ClearML: The MLOps Platform That Actually Works - An open-source solution that automatically tracks your ML experiments with minimal code changes, providing comprehensive experiment management and remote execution capabilities.
Picture this: It's 2am. Your model is performing like shit in production but it was working perfectly last week. You're digging through Git commits, trying to figure out which hyperparameter change broke everything. Sound familiar? That's exactly why ClearML exists.
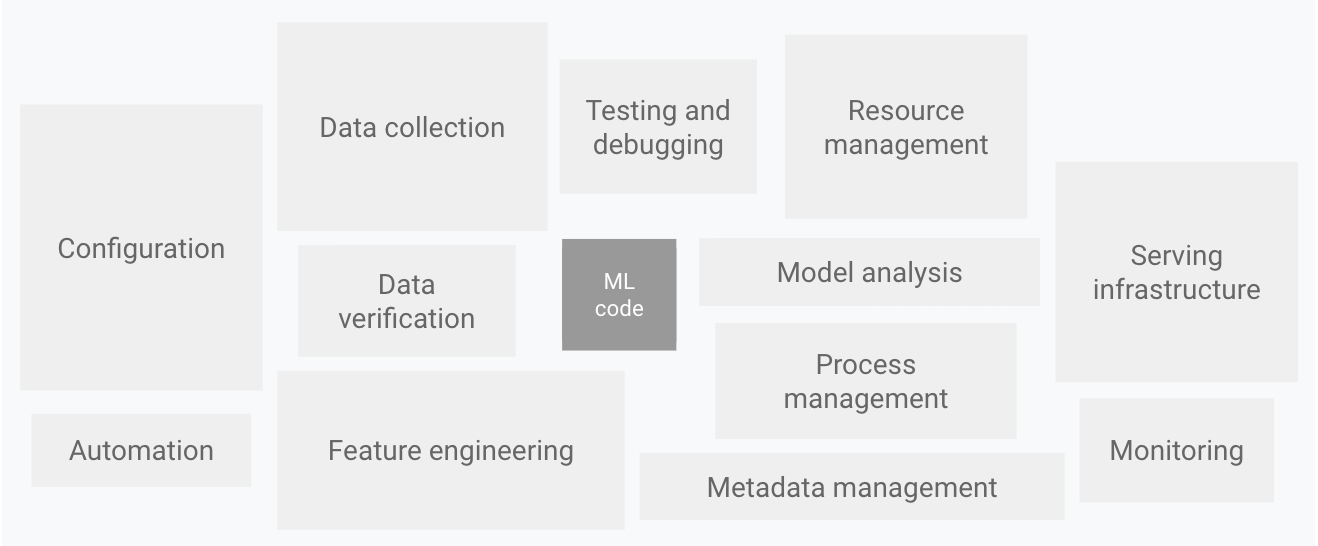
The Problem Every ML Team Has
The Spreadsheet Hell Reality: Teams typically track experiments using scattered notebooks, Excel files, and Slack messages - a chaos that becomes unmaintainable as soon as you have more than a few experiments running.
ML experiment management is chaos. You run 50 experiments, each with slightly different hyperparameters. Maybe you scribble notes in a notebook, or use some half-assed Excel sheet. Then your manager asks "which model performed best?" and you spend the next 3 hours trying to piece together what you actually did.
I've been there. We all have. You tweak the learning rate, forget to commit, run overnight, and wake up to find your best model ever. But you can't reproduce it because you don't remember what the hell you changed. This is why ML reproducibility is such a critical problem.
What ClearML Actually Does
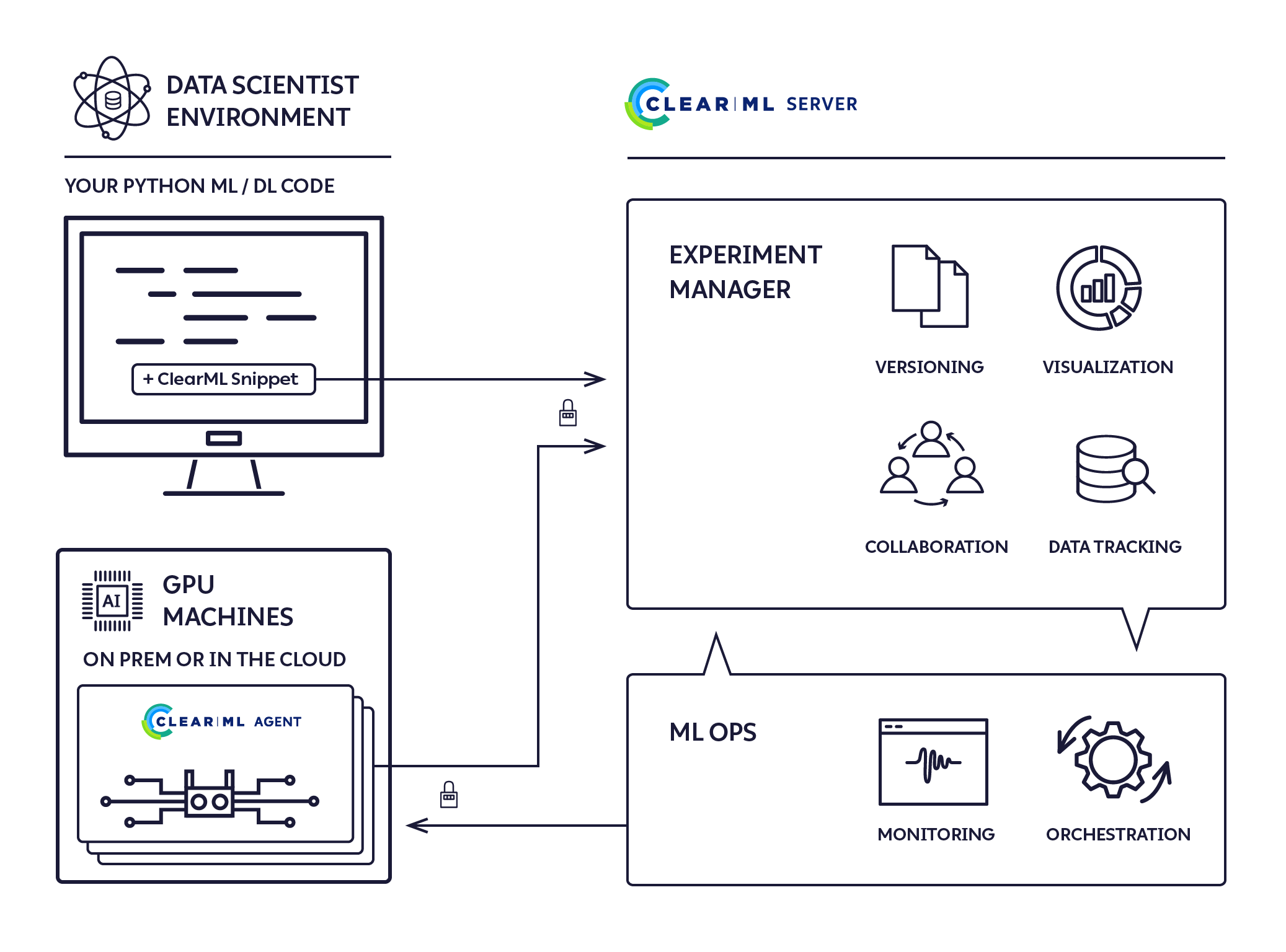
ClearML's Architecture: The platform consists of three core components - the ClearML Server for data storage and coordination, ClearML Agents for remote execution, and the SDK for automatic tracking integration.
ClearML tracks everything automatically. And I mean everything:
- Code state: Git commit hash, branch, even your uncommitted changes that you forgot to push
- Environment: Python version, package versions, CUDA version, all that environmental bullshit that breaks between machines
- Parameters: Every hyperparameter, configuration file, command line argument
- Metrics: Loss curves, accuracy, custom metrics, whatever you're logging
- Resources: CPU/GPU usage, memory consumption, disk I/O - helps you spot when your data loader is the bottleneck
- Artifacts: Model checkpoints, datasets, plots, anything you want to keep
The magic is that it requires almost no code changes. Add these two lines to your training script:
from clearml import Task
task = Task.init(project_name="my_project", task_name="experiment_1")
