts\activate
pip install jupyterlab
Never install with system pip unless you want to break your Python installation. Virtual environments isolate JupyterLab from system Python and other projects. Learn more about Python environment best practices.
Method 3: Docker (For Consistent Environments)
Docker provides identical environments across different systems:
## Pull the official image with common data science packages
docker run -p 8888:8888 jupyter/datascience-notebook
## For production or team use
docker run -v "${PWD}":/home/jovyan/work \
-p 8888:8888 \
jupyter/datascience-notebook start-notebook.sh \
--NotebookApp.token=''
Jupyter Docker Stacks provide pre-configured images with different package combinations.
Your First JupyterLab Session
Once installed, starting JupyterLab is straightforward:
jupyter lab
This command:
- Starts a local server (usually on
http://localhost:8888) - Opens JupyterLab in your default browser
- Displays a security token for authentication
If the browser doesn't open automatically, copy the URL from the terminal output. It looks like: http://localhost:8888/lab?token=abc123...
Understanding the JupyterLab Interface
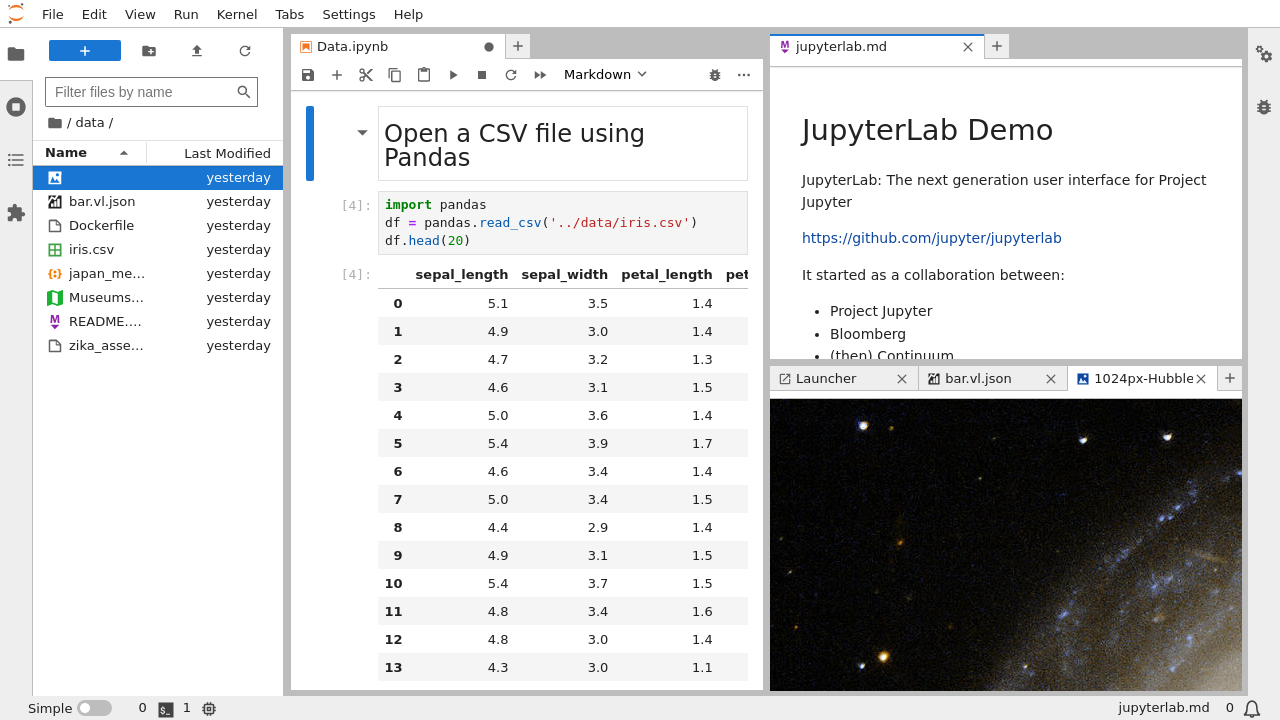
JupyterLab's interface consists of:
Left Sidebar: File browser, running kernels, Git integration (with extension), variable inspector (with extension)
Main Work Area: Notebooks, code files, terminals, and custom panels in tabs and split views
Right Sidebar: Property inspector, debugger (when enabled), table of contents
Menu Bar: File operations, edit functions, view options, kernel management
The official interface guide provides comprehensive details, but the basic layout is intuitive for most users.
