Before you touch anything, spend 3 months (not 4-8 weeks - that's consultant bullshit) figuring out what disaster you've inherited. That inventory spreadsheet from 2019? Garbage. Half those systems don't exist anymore, and the other half are critical but undocumented.
Studies show that 60-70% of IT assets go untracked in large organizations, making discovery the most critical phase.
Start by Finding the Previous Guy
Your first job is finding whoever built this mess 10 years ago. He's probably still working there, hiding in a cubicle, waiting for retirement. Buy him coffee. Lots of coffee. He's your only hope of understanding why the billing system depends on a Windows 2003 server named "DEATHSTAR."
I learned this the hard way when our "simple" migration project discovered that our main application was talking to 45 different databases, including one running on someone's personal laptop tucked under their desk. Use whatever discovery tools your company already has, or just walk around and interview people - either way, you'll find systems that exist nowhere in your documentation.
Application discovery tools promise comprehensive asset mapping, but the reality is that manual discovery processes often reveal more critical dependencies.
The Real System Discovery Process
Forget the fancy assessment tools - start with the brutal basics:
What Actually Runs Where:
- Walk the server room. Yes, physically walk it.
- Find the boxes with blinking lights that aren't in any documentation
- Document the post-it notes on servers - they contain critical production configs
- Check for USB drives taped to servers (you'll find at least one)
Code Archaeology:
- Look for `TODO` comments from 2012 that say "temporary fix"
- Find the stored procedures that are 3,000 lines long with no comments
- Count how many different versions of jQuery are loaded on the same page
- Discover the JavaScript file that's literally called
dontdelete.js
Dependency Hell Discovery:
- Run the system and see what breaks
- Check the Windows Event Logs - they're terrifying but honest
- Look for hardcoded IP addresses in config files
- Find the magic cron jobs that "just work" but nobody knows why
What the Business Actually Needs (Spoiler: Not What They Say)
The VP will tell you the system needs to be "scalable and cloud-native." What they really need:
- The damn thing to not crash during month-end closing
- Reports to run in under 30 minutes instead of 3 hours
- The ability to add a new field without a 6-month project
I spent 6 weeks building a beautiful microservices architecture before realizing our biggest problem was a single SQL query that took 45 minutes to run because nobody had updated database statistics since 2016.
Setting Realistic Expectations
Here's what success actually looks like:
- Technical Reality: The system works on Monday mornings without you getting paged
- Performance Reality: 20% faster is a win, not "blazing fast cloud performance"
- Cost Reality: It will cost 3x more than estimated for the first year
- Timeline Reality: Add 50% to whatever timeline you think is realistic
The Stakeholder Alignment Clusterfuck
Getting everyone on the same page is like herding cats while the building is on fire:
- The CEO wants it done yesterday for free
- IT Security wants to audit every decision for 6 months
- Compliance just discovered GDPR exists and panicked
- The Database Team insists their Oracle 9i setup is "perfectly fine"
- End Users will revolt if you change the font, let alone the system
Budget for Archaeological Time
Plan for 3 months minimum just to understand what you have. Research on large IT projects shows they consistently exceed budgets and timelines, but that's because nobody budgets for the archaeology phase.
Industry studies indicate that 45% of IT projects exceed their budgets by 50% or more.
2024 modernization reality: Companies are throwing around $20 billion this year at application modernization services, expected to hit maybe $40 billion by 2029. The promise? Cut maintenance costs in half and boost efficiency by 10%. The reality? Most of that money goes to consultants who'll discover your unique disasters and bill you extra for the privilege.
Skip the fancy assessment frameworks - just walk the server room and interview the old-timers.
You'll spend weeks just figuring out:
- Which servers are actually production (hint: the one with no monitoring)
- Why the system stops working every Tuesday at 3 PM
- What that mysterious batch job does that runs every night
- Why there are 47 different ways to calculate the same thing
Reality Check: If you can't find the guy who built it originally, budget an extra month. If the system has been "temporarily" patched more than 5 times, budget two extra months. If you find COBOL code that "just handles the important stuff," start updating your resume.
Map your dependencies somehow - pen and paper works fine - and figure out what technical debt you're dealing with. Most automated discovery tools are overhyped garbage anyway.
You've survived the archaeological phase and documented your disaster. You know which servers are actually important, why the system breaks every Tuesday, and that the critical business logic is hidden in a VB6 component that nobody understands.
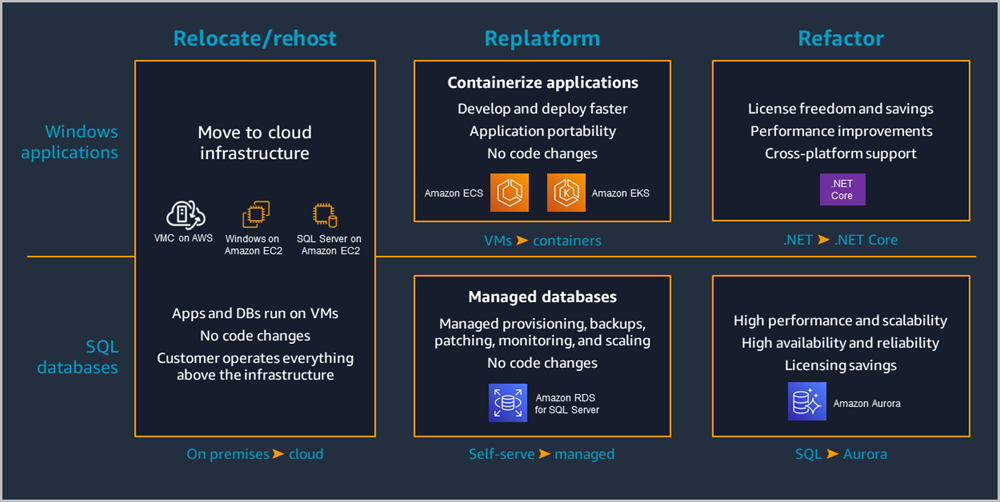
Time to pick your modernization strategy. The consultants are about to show you a shiny framework with buzzwords like "The 6 R's" and convince you that each approach will magically solve different problems. Here's the truth: they all suck in unique and expensive ways, but some suck less than others.