![]()
Look, managing secrets in Kubernetes sucks. You've probably been through this dance before: hardcode some database passwords in your deployment YAML "just for testing," forget to rotate them for six months, then scramble when security scans your Git history and finds plaintext AWS keys from 2019.
Why Your Current Secret Management Is Broken
Environment Variable Hell: You're storing secrets in ConfigMaps or worse, directly in your deployment specs. Every time you need to rotate a password, you're redeploying pods and crossing your fingers nothing breaks. Kubernetes secrets aren't much better - they're just base64 encoded plaintext stored in etcd.
The Manual Rotation Nightmare: Remember that database password that expired last weekend and took down production? Yeah, that's what happens when rotation is a manual process that relies on Larry remembering to update the secret before he goes on vacation. Security guides suggest automated 30-90 day cycles, but who has time for that?
Permission Sprawl: Your CI/CD service account probably has access to every secret in every namespace because nobody wanted to spend three hours debugging RBAC permissions. One compromised pipeline = game over. Principle of least privilege? More like principle of "fuck it, just give it cluster-admin."
Vault's Approach (When It Actually Works)
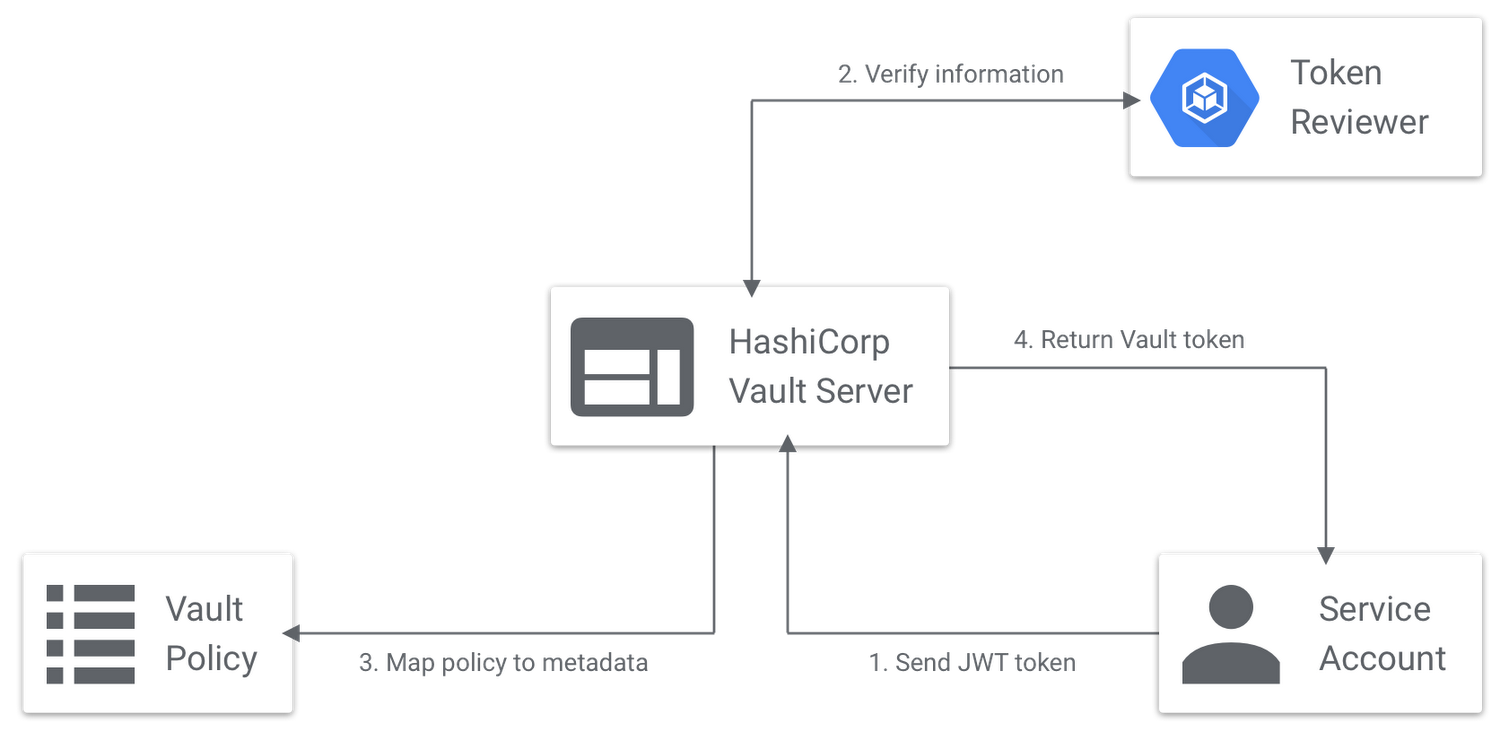
HashiCorp Vault generates secrets when you need them and kills them automatically. Instead of storing DB_PASSWORD=hunter123 in your environment variables, your app asks Vault for a fresh database user that expires in 4 hours.
