Azure Synapse is Microsoft's attempt to solve the "too many data tools" problem by jamming everything into one platform. I've been working with it since the SQL DW days in 2019, and honestly? It's gotten better, but it's still Microsoft's way of saying "why use five different tools when you can struggle with one really complex one?"
If you're coming from traditional SQL Server, prepare for some mind-bending concepts. Synapse isn't just a bigger database - it's a completely different animal that separates compute from storage, which sounds great until you're trying to figure out why your query costs $47 when it used to be free.
The Five Pieces of This Complex Puzzle
Here's what you're actually dealing with when you spin up Synapse:
Synapse SQL comes in two flavors that'll confuse the hell out of you initially. Serverless SQL pools let you query data lakes without spinning up infrastructure (great for ad-hoc stuff, terrible for anything requiring consistent performance). Dedicated SQL pools give you the traditional data warehouse experience, but remember - these burn money 24/7 unless you pause them.
Apache Spark integration sounds awesome until you realize debugging Spark notebooks in Synapse Studio is a special kind of torture. It supports Python, Scala, R, and .NET, but good luck getting your local development environment to match what's running in Azure. The Delta Lake integration is solid though - once you get it working.
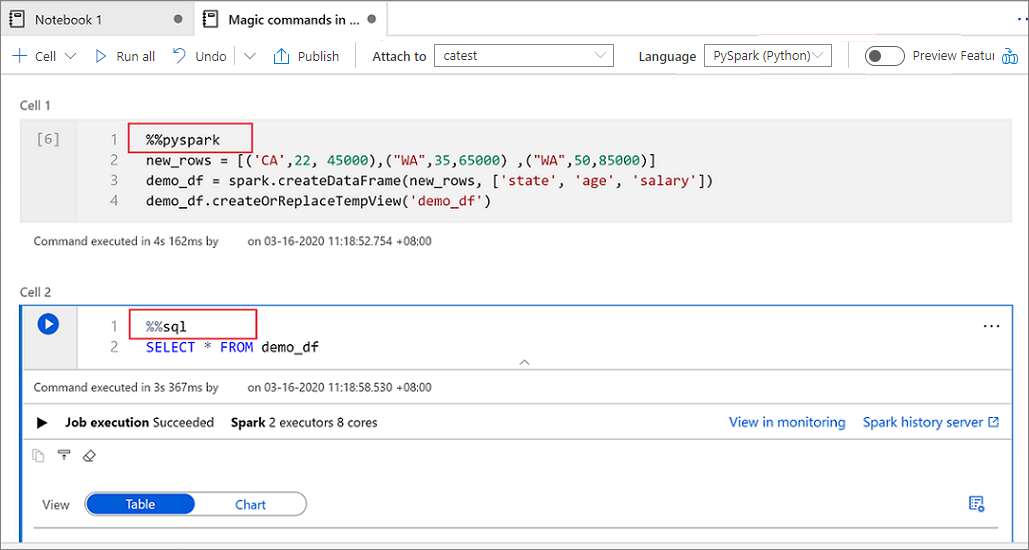
Data Integration uses the same engine as Azure Data Factory, which means it connects to everything but configuring those connections will test your patience. The visual designer is pretty, but you'll end up writing JSON anyway for anything non-trivial.
Performance Reality Check
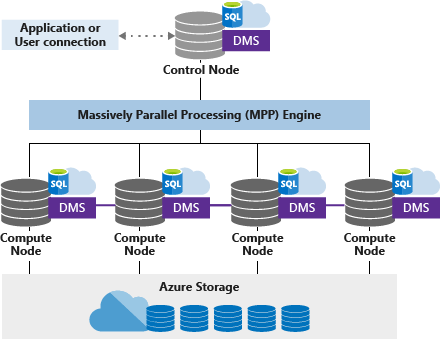
Let me give you the real numbers. Synapse scales from DW100c to DW30000c - that's 100 to 30,000 Data Warehouse Units. The marketing says "scales in minutes" but I've seen it take 15-20 minutes during peak hours. Budget accordingly.
Query performance depends heavily on how you design your tables and indexes. I've seen identical queries run in 2 seconds or 2 minutes depending on distribution strategy. The "sub-second" response times Microsoft talks about? That's for perfectly optimized workloads with proper partitioning, columnstore indexes, and data that's already cached. Your mileage will vary.
Storage uses Azure Data Lake Storage Gen2, which is actually pretty solid. It handles Parquet, Delta Lake, CSV, and JSON without issues. The data lake + data warehouse combo works well, but setting up the RBAC permissions will make you question your life choices.
Performance tuning requires understanding columnstore indexes, table distribution strategies, and partitioning schemes. The performance monitoring tools help but expect a steep learning curve.
The Microsoft Lock-in Reality
If you're already deep in the Microsoft ecosystem, Synapse plays nice with Power BI, Azure ML, and Microsoft Purview. The Power BI integration is actually quite smooth - it's one of the few things that works exactly as advertised.
For third-party tools, you get standard ODBC/JDBC connections, but expect to spend time troubleshooting connection strings and firewall rules. Every BI tool vendor claims "full Synapse support" but most tested against SQL Server and hope for the best.
Oh, and Microsoft keeps rebranding this stuff. First it was SQL Data Warehouse, then Synapse, now they're pushing Microsoft Fabric as the "next evolution." My advice? Don't hold your breath waiting for migration tools that actually work.
Before you commit to Synapse, you should understand how it stacks up against the competition - and what you're really signing up for in terms of costs and complexity. The comparison below shows the real-world performance and pricing differences that matter for production deployments.