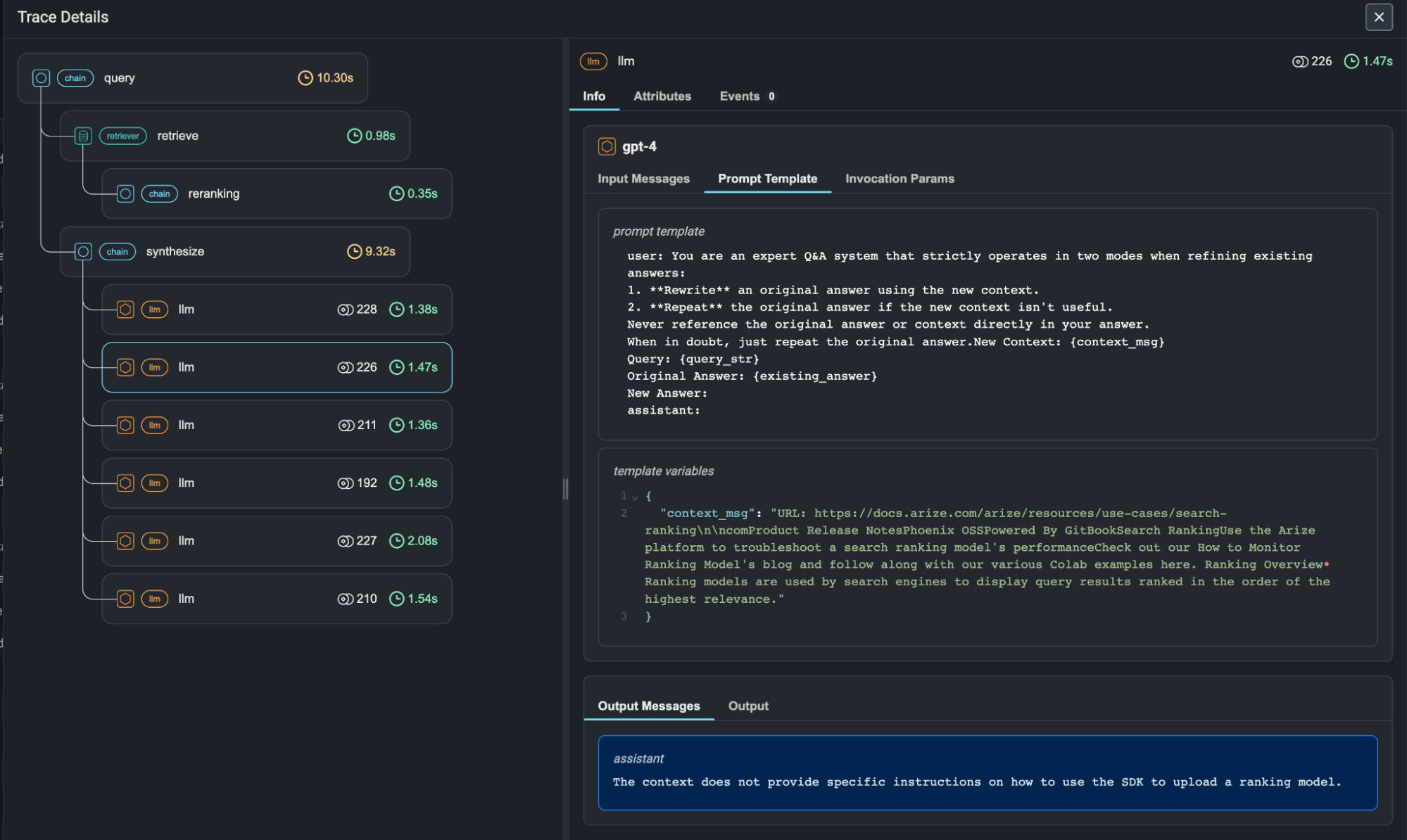
LLMs get all the attention, but your traditional ML models are still doing the heavy lifting—processing millions of transactions, powering recommendation feeds, and catching fraud while you sleep. The good news? They fail in predictable, debuggable ways. The bad news? Without monitoring, you won't know they're failing until it's too late.
Your classic ML models—fraud detection, recommendation engines, image classifiers—have been quietly breaking in production for years. Here's what actually goes wrong and how Arize catches it before your metrics turn red.
The Three Ways Your Models Will Break
Data drift happens when your inputs change but nobody tells your model. Your fraud detector was trained on 2023 transaction patterns, but crypto payments exploded in 2024. Your model thinks every Bitcoin transaction is suspicious because it never saw this shit before. Arize shows you when your input distributions look nothing like training data.
Performance decay is sneakier. Your model's still getting the same types of data, but the world changed. Economic conditions shifted, user behavior evolved, competitors launched new products. Your click-through prediction model trained on pre-recession data doesn't understand post-recession user behavior. Accuracy slowly went to complete shit over months - dropped to like 60-something percent - and nobody noticed until revenue tanked.
Infrastructure fuckups are the most obvious but hardest to debug. Memory pressure causes your feature extraction to timeout and return zeros. Your model gets garbage inputs and makes garbage predictions. Users complain about "weird recommendations" but your metrics show latency is fine. Arize traces the whole pipeline so you can see where data gets corrupted.