Configuration for Productive Workflows
Essential Settings Adjustments
Access settings through Settings → Settings Editor:
- Increase output limits: Notebook → Rendering → Max Output Size → 10MB (default 1MB causes truncation)
- Enable line numbers: Code Console → Show Line Numbers → Always
- Autosave frequency: Document Manager → Autosave Interval → 60 seconds (default 120)
- Theme selection: JupyterLab Theme → Light/Dark based on preference
Keyboard Shortcuts That Matter
Ctrl/Cmd + S: Save (muscle memory essential)Ctrl/Cmd + Enter: Run cell and stayShift + Enter: Run cell and advanceAlt + Enter: Run cell and insert belowCtrl/Cmd + Shift + P: Command palette (find any function)
The keyboard shortcuts reference covers advanced shortcuts, but these five handle 90% of daily usage.
Project Organization Best Practices
Create a logical folder structure from day one:
my-data-project/
├── data/
│ ├── raw/ # Original, immutable data
│ ├── processed/ # Cleaned data
│ └── external/ # Downloaded datasets
├── notebooks/
│ ├── 01-exploration/
│ ├── 02-cleaning/
│ └── 03-analysis/
├── src/ # Reusable Python modules
├── reports/ # Final outputs
└── requirements.txt # Package dependencies
This structure, recommended by Cookiecutter Data Science, prevents the common mistake of dumping everything in one folder.
Version Control Integration
Install jupyterlab-git for visual Git integration:
pip install jupyterlab-git
## Restart JupyterLab to see Git tab in left sidebar
Use nbstripout to remove output from notebook commits:
pip install nbstripout
nbstripout --install # Configure for current repo
This prevents massive diffs when notebooks contain plots or large outputs.
Common Beginner Mistakes to Avoid
Mistake 1: Running Everything in the Base Environment
Installing packages directly affects all projects. Always use virtual environments or conda environments for project isolation.
Mistake 2: Not Restarting Kernels
Variable definitions accumulate during development. Restart kernels regularly to ensure your notebook runs from a clean state:
- Kernel → Restart Kernel and Clear All Outputs
Mistake 3: Ignoring Resource Monitoring
Install jupyter-resource-usage to see memory and CPU usage:
pip install jupyter-resource-usage
## Restart JupyterLab to see resource monitor in status bar
This prevents surprise kernel crashes from memory exhaustion.
Mistake 4: Poor Notebook Organization
Keep notebooks focused and linear. If your notebook has more than 50 cells or scrolls for minutes, split it into multiple focused notebooks.
System Requirements and Performance Expectations
Minimum System Requirements:
- 4GB RAM (8GB recommended for medium datasets)
- 2GB free disk space for installation
- Modern browser (Firefox, Chrome, Safari, Edge)
- Python 3.8+ (Python 3.12 recommended as of 2025)
Performance Expectations:
- Small datasets (< 100MB): Responsive on any modern system
- Medium datasets (100MB - 1GB): Requires 8GB+ RAM for comfortable usage
- Large datasets (1GB+): Consider Dask, Polars, Apache Spark, or cloud computing platforms
The JupyterLab performance guide provides optimization techniques for resource-constrained environments.
When to Choose JupyterLab vs Alternatives
Choose JupyterLab for:
- Interactive data exploration and analysis
- Research and educational workflows
- Multi-language data science (Python, R, Julia, SQL)
- Collaborative computational research
- Prototyping machine learning models
Consider alternatives for:
- VS Code: General software development, larger codebases
- PyCharm: Complex Python applications, enterprise development
- RStudio: R-focused statistical analysis
- Google Colab: Quick experiments, free GPU access
- Databricks: Enterprise big data analytics
The choice depends on your workflow, team requirements, and computational needs. JupyterLab excels at interactive analysis but isn't optimal for all development scenarios.
Your first JupyterLab experience should focus on learning the interface and establishing good practices. The advanced features and extensions come later - start with a solid foundation.