I've been running Feast in production since 0.47 and let me tell you - it was a fucking nightmare until recently. The recent 0.53.x versions have been way more stable than the 0.52.x shitshow. We finally stopped getting silent materialization failures that cost us 2 weeks of debugging and a very angry VP of Engineering.
What Actually Changed in 2025
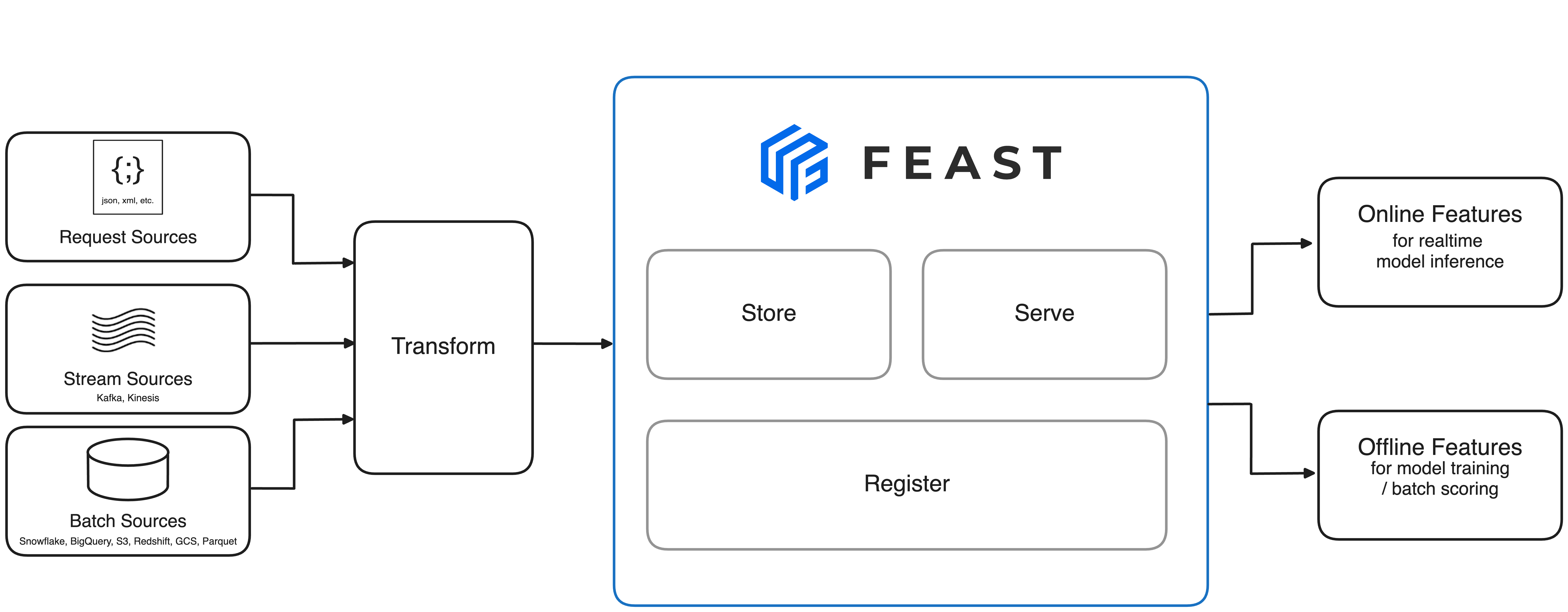
![]()
Look, Feast went from "experimental toy that breaks constantly" to "production infrastructure that only breaks occasionally." Here's what happened:
Canonical Charmed Feast dropped on July 10, 2025 and it's basically "Feast but someone else deals with the 3am alerts." If you can afford enterprise support (probably more than their initial $100k+/year estimate once they see your actual usage), worth investigating. Ubuntu people know how to package software properly.
Recent versions actually work: The 0.53.x releases fixed a bunch of shit that made 0.52.x unusable:
- Silent materialization failures finally scream at you instead of eating your data
- Memory leaks that killed our weekend deployments seem to be fixed (knock on wood)
- Connection pooling doesn't completely shit itself under load anymore
- You get actual Prometheus metrics instead of guessing why things are slow
I upgraded from 0.52.2 and didn't lose data for the first time in 6 months. Could be luck, but I'll take it.
The Vector Search Thing
In March 2025 they added alpha vector search support for RAG applications. It's alpha quality so don't put it in production yet, but the idea is solid - combine your feature store with vector similarity search so you don't need separate systems.
The Milvus integration works for document retrieval if you have under 100M vectors. Above that, you're back to managing separate systems anyway. For production vector search, stick with Pinecone, Weaviate, or Qdrant until Feast's integration matures. The Feast roadmap shows they're working on better vector database support, but it'll be months before it'll be production-ready.
Performance Improvements That Matter
Dragonfly replaced Redis in our setup and holy shit the difference is real. Redis was choking around 50k ops/sec. Dragonfly handles way more - I've seen it do 300k+ ops/sec on the same hardware, sometimes more depending on the workload. Your mileage will vary but it's night and day. It's Redis-compatible so you just change the connection string and suddenly your feature serving doesn't suck. Check the Dragonfly performance benchmarks and Redis comparison results for detailed numbers.
DuckDB for offline stores makes sense if your historical data is under 10TB. We saved a shit-ton of money switching from BigQuery to DuckDB. I think it was like 8-12k per month? Maybe more during heavy query months. Queries are actually faster and setup takes an hour instead of configuring IAM hell. The DuckDB integration guide walks through the setup, and performance comparisons show why it beats traditional data warehouses for smaller datasets. Consider MotherDuck for managed DuckDB if you want the performance without the ops overhead.
The Three Deployment Patterns That Work
Cloud-Native (What Everyone Does):
- Kubernetes + BigQuery/Snowflake + Redis/DynamoDB
- Costs $15k-30k/month at scale but battle-tested
- Good if you already have cloud ops teams and existing Kubernetes infrastructure
Enterprise Supported (New in 2025):
- Charmed Feast + on-premises or cloud
- $100k+/year but includes enterprise support and SLAs
- Makes sense if compliance matters more than money and you need 24/7 support
High-Performance (For When Latency Matters):
- DuckDB + Dragonfly + bare metal or cloud VMs
- Sub-millisecond P99 latency, costs 50% less than cloud
- Requires actual infrastructure engineering and performance tuning expertise