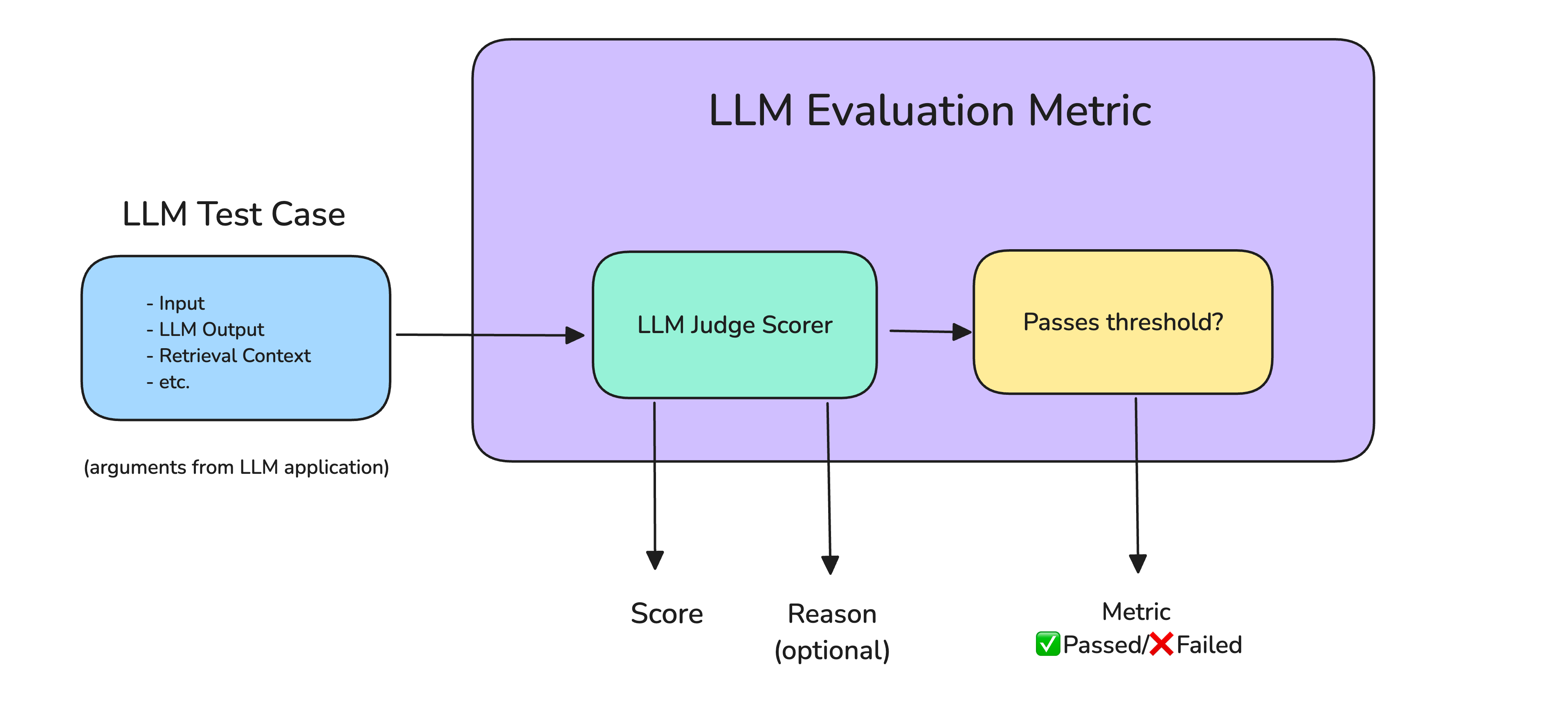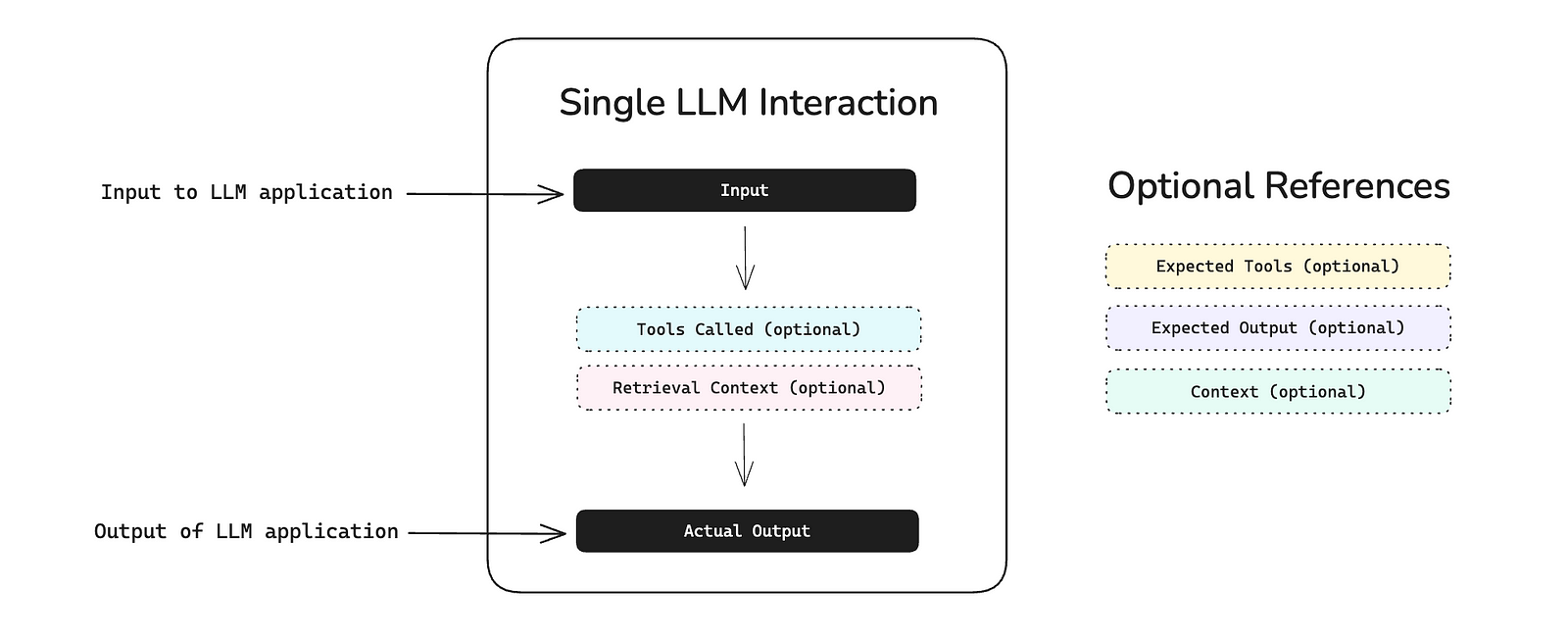
DeepEval is the open-source framework that lets you write unit tests for LLM applications. It has 10.8k GitHub stars because it's actually useful - think pytest but for testing whether your chatbot is hallucinating bullshit. The documentation is surprisingly readable compared to most AI tools that assume you have a PhD.
Confident AI is their commercial cloud platform where you pay starting at $19.99/month per user for team dashboards, dataset management, and hosted evaluation runs. The founders are Y Combinator backed and smart enough to keep the core framework free while charging for the collaboration features that enterprise teams actually need. Check their startup story and Series A funding details to understand their business model.
