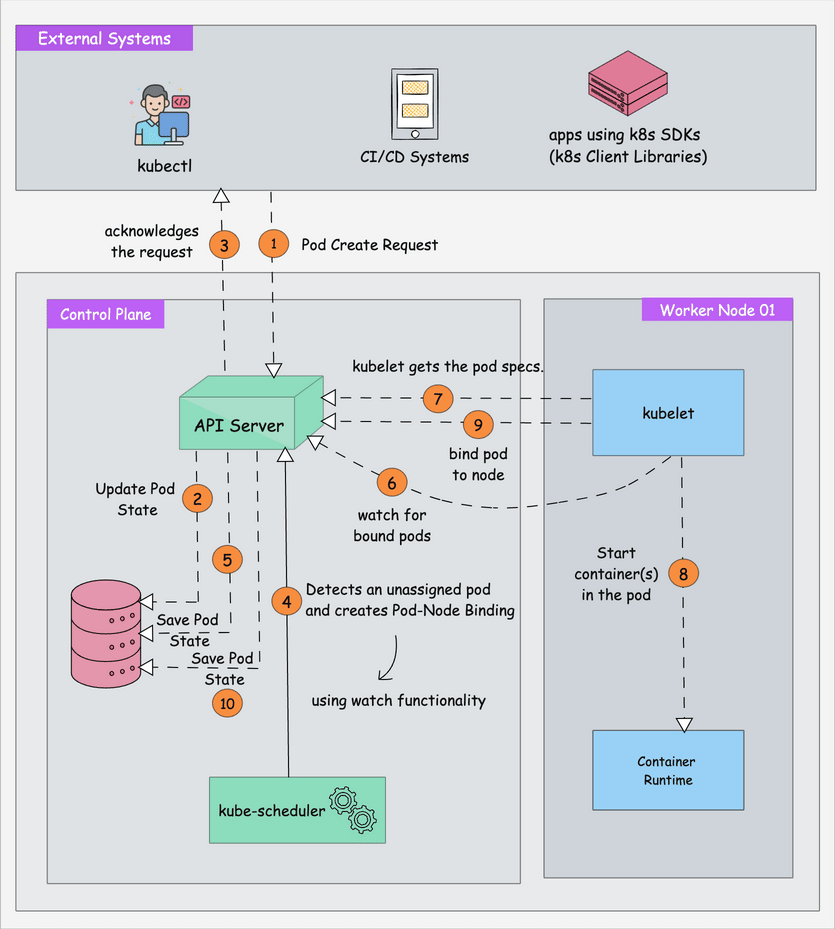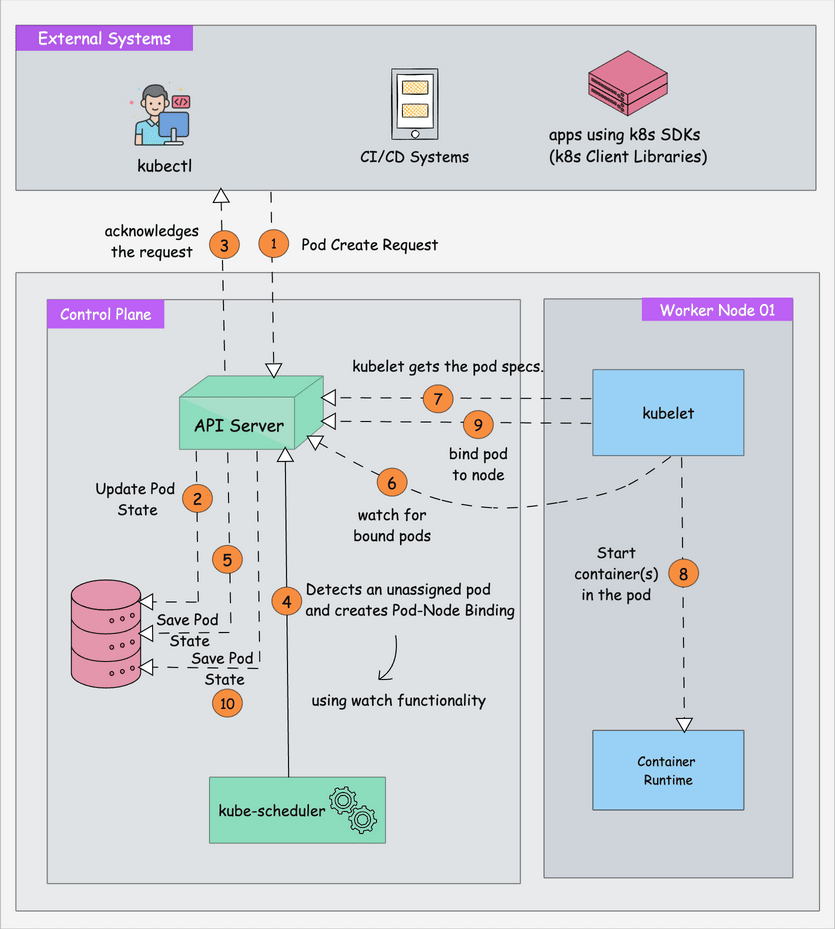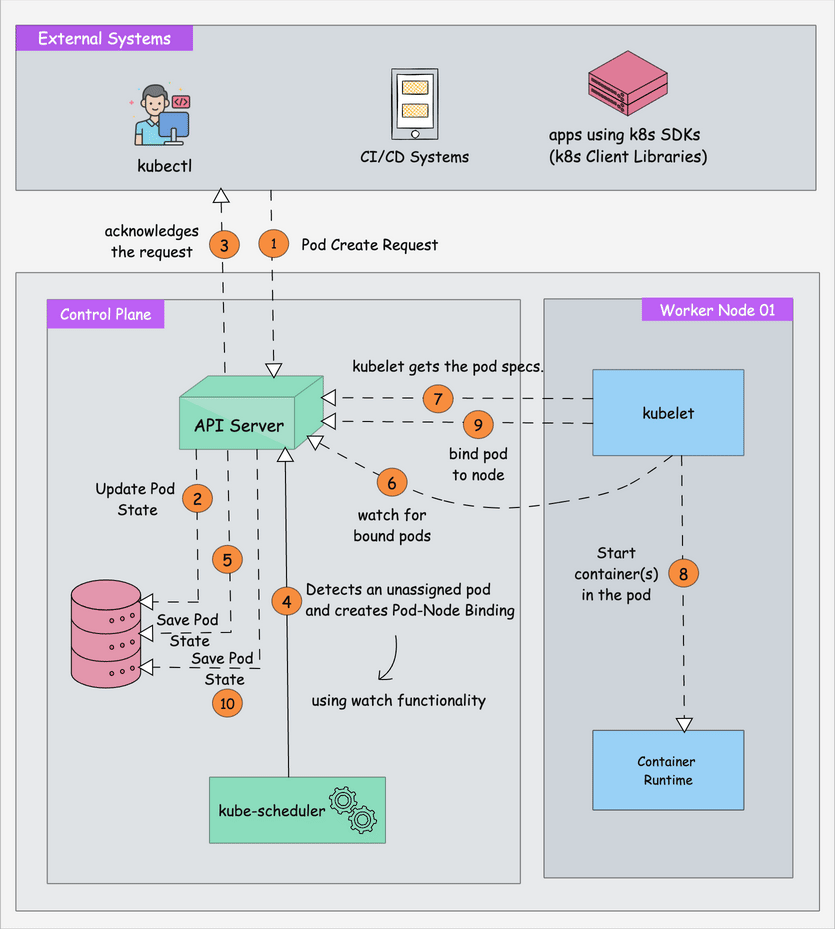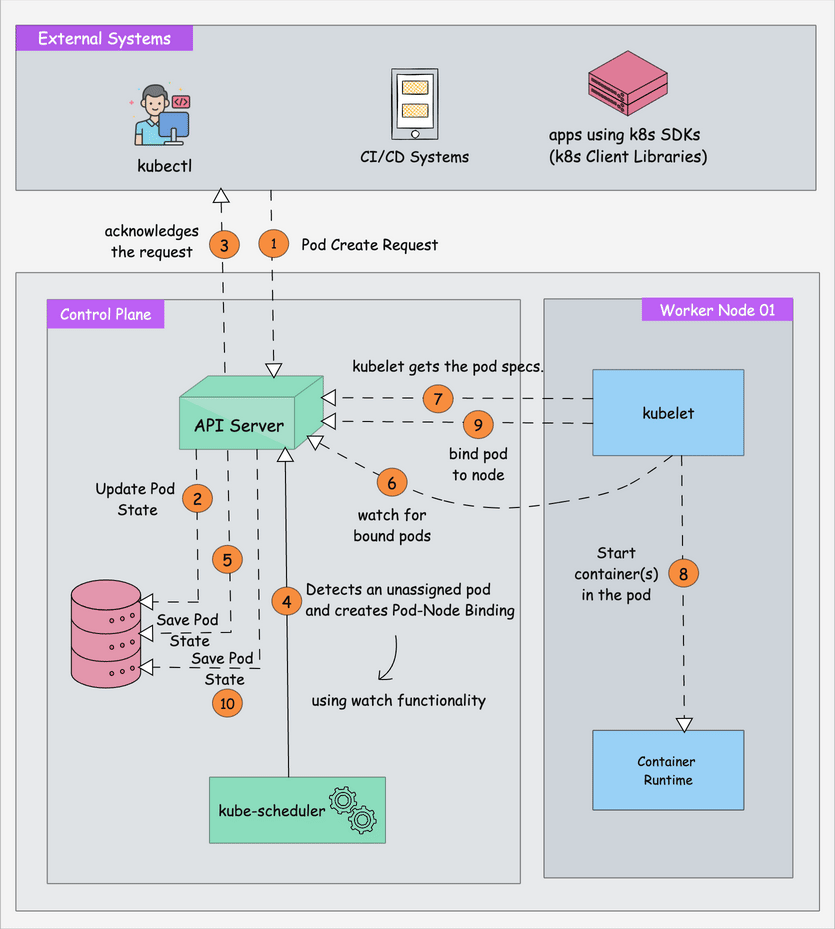
