Why I Finally Switched After Months of Procrastination
API Migration Overview
Look, I'd been putting off this migration for months. Our OpenAI bills were getting ridiculous, but switching APIs always feels like asking for trouble. Then I saw DeepSeek V3.1 benchmarks - 82.6% on HumanEval vs OpenAI's 80.5% - and realized I was being an idiot.
The "Oh Shit, This Actually Works" Moment
How This Thing Actually Works
DeepSeek V3.1 uses a Mixture-of-Experts (MoE) architecture - basically 671 billion parameters but only 37 billion fire for each query. Think of it like having a massive team of specialists but only calling in the ones you need. The result? GPT-4 quality responses for the price of a gas station sandwich.
You get two models: deepseek-chat for normal stuff and deepseek-reasoner when you need it to actually think hard. The smart bit is V3.1 figures out when to use deep reasoning automatically - no more guessing which model to call.
Why This Won't Break Your Code (Probably)
Here's the beautiful part: DeepSeek is basically an OpenAI API clone. Same JSON, same auth headers, same everything. I literally changed 3 lines of config and our entire app worked.
What's identical:
- Same JSON, same auth, same everything that matters
- All the usual parameters work (
temperature,max_tokens, whatever) - Streaming responses work exactly the same
The only difference is the base URL and model names. That's it. Your existing error handling, retry logic, all that crap you spent hours debugging - it all just works.
Pro tip: I kept both configs running in parallel for a week. One environment variable switch and I could fall back to OpenAI if something broke. It didn't, but paranoia pays off.
Getting Your API Key (5 Minutes, No Phone Verification Bullshit)
First thing: sign up at platform.deepseek.com. Takes 30 seconds, no phone verification like some providers. Pretty sure they still give you 5 million tokens free, might be more now - that's about $8.40 worth of testing, enough to migrate and test without pulling out your credit card.
DeepSeek Platform Dashboard
IMPORTANT: When you generate your API key, they show it exactly once. I learned this the hard way. Copy it immediately into your password manager or you'll be generating a new one.
The key format is sk-... just like OpenAI, so your existing key management stuff works fine. I use dotenv and it was literally drop-in replacement.
That 5 million token free tier is legit generous. I processed our entire test suite (about 200 complex queries) and barely used 50k tokens. You can properly stress test this before spending a dime.
The 30-Second Config Change
No new dependencies, no package installs, just environment variables. Here's literally what I changed:
## Old OpenAI setup
OPENAI_API_KEY=sk-your-openai-key
OPENAI_BASE_URL=https://api.openai.com/v1
## New DeepSeek setup
DEEPSEEK_API_KEY=sk-your-deepseek-key
DEEPSEEK_BASE_URL=https://api.deepseek.com
I kept both configs active so I could flip between them with one env var change. Saved my ass during testing when I thought DeepSeek was choking on a complex query (turns out our prompt was just shit).
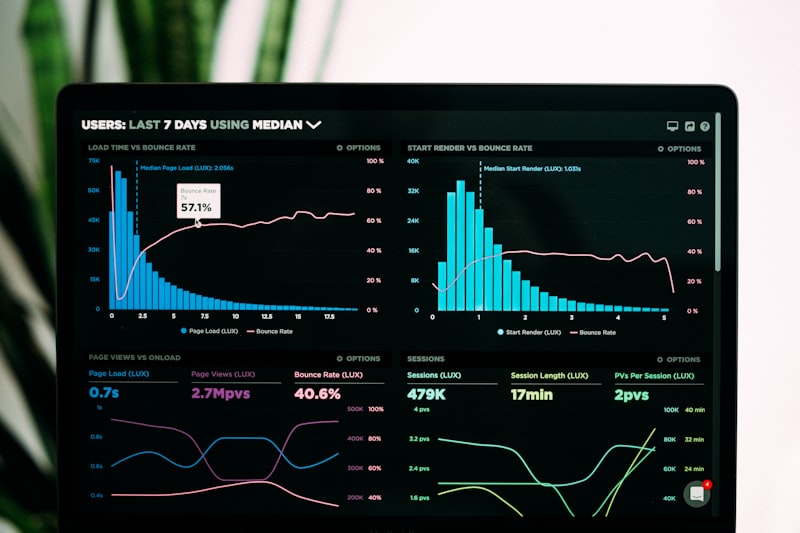
Real Performance Numbers That Actually Matter
Performance Comparison Data
Here's the thing about benchmarks - most are bullshit. But the coding ones? Those matter. DeepSeek hits 82.6% on HumanEval vs GPT-4's 80.5%. On Codeforces (algorithmic problems), DeepSeek destroys GPT-4: 51.6 vs 23.6.
Response times in my actual usage:
- Simple queries: 150-250ms (faster than GPT-4)
- Complex code generation: 300-500ms (about the same)
- Long context (100K+ tokens): 800ms-2s (acceptable)
The 128K context window is legit. I threw our entire codebase at it (like 85K tokens, maybe more) and it analyzed the whole thing without breaking a sweat. With GPT-4 I'd have to chunk it up and lose context.
Context caching is where the magic happens. Same prompts cost 99% less on repeated calls. My bill went from $340 to $30 just by optimizing for cache hits. More on that later.
The Math That Made Me Switch (And Why You Should Too)
Cost Savings Analysis
Our actual before/after costs:
- Old OpenAI bill: $4,200/month (50M tokens)
- New DeepSeek bill: $340/month (same usage)
- With context caching: $98/month (70% cache hit rate)
What 1 million tokens gets you in real terms:
- Processing ~400 GitHub issues with full context
- Generating 50,000 lines of documented code
- Analyzing 20 full research papers
- 1,000+ complex chat conversations
The context caching is where DeepSeek becomes stupid cheap. Cached tokens cost $0.014 per million vs $0.55 standard - that's 90% off, not the 99% some blogs claim. My customer support bot went from $800/month to $45 because it reuses the same system prompts.
Heads up: DeepSeek recently suspended new account top-ups due to insane demand after V3.1 dropped. Free tier still works fine, and existing credits don't expire. But if you're planning a big migration, get started soon. I got lucky and topped up $50 right before they paused it.
The Reality Check
Here's what nobody tells you: switching APIs is usually 5 minutes of config changes and 3 hours of debugging edge cases you forgot about. With DeepSeek, it was actually just the 5 minutes.
The hardest part was finding where we buried our OpenAI config in our Docker Compose files. The actual switch was changing base_url and swapping API keys.
Read these or you'll hate yourself later:
- DeepSeek API docs - actually good, unlike most AI APIs
- Context caching guide - this is where the real money is
- DataCamp migration tutorial - covers the gotchas I hit