Production Disasters You'll Experience
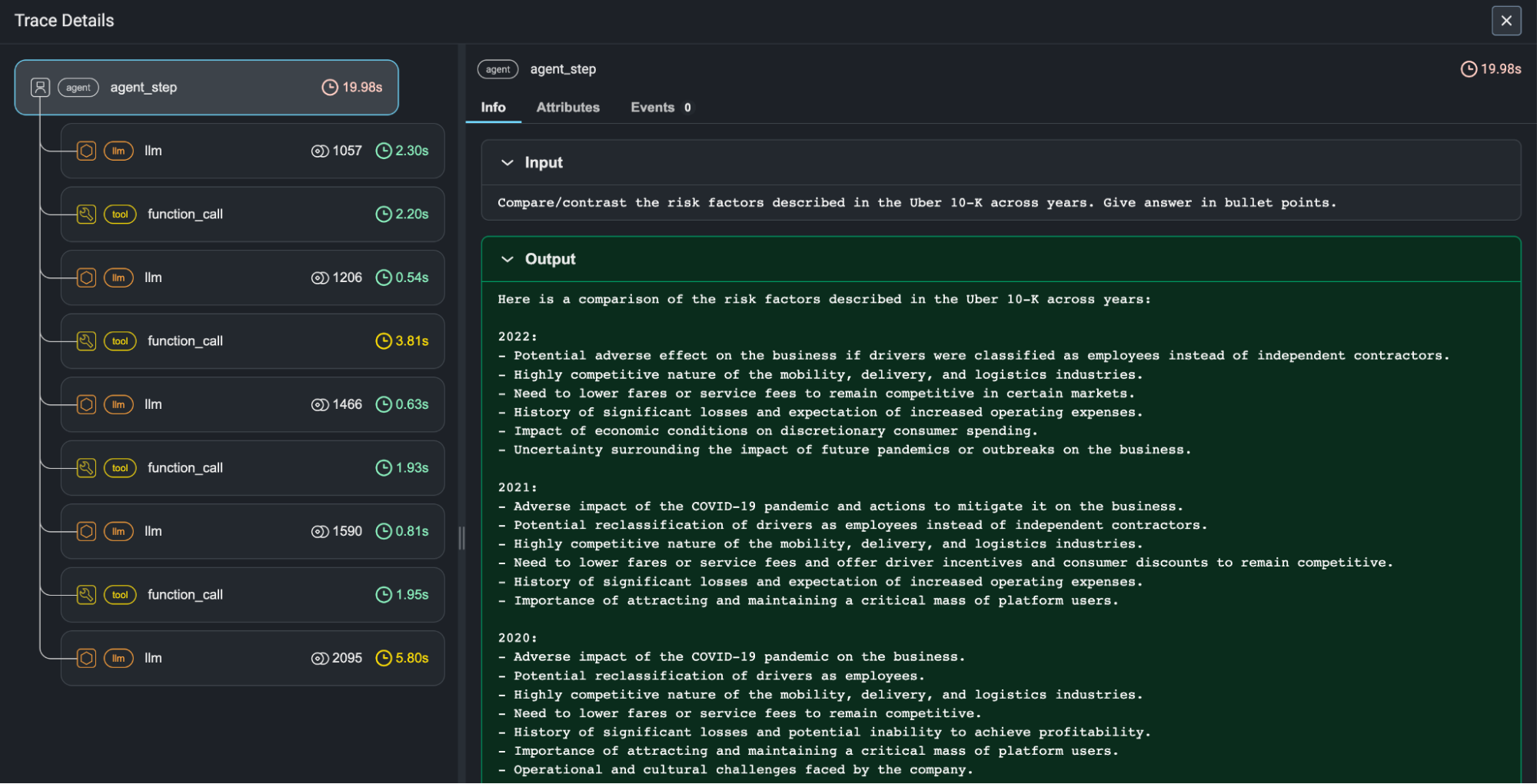
The silent bias creep - Your hiring model works great for 6 months, then someone notices it's rejecting 90% of female candidates. Turns out your training data had gender bias, but it only became obvious at scale. Arize's bias detection would have caught this before your company made the news for all the wrong reasons.
The embedding collapse - Your recommendation system's embeddings suddenly start clustering everything as "similar to JavaScript tutorials." Users kept getting recommended the same React course no matter what they searched for. Turns out your training pipeline had a data processing bug for weeks where it kept duplicating the same training batch. Your model literally learned that everything is JavaScript. Spent forever debugging this while getting angry tickets about "broken recommendations" before we figured out what happened. Embedding drift monitoring would have caught this way earlier.
The feature engineering nightmare - Your model expects age_in_years but your feature pipeline started sending age_in_days after a "small" refactor. Model accuracy went to shit overnight - dropped to like 50-something percent. Nobody caught it because both were numbers and the data validation passed. Your model was trying to predict creditworthiness thinking 25-year-olds were 9,125 years old. Customer complaints started rolling in about loan rejections. Arize's feature drift detection would have flagged the sudden distribution change right away.
Actually Useful Alerts (Not Spam)
Set alerts for actual problems, not every tiny metric fluctuation. Configure "accuracy below 70%" not "accuracy dropped 0.1%". You want to know when your model is broken, not when it had a slightly bad Tuesday.
Cost monitoring matters too. Found out the hard way when someone deployed our image classifier to some expensive GPU instance instead of the cheap one because "it'll be faster." AWS bill went from like $200 to something ridiculous - I think it was over 2 grand for the month. The CFO was not fucking amused. Track prediction costs per request to catch these expensive "optimizations" before your CFO calls an emergency meeting.