Your data scientist runs some version of TensorFlow on their MacBook.
Production runs a different version on Ubuntu with way more RAM. The model works perfectly in the notebook and crashes immediately in production with CUDA_ERROR_OUT_OF_MEMORY. Sound familiar?
That's the bullshit Kubeflow tries to solve
- making your dev environment match production by forcing everything through Kubernetes.
Problem is, now you have ML complexity plus K8s complexity. It's like solving a math problem by adding more math.
What Each Component Actually Does

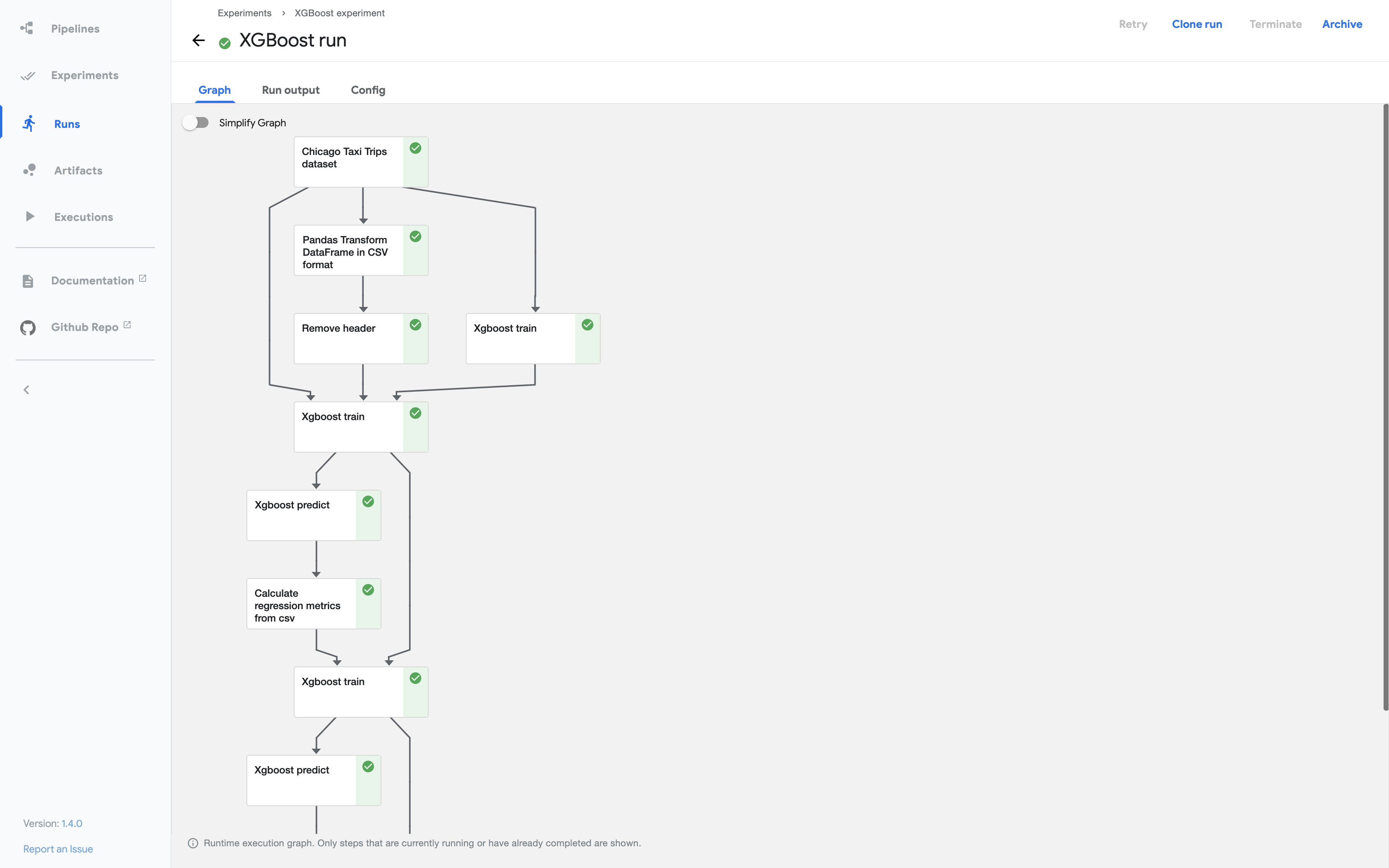
Kubeflow Pipelines
- DAG runner for ML workflows.
You define steps in Python, it runs them in order. Works most of the time. When it doesn't, you'll grep through logs looking for connection timed out errors because the API server is flaking out again.

Training Operator v1.8.0 (v1.9 broke our distributed training setup)
- Distributed training across GPUs.
Supports Py
Torch, TensorFlow, JAX when the planets align. Here's the gotcha: if you don't set memory limits, one job will OOM the entire node and kill everyone else's work.
Ask me how I fucking know.
Pro tip: Always check kubectl describe pod first.
The events section has the real error, not the useless logs.
![]()
KServe
- Model serving that auto-scales when it feels like it.
Way better than writing another Flask wrapper. Handles A/B testing and canary deployments when it's not randomly restarting pods for no reason. The docs miss half the production gotchas but what else is new.
Katib
- Hyperparameter tuning using actual algorithms instead of grid search. Saves you from manually testing 200 learning rates. Uses Bayesian optimization which sounds fancy but really just means "slightly smarter guessing." No idea why this works but don't touch it.
Security Is Your Problem Now
Multi-tenancy means teams can't break each other's stuff. You set up RBAC and Network
Policies, which takes 40+ hours if you want to get it right.
Get it wrong and the intern accidentally deletes prod models.
GPU scheduling is where dreams go to die. Your job shows Pending because the node has a taint you didn't know about. Or the NVIDIA drivers crashed again. Or someone else is hogging all the A100s for their "urgent" hyperparameter search that definitely could have waited.
The Real Decision Tree
Use this if:
- You already run Kubernetes (and someone knows how to debug it)
- Compliance won't let you use cloud services
- You have 2+ DevOps people who don't mind getting paged at 3am
- You need weird custom ML workflows
Run away if:
- You just want to deploy a model (SageMaker exists for a reason)
- Your team is small and wants to focus on actual ML
- You're a startup trying to move fast
- You like having weekends
Current version is 1.8-something which is "stable" in the sense that it breaks in predictable ways. Setup still takes forever and will definitely ruin multiple weekends.