Dynamic Database Credentials: Vault creates actual database users with precise permissions for each deployment. When the TTL expires, those credentials stop working. No manual cleanup required. Works with PostgreSQL, MySQL, MongoDB, and dozens of other databases.
Short-Lived Everything: API keys, certificates, cloud tokens - all generated with TTLs measured in hours, not months. Compromised credential? Wait it out or revoke immediately through Vault's API. AWS STS tokens can be generated on-demand with 15-minute lifespans.
Audit Logs That Actually Help: Every secret request includes who asked, when, from where, and what they got. Perfect for those fun compliance audits where you need to prove you're not storing passwords in Git. SOC 2, HIPAA, FedRAMP - all covered with proper audit device configuration.
Three Ways to Get Secrets From Vault (All With Trade-offs)
Option 1: Vault Agent Injector - Works great when it works. When it doesn't, good luck figuring out why your pod is stuck in Init:0/1 forever. The Agent Injector error messages are about as helpful as a chocolate teapot. Check the common issues guide when shit hits the fan.
Option 2: External Secrets Operator - Probably your best bet unless you have exotic requirements. ESO syncs Vault secrets into regular Kubernetes Secret objects. Sometimes stops syncing secrets for mysterious reasons, but at least you can kubectl your way to a solution. The ESO documentation is actually readable, unlike most Kubernetes projects.
Option 3: Direct API calls - For masochists who enjoy debugging OAuth flows at 3am. Your GitHub Actions or GitLab CI jobs authenticate directly to Vault using OIDC tokens. Fast when it works, nightmare when GitHub's OIDC provider has a bad day. JWT authentication is another option but equally painful to debug.
The Real Problems Nobody Talks About
OIDC Token Expiration: GitHub Actions OIDC tokens last exactly 5 minutes. Your deployment takes 20 minutes. I found this out when our entire Friday release pipeline died at the final Helm deploy step with Error: invalid token audience "vault://vault.example.com" because the token expired during our Trivy security scan. GitLab CI tokens pull the same bullshit - good for 10 minutes max before they turn into worthless JWT garbage.
Network Policies Break Everything: You enabled network policies for security? Hope you enjoyed accessing Vault, because that's over now. Spent 8 hours debugging why Vault Agent Injector suddenly couldn't authenticate with Error: Get "https://kubernetes.default.svc:443/api/v1/tokenreviews": dial tcp: lookup kubernetes.default.svc on 10.96.0.10:53: no such host after our security team enabled Calico's default-deny policy. The webhook couldn't reach the Kubernetes API on port 6443 anymore. Calico and Cilium both have their own creative ways of fucking your setup.
Vault Downtime = CI/CD Downtime: When Vault's unavailable, your entire deployment pipeline stops. Better have a backup plan or very good Vault clustering. Raft storage helps with HA, but disaster recovery is still an Enterprise feature.
This shit works, but it's way more complex than HashiCorp admits.
Pick your poison. Here's what actually happens in production.