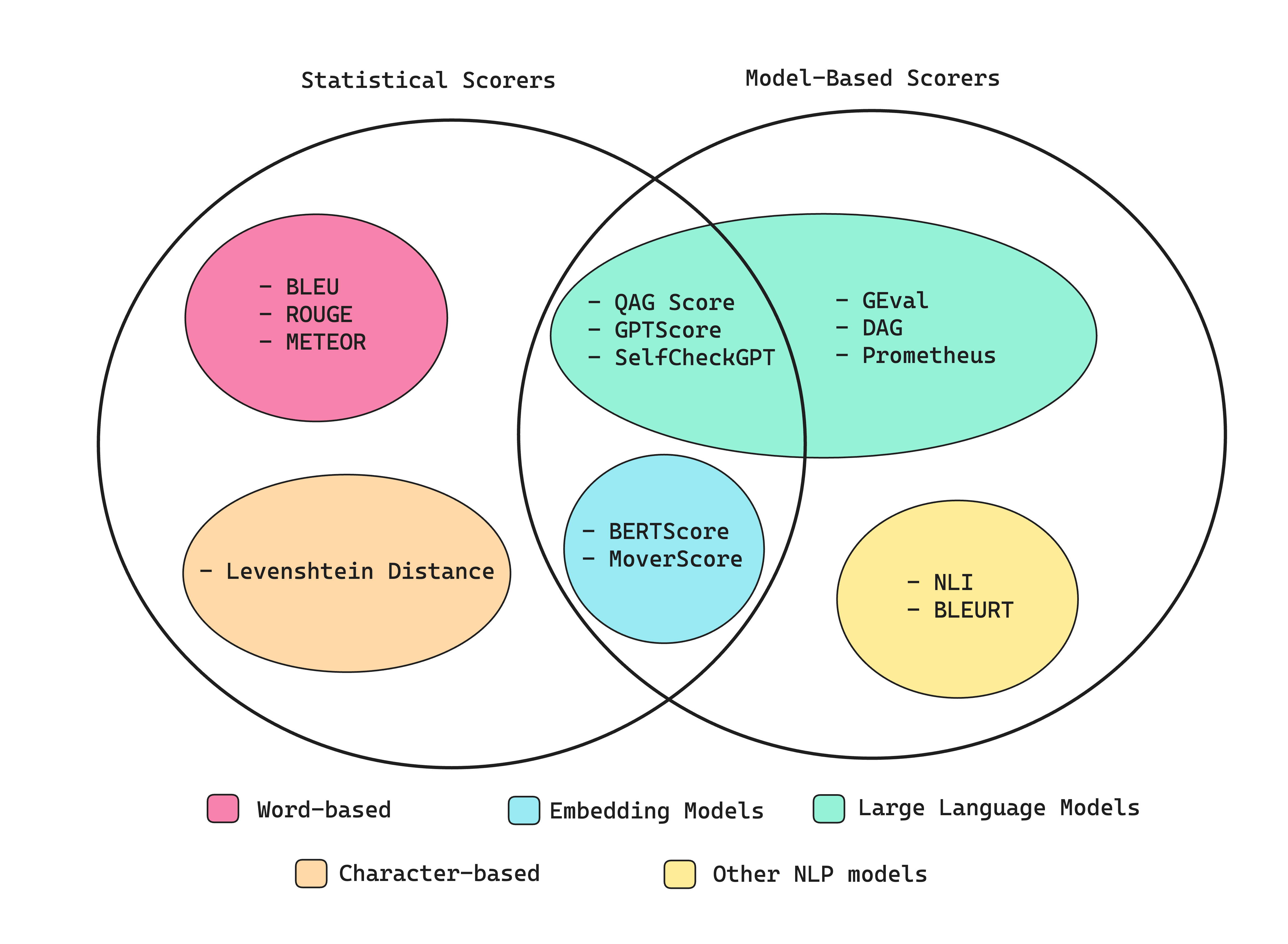
The Real Story: Local vs Cloud
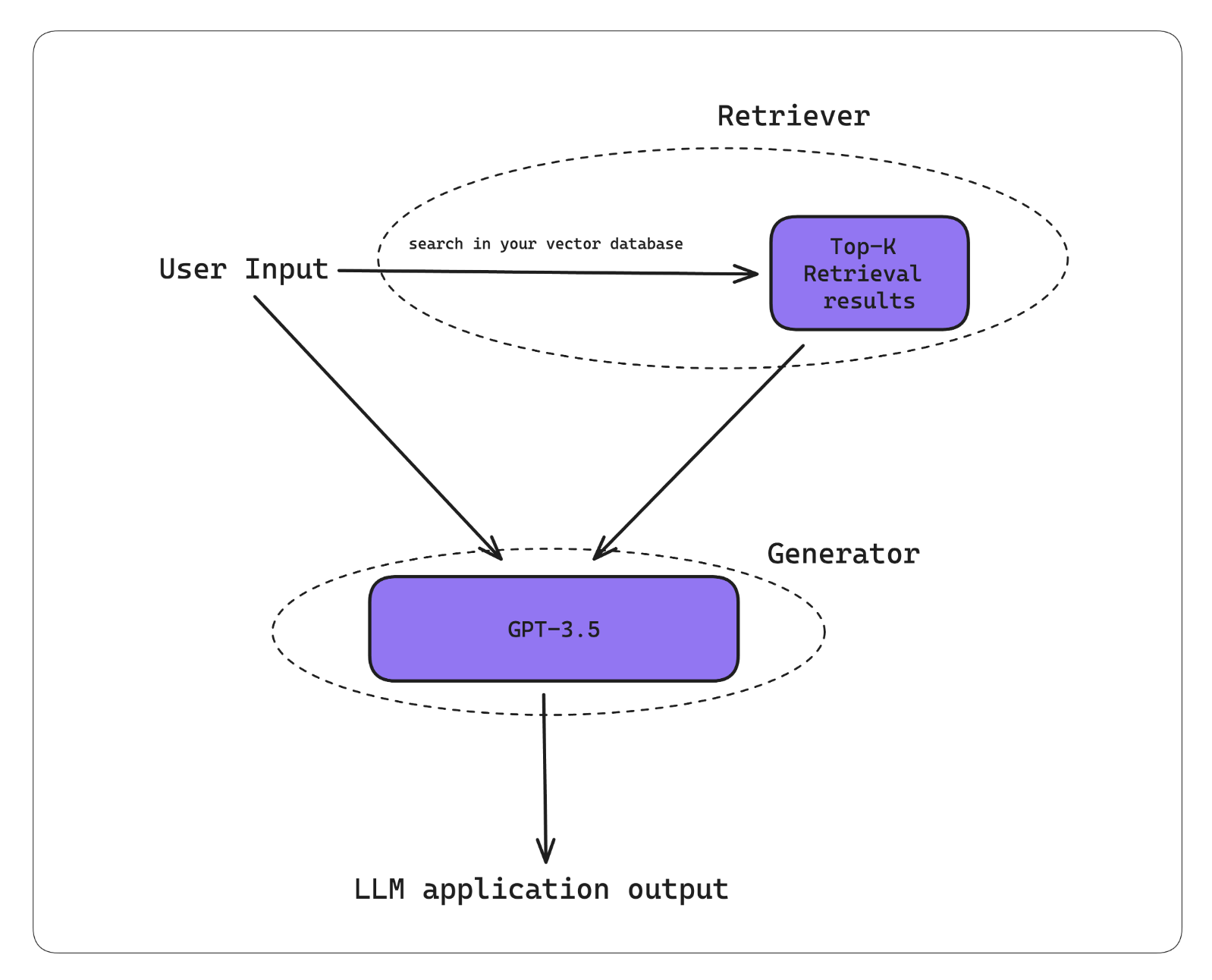
Look, here's the deal - DeepEval runs locally and doesn't send your data anywhere. You can evaluate your models, run tests in CI/CD, and debug LLM issues without paying anyone a dime. That's the smart move they made - give away the hard technical work, charge for the pretty dashboards.
The cloud platform adds team collaboration, dataset versioning, production monitoring, and the ability to share evaluation results without screenshotting terminal output. If you're a solo developer or small team, stick with the open source version. If you have 5+ people who need to see evaluation results and your manager wants dashboards, then you're paying Confident AI.
What's Actually Good About It
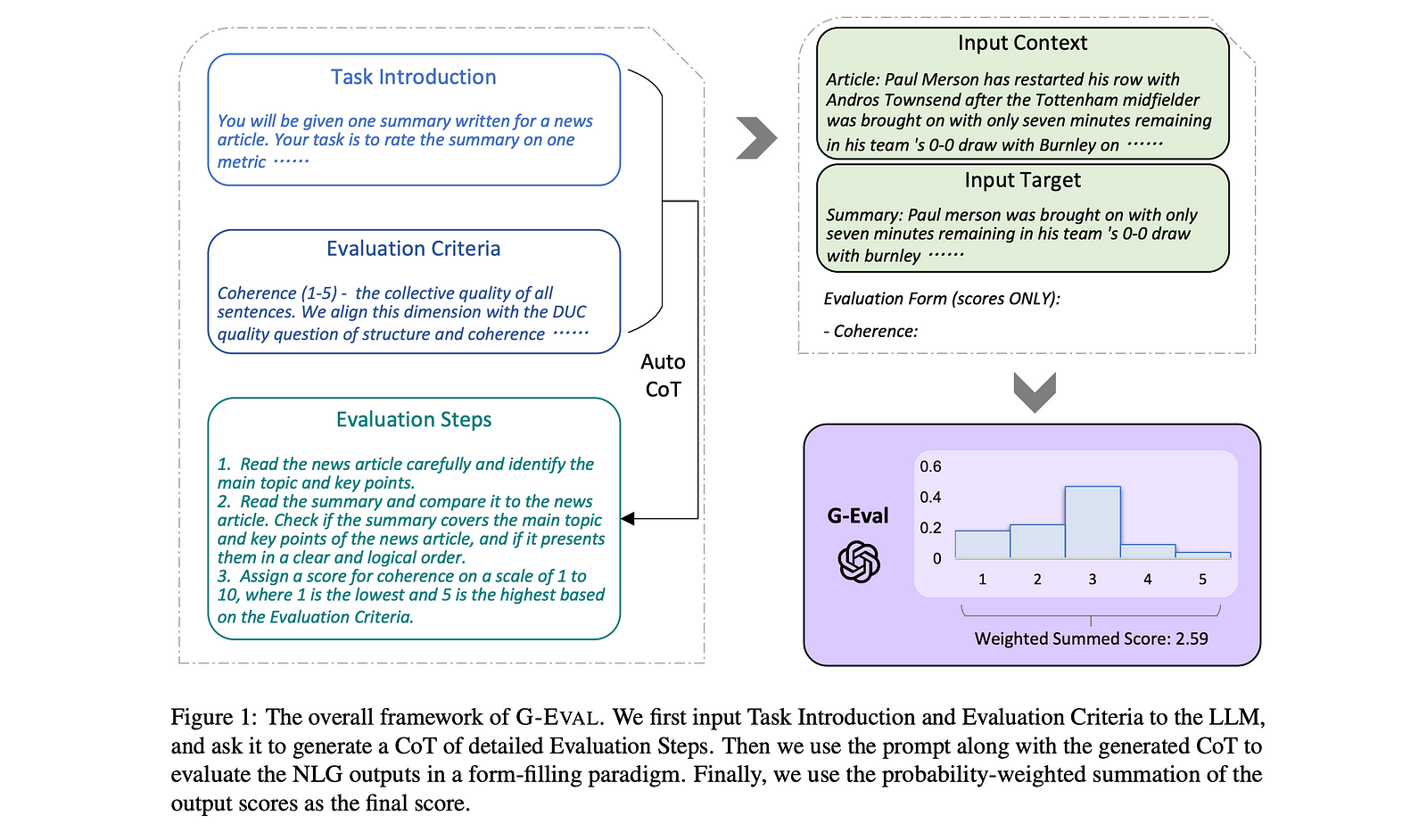
G-Eval metrics work pretty well - they use LLM-as-a-judge to evaluate responses against custom criteria. It catches most obvious problems like completely irrelevant answers or factual hallucinations. Not perfect, but better than manual review most of the time.
