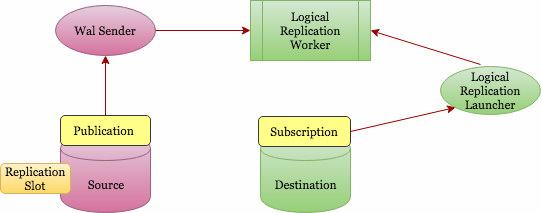

Look, logical replication sounds fancy but it's basically this: instead of copying the entire database like streaming replication does, you pick specific tables and only sync those. PostgreSQL reads the WAL records, decodes them into actual SQL operations (INSERT, UPDATE, DELETE), and sends those to your subscriber database.
The catch? Tables need a primary key or unique index to work properly. No primary key means you're stuck with REPLICA IDENTITY FULL, which sends the entire row for every update and will destroy your WAL volume on busy tables.
How It Actually Works (Without the Bullshit)
You create a publication on your source database (publisher) listing which tables to replicate. Then you create a subscription on the destination database (subscriber) that connects to the publisher.
The publisher starts a walsender process that uses the built-in `pgoutput` plugin to decode WAL records into logical replication messages. These get streamed to the subscriber where apply workers execute the SQL operations.
PostgreSQL 17 allegedly fixed some of the biggest pain points with failover slot synchronization and the new `pg_createsubscriber` utility that converts standby servers to logical subscribers. I'm still testing this shit - too many times PostgreSQL "fixes" have introduced new problems that are worse than the original bugs. But so far, it looks promising.
Why You'd Actually Want to Use This Thing
Different PostgreSQL versions? No problem. Logical replication works between major versions going back to 9.4. I've used it to migrate from PostgreSQL 11 to 15 with zero downtime. Streaming replication would've required matching versions and a full outage.
Only need specific tables? Perfect. You can replicate individual tables, specific columns, or even filter rows with WHERE clauses in your publication. Beats copying a 2TB database when you only need the user activity tables.
Want to write to the replica? Logical replication lets you write to subscriber databases. The subscriber can have different indexes, triggers, even completely different schemas. Try doing that with streaming replication (hint: you can't).
Multiple data sources? A subscriber can pull from multiple publishers. I've used this to aggregate customer data from regional databases into a central analytics warehouse.
PostgreSQL 17 Finally Fixed the Big Issues
PostgreSQL 17 dropped on September 26, 2024 and honestly, it fixed the stuff that's been driving everyone crazy about logical replication:
Failover slot synchronization: Remember how logical replication slots would just disappear after failover? Yeah, that's fixed. Slots now sync between primary and standby, so your replication doesn't die when the primary goes down. This was a massive operational pain point.
pg_createsubscriber utility: You can now convert existing physical standbys to logical subscribers without rebuilding everything from scratch. I've rebuilt way too many logical replication setups because of this missing piece.
pg_upgrade preservation: Your logical replication setup actually survives major version upgrades now. Before this, upgrading PostgreSQL meant tearing down and rebuilding all your replication relationships.
What Actually Breaks in Production
Tables without primary keys are a nightmare. You'll need either a unique index or REPLICA IDENTITY FULL. The latter sends the entire row for every update and will absolutely murder your WAL volume. I learned this the hard way on a busy events table - WAL usage went completely insane, like 5x or 6x normal volume. The monitoring graphs looked like a hockey stick.
WAL retention will fill up your disk. Logical replication slots prevent WAL cleanup until all subscribers catch up. If a subscriber goes down or gets stuck, your primary server runs out of disk space. I've seen this kill production servers when monitoring wasn't set up properly. Set up alerts on pg_replication_slots.restart_lsn lag or you'll get paged at 3am when the server dies.
Network connectivity is critical. Each subscription needs its own connection to the publisher. Unlike streaming replication with one connection, logical replication multiplies your connection requirements. Network hiccups cause apply lag that compounds quickly on busy systems.
Sequences drift like crazy. Logical replication doesn't sync sequences, so your subscriber's sequence values drift from the publisher. If you fail over to a subscriber, you'll get primary key conflicts when new inserts use duplicate sequence values.
Performance and What Doesn't Work
Logical replication uses less I/O than streaming replication since it only processes actual data changes, but the WAL decoding uses CPU cycles. On a busy system, you'll see higher CPU usage on the publisher from the walsender processes.
Schema changes aren't replicated. You have to apply DDL changes manually on both publisher and subscriber. This includes adding columns, changing types, creating indexes - everything structural needs to be coordinated manually.
TRUNCATE wasn't supported until PostgreSQL 11. If you're still on 10 or earlier, TRUNCATE operations just don't replicate. Subscribers keep their data while the publisher table gets emptied.
Large objects are fucked. TOAST columns and large objects aren't supported. Same with certain column types. Check the restrictions before committing to logical replication.
No conflict resolution. If you write to both publisher and subscriber, conflicts just error out and you're stuck fixing it manually. There's no automatic resolution like "last write wins" or anything useful. I once had a conflict that took me 3 hours to figure out because the error message was something useless like "duplicate key value violates unique constraint" with zero fucking context about which operation or row caused it. You need external tools like Postgres-XL, EnterpriseDB's BDR, or pglogical for multi-master scenarios, but honestly those add their own complexity and new ways to break.
When You Actually Need This
Cross-version upgrades: I've used logical replication to upgrade from PostgreSQL 11 to 15 with zero downtime. Well, mostly zero - had a brief hiccup when sequences got out of sync, but that's another story. Set up logical replication to the new version, let it sync, then switch over. Way less risky than pg_upgrade on a production system.
Selective data sync: Need to sync just user tables to a reporting database? Logical replication lets you pick specific tables and even filter rows with WHERE clauses. Beats copying a 2TB database when you only need 100GB of actual data.
Multi-region compliance: GDPR requires EU customer data stays in EU? Set up logical replication with row filters based on customer location. Each region gets only the data it's legally allowed to have.
Real-time ETL: Stream changes to your data warehouse as they happen. The subscriber can have completely different schemas, indexes, even extra computed columns. Try doing that with streaming replication.
Just remember: logical replication is complex as hell compared to streaming replication. Only use it when you actually need the features it provides. For basic high availability, streaming replication is usually what you want. Check out comprehensive tutorials if you're just getting started.