I've watched too many startups die on the Kubernetes hill. They spend 6 months setting up "production-ready" clusters, hire a $200k platform engineer, then realize their 3-person team is now spending more time debugging YAML than building their actual product.
The Kubernetes Tax: What Nobody Tells You
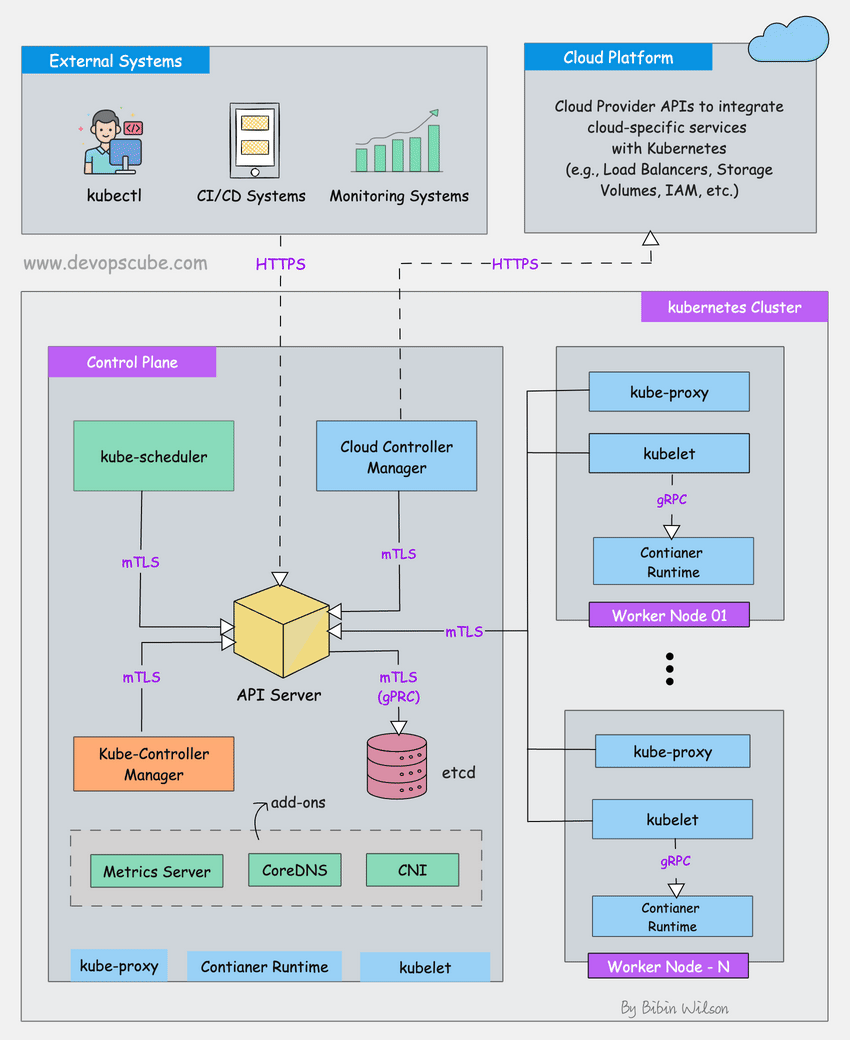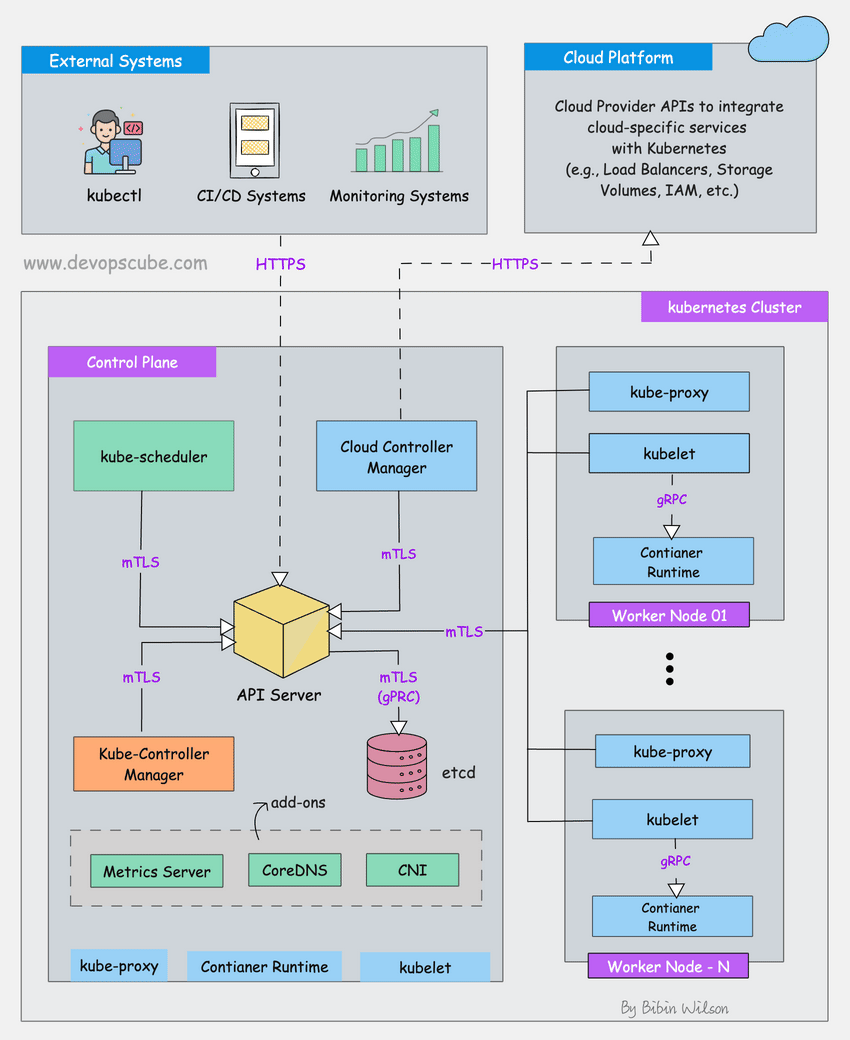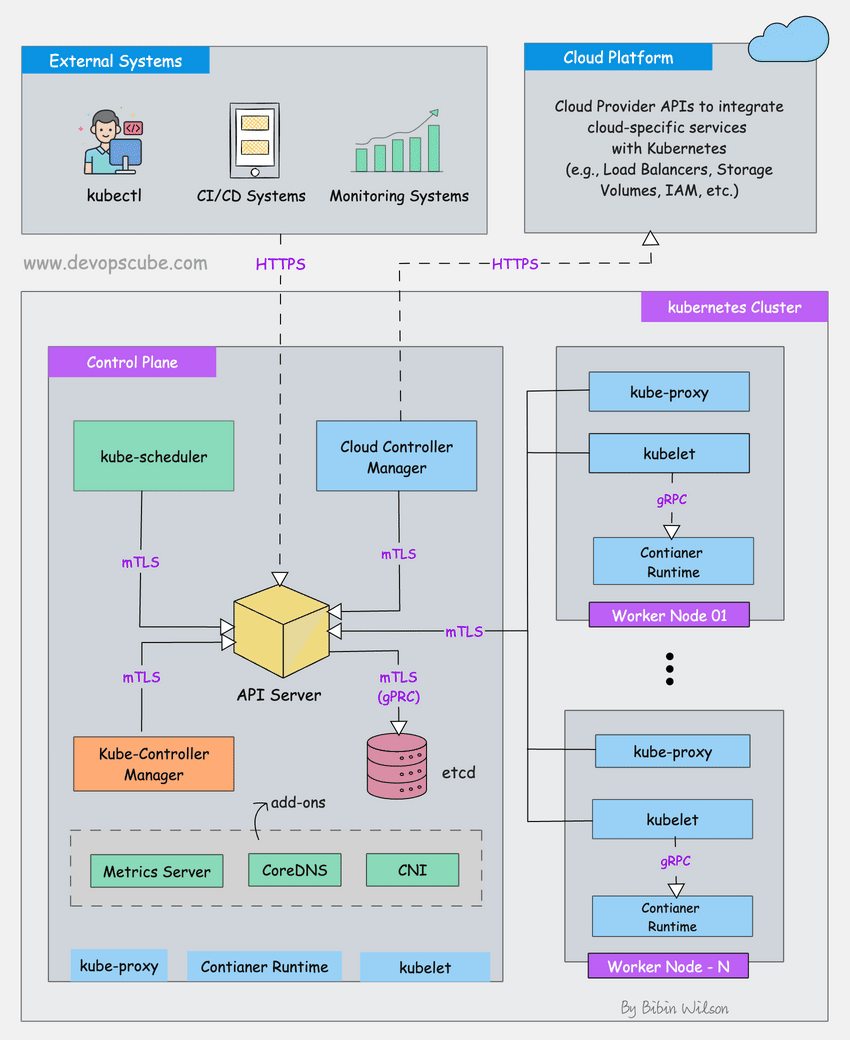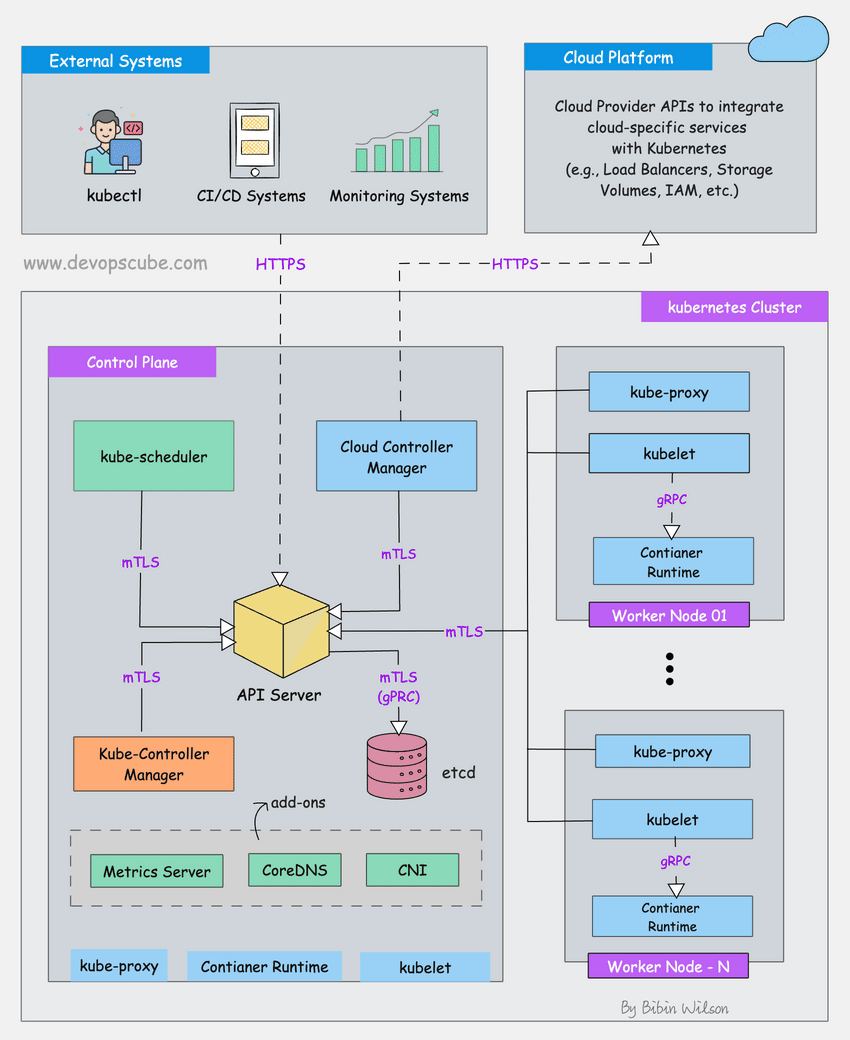
When you choose Kubernetes, you're not just choosing a container orchestrator. You're choosing to become a fucking infrastructure company.