Integration works if you stick to the happy path - pip install deepeval, write test cases like pytest, run deepeval test. If you've used pytest before, you'll be productive in 10 minutes. Until you hit the first Docker networking issue or async timeout that burns half your day.
RAGAS metrics are pretty good - Answer Relevancy catches off-topic responses, Faithfulness catches hallucinations most of the time, Contextual Precision helps debug retrieval issues. Not perfect, but probably the best automated metrics available right now. The RAGAS research paper explains why these metrics work better than traditional NLP approaches.
Production Reality Check
The evaluation metrics cost money to run - they're powered by LLM API calls. G-Eval costs can be $0.01-0.05 per evaluation depending on your criteria complexity and the model you use for judging. That adds up fast if you're evaluating thousands of responses. Use the OpenAI pricing calculator to estimate costs before running large test suites.
API timeouts are common with complex evaluations. Set longer timeouts than the defaults or your CI/CD will randomly fail. The @observe decorator for component tracing works great locally but randomly breaks in Docker containers with zero helpful error messages - check the GitHub issues for known problems.
Debugging deployment failures is a nightmare - spent most of a weekend chasing why tests kept failing in CI. The default timeout settings are trash and the error messages might as well say "something broke lol." Thought I had everything working locally, then deployed to AWS Lambda and watched everything time out. Turns out G-Eval evaluations can take 5+ seconds each, maybe longer if the API is slow. Nobody mentions this in the getting started docs.
DeepEval doesn't suck, which puts it ahead of most LLM eval tools. Once you get past the initial setup pain, the core evaluation stuff actually works pretty well. The cloud platform costs real money but saves time for larger teams. Just know what you're paying for - this thing needs some babysitting like any other AI tool.