Microsoft gives you five APIs, but they're not all created equal.
I've deployed every single one in production and lived through the pain. Here's what nobody tells you:
The APIs Ranked by How Much They'll Ruin Your Week
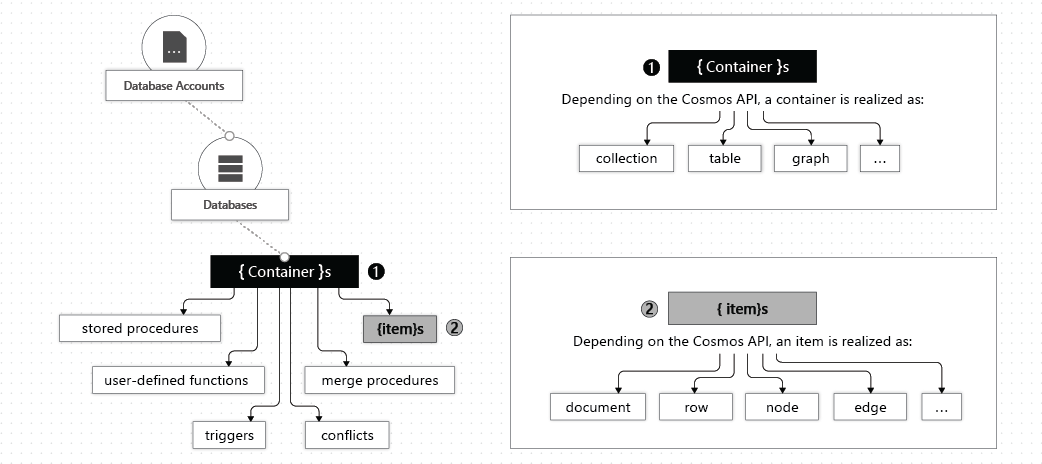
NoSQL API (Core SQL):
Just fucking use this one. It's Microsoft's favorite child and gets new features first. If you know SQL, the learning curve isn't terrible. Gets stored procedures, triggers, and somehow burns through RUs more efficiently than the others. When that weird connection pooling bug hit last month (I think it was 18.2.1?), NoSQL API got patched in like 2 days while MongoDB API users waited weeks.
MongoDB API: Good for migrations when you can't afford to rewrite everything.
Existing Mongo
DB drivers work, which is nice. But here's the fun part
- it's not actually MongoDB. GridFS doesn't work, some aggregation pipeline operations behave differently, and good luck debugging why your compound indexes aren't being used properly. I spent three days figuring out why our session store was consuming 10x more RUs than expected.
Table API: The boring one that actually works reliably.
Key-value operations only, but they're fast and cheap. Perfect for user sessions, feature flags, or anything that doesn't need complex queries. I've never had a production incident with Table API because there's not much to break.
Cassandra API: Time-series data and nothing else.
CQL works until you try using secondary indexes
- then you discover half the features are missing or behave weirdly. One team I worked with spent two weeks debugging why their WHERE clauses weren't working, turns out Cosmos DB's Cassandra doesn't support filtering on non-primary key columns the same way.
Gremlin API: Graph databases for when you hate yourself and everyone around you.
Query syntax looks like someone threw Cypher and SQL into a blender. Performance? Good fucking luck
- I've seen a simple "find friends of friends" query somehow eat 2,000 RUs while an identical traversal cost 50 RUs. Still have no idea why. Only use this if you absolutely need graph operations and enjoy explaining to your manager why the database budget tripled.
The Reality Behind "Multi-API Magic"
Cosmos DB stores everything in their proprietary ARS format and translates to whatever API you're using. Clever engineering, but here's what bites you:
- **No
SQL gets the best performance**
- other APIs have translation overhead
- Some features are NoSQL-only
- stored procedures, triggers, patch operations
- MongoDB compatibility isn't 100%
- aggregation pipelines can consume 2x the RUs
- Mixing APIs is asking for trouble
- don't even think about it
When Each API Makes Sense (Real Talk)
Use NoSQL API:
- You're starting fresh
- You want new features first (vector search, full-text search)
- You need stored procedures or server-side logic
- You want the most efficient RU consumption
Use MongoDB API:
- You're migrating existing MongoDB code
- Your team refuses to learn new syntax
- You have complex aggregation pipelines that work
- You're stuck with existing MongoDB tooling
Use Table API:
- Simple key-value lookups only
- You're migrating from Azure Table Storage
- You want predictable, cheap operations
- Complex queries aren't needed
Use Cassandra API:
- Time-series or IoT data at massive scale
- You're already using Cassandra and it works
- You need wide-column data modeling
- You understand CQL limitations in Cosmos DB
Use Gremlin API:
- You absolutely need graph traversals
- Building recommendation engines
- Fraud detection with relationship analysis
- You enjoy debugging nightmare query performance
The Brutal Truth About RU Consumption
Every API uses Request Units, but the costs vary wildly:
- Point reads: 1 RU per 1KB (only thing that's consistent)
- Writes: 5-8 RUs per 1KB depending on API overhead
- Queries:
No
SQL is cheapest, MongoDB costs 20-30% more, Gremlin will bankrupt you
- Cross-partition queries: All APIs get destroyed equally
I watched one team's Mongo
DB aggregation pipeline absolutely destroy their budget
- 800 RUs for a query that would cost maybe 20 RUs in NoSQL.
Turns out they had these pointless $unwind operations that Cosmos DB just couldn't figure out how to optimize. Took them three weeks to unfuck it, but their monthly bill dropped from like $4,000 to $1,200.
Real Decision Framework
Use NoSQL API unless you have a damn good reason not to. It gets new features first, best tooling, and burns the fewest RUs.
Only use other APIs if:
- You're migrating existing code and can't afford a full rewrite
- Your team will quit if they have to learn new syntax
- You need specific features (graph traversals, Cassandra wide columns)
Don't get clever with multiple APIs. Pick one, stick with it, and resist the urge to use them all just because Microsoft lets you.