Here's what breaks in the first month:
- Your EKS cluster control plane costs $73/month before you deploy anything (went up again in 2024)
- Persistent volumes randomly fail with
FailedAttachVolume: Multi-Attach error(K8s 1.28 still has this) - Pod networking decides to stop working and
kubectl get eventsjust saysFailedScheduling: 0/3 nodes available - Your ingress controller config has one typo and throws
Error: failed calling webhook nginx-admission - Prometheus eats 4GB of RAM monitoring your empty cluster (this is just normal btw)
The hidden costs that murder your budget:
I helped a 10-person startup audit their K8s bill last month. They were paying $3,200/month for infrastructure that could have run on a $480/month setup. That's real money that could have hired another developer.
Real costs breakdown:
- Control plane: $72/month (just to exist)
- Worker nodes: $200+/month (you need at least 2 for "high availability")
- Load balancers: $20 each (you'll end up with 5-8 somehow)
- EBS volumes: $10-50 each (they multiply like rabbits)
- Data transfer: $50-200/month (everything talks to everything)
- Monitoring: $200-500/month (Prometheus, Grafana, AlertManager)
That's $600-1000/month minimum, before you deploy anything useful.
The Pain Points Nobody Talks About
YAML Hell: I've seen senior engineers spend 3 hours debugging why a pod won't start, only to discover it was an indentation error. In production. At 2 AM. This Stack Overflow thread has 47 different YAML formatting issues that can break your deployment.
Version Nightmares: Kubernetes 1.24 removed Docker runtime support. How many teams got surprised by that? Too fucking many. Your deployment pipeline just broke and now you need to learn about containerd.
The Networking Black Hole: CNI plugins are black magic. Calico vs Flannel vs Cilium - pick wrong and spend weeks troubleshooting "why can't my pods talk to each other?"
Storage Pain: PersistentVolumes are a nightmare. StatefulSets randomly lose data, and backup/restore is an afterthought.
Security Theater: RBAC configurations are so complex that most teams either give up and use cluster-admin, or lock themselves out of their own cluster.
What Happens to Teams Who Choose K8s
Month 1: "This is amazing! We can scale anything!"
Month 3: "Why does our monitoring cost more than our application infrastructure?"
Month 6: "We need to hire a platform engineer."
Month 9: "Why are we spending more time on infrastructure than features?"
Month 12: "Maybe we should have just used Heroku."
I've seen this cycle at least 20 times. The promise of "infinite scalability" becomes "infinite complexity." Your 5-person team becomes 3 developers + 2 people fighting Kubernetes full-time.
The Breaking Point
Real story: A Series A startup came to me after their lead engineer quit. They'd spent 8 months building a "production-ready" Kubernetes platform. It had 47 microservices (for a simple SaaS product), cost $8k/month to run, and took down prod every other week.
We migrated them to Cloud Run in 2 weeks. Cost dropped to $400/month. Outages went from weekly to zero in 6 months. Their developers could actually focus on building features again.
Another one: 12-person team using EKS. Their "infrastructure sprint" was lasting 6 months and counting. They were debugging why pods couldn't reach external APIs - getting dial tcp: i/o timeout on every external call. Turned out to be a network policy nobody remembered creating that was blocking all egress traffic. Meanwhile, their competitors were shipping features every week.
The Wake-Up Call
The Kubernetes tax is real. Unless you have 50+ microservices and dedicated platform engineers who actually know what they're doing, you're probably overengineering the fuck out of your problem.
Docker Swarm works fine. AWS Fargate actually works better for most cases. DigitalOcean App Platform will get you 80% there without the headaches.
Stop choosing infrastructure based on Netflix's blog posts. Choose based on your team's actual needs and tolerance for 3 AM page alerts.