Machine learning has a dirty secret: most models work great in Jupyter notebooks and completely shit the bed in production.
The reason? Training uses different data than inference, and you won't notice until your fraud detection model starts flagging every transaction as suspicious.
The Real Problem: Feature Inconsistency
I've seen it dozens of times.
Data scientist builds a model using SQL queries that aggregate "transactions in the last 7 days." Works perfectly. Then engineering rebuilds the feature pipeline using different logic, different timestamps, different database queries. Same feature name, completely different values.
Result? Your model's accuracy drops from 95% to 72% and you spend three weeks debugging why production predictions are garbage.
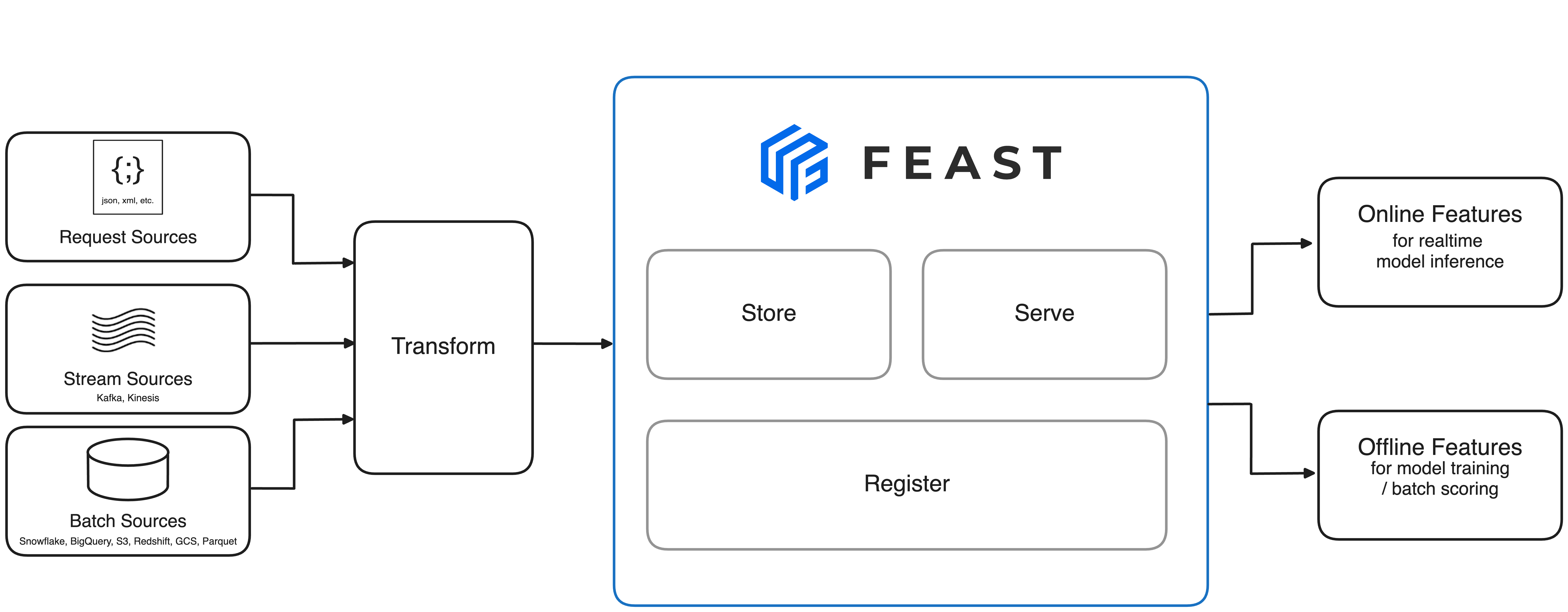
What Feast Actually Does
Feast has 6.3k GitHub stars and was started by engineers at Gojek who got tired of rebuilding the same features over and over. It's basically three things:
Feature Registry:
A catalog of every feature definition so you can't accidentally create "user_age" and "customer_age" that mean the same thing.
Offline Store: Where historical features live for training.
Connects to your data warehouse (Big
Query, Snowflake, whatever you're stuck with).
Online Store: Fast key-value store (Redis, DynamoDB) that serves features in under 10ms for real-time predictions.

The Point-in-Time Correctness Thing
This is the feature that saves your ass.
When you're training on historical data, Feast makes sure you only use features that existed at that exact timestamp. No future data leakage, no accidentally perfect models that break in production.
Without this, you'll train on tomorrow's data to predict yesterday's events and wonder why your model is too good to be true.
Real Talk: Do You Actually Need This?
If you're building a single model with static features, probably not. Just use a database.
You need Feast if:
- Multiple models share the same features
- You have real-time inference requirements
- You've been burned by training-serving skew before
- Your team rebuilds the same features in different languages
Current version is 0.53.0 as of August 2025. Setup takes about a week if everything goes right, three weeks if you hit the usual Docker/networking issues.