That's it. Everything gets tracked automatically through monkey-patching your ML frameworks. ClearML integrates with PyTorch, TensorFlow, Keras, and many others.
Real-World War Stories
Resource Monitoring in Action: ClearML's real-time resource tracking shows exactly where your compute dollars are going - CPU utilization, GPU usage, memory consumption, and network I/O across all your experiments.
The "Where's My Best Model?" Incident: Our team spent 2 days trying to reproduce a model that achieved 94% accuracy. Turned out the data scientist had modified the validation split locally and never committed the change. With ClearML, we would have seen the exact code state and dataset version.
The GPU Bill Shock: We were burning through AWS credits without understanding why. ClearML's resource monitoring showed one experiment was using 8 GPUs but only training on 1. The data loader was configured wrong and sitting idle. Saved us $3000/month.
The Hyperparameter Hell: During a model comparison, we found our "best" model was actually trained with different preprocessing steps than we thought. ClearML's automatic environment capture would have caught this immediately.
When ClearML Actually Helps
- Reproducibility: You can reproduce any experiment months later, even if the original developer left. This addresses the reproducibility crisis in ML
- Collaboration: Team members can see exactly what everyone tried without Slack archaeology. ML collaboration becomes actually possible
- Resource Optimization: Spot inefficient experiments before they drain your compute budget. GPU utilization tracking saves real money
- Model Lineage: Track which dataset and preprocessing pipeline created which model. Essential for model governance
- Production Debugging: When production fails, you know exactly which experiment to roll back to. ML monitoring done right
The Honest Limitations
ClearML isn't perfect. The automatic tracking sometimes misses custom metrics if you're doing weird shit with your logging. The web UI can be slow with thousands of experiments. And if you're doing distributed training across multiple nodes, the setup gets more complex.
But here's the thing: even with these limitations, it's infinitely better than the spreadsheet hell most teams live in. The time saved on experiment tracking alone justifies the occasional frustration.
So how does ClearML compare to the alternatives? Every team asks this question. Here's the brutally honest breakdown of your options.