Look, Docker Swarm nodes fail. A lot. If you're reading this at 3am because your cluster just went sideways, you're not alone. I've debugged enough of these disasters to know the real story behind node failures.
The Shit That Actually Breaks
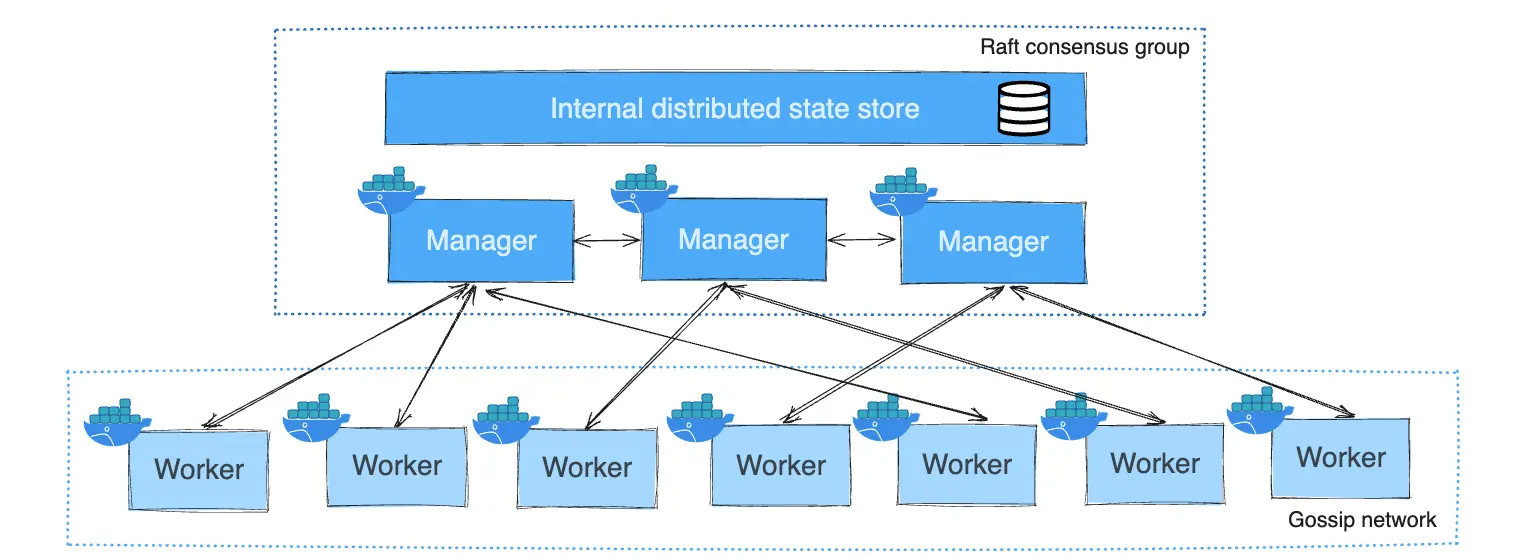
Forget the textbook reasons. Here's what really kills Docker Swarm nodes in production:
Network Bullshit (90% of Your Problems)
Docker's networking is a pain in the ass. Nodes drop out because port 2377, 7946, or 4789 gets blocked. Your firewall rules look fine, but Docker can't talk between nodes.
Last month, our entire 5-node cluster went down because someone "optimized" the iptables rules and blocked port 7946. Took 3 hours to figure out why nodes kept showing "Down" even though they were clearly running. The "optimization" was supposed to block unused ports for security compliance, but the contractor didn't understand that Docker needs those specific ports. Lost $80k in revenue during Black Friday prep because our e-commerce platform was down for 6 hours.
Memory Gets Eaten Alive
Docker daemon is a memory hog. When the host runs out of RAM, Docker starts killing containers randomly. The node doesn't crash - it just becomes useless.
I watched a production node cycle between Ready and Down for hours because it was hitting the memory limit every few minutes. cAdvisor showed 90% memory usage, but docker stats said everything was fine. Docker's memory reporting is garbage.
Certificate Expiration Hell

Docker Swarm uses TLS certificates that expire. When they do, nodes can't authenticate with the cluster. The error messages are useless - just "cluster error" or "context deadline exceeded".
We had a manager node become "Unavailable" during a weekend. Monday morning investigation showed the certificates had expired 2 days earlier. No alerts, no warnings - just silent failure. The logs showed "x509: certificate has expired" buried in thousands of lines of debug output. Spent the entire Monday morning restoring quorum because the expired cert cascaded into a split-brain scenario where the remaining 2 managers couldn't agree on cluster state.
The Cascade Effect
When one node fails, everything else starts breaking:
Quorum Death Spiral
Lose too many managers and your cluster locks up. Can't deploy, can't scale, can't update services. Just sits there being useless while your services die.
Service Rescheduling Chaos
Docker tries to be smart about rescheduling containers from failed nodes. Sometimes it works. Sometimes it reschedules everything to the same node and kills it too.
Node States That Actually Matter
Docker has fancy state names, but here's what they really mean:
- Active: Manager is working (for now)
- Reachable: Manager exists but isn't the leader
- Unavailable: Manager is fucked, can't participate in cluster decisions
- Down: Node is completely dead or unreachable
- Ready: Worker node is accepting tasks
- Drain: Node is being evacuated (usually because you're about to kill it)
Real Prevention (Not Corporate Bullshit)
Monitor the Right Things
- Set up alerts for node state changes, not just CPU/memory
- Watch Docker daemon logs:
journalctl -u docker -f - Monitor certificate expiration dates
- Track disk space - Docker logs can fill your disk
Resource Planning That Works
- Give nodes enough RAM for Docker daemon overhead (2GB minimum)
- Use odd numbers of managers - 3 or 5, never 2 or 4
- Don't run managers on the same physical hardware
- Test your backup procedures before you need them
Network Configuration Reality Check
- Open the required ports: 2377/tcp, 7946/tcp+udp, 4789/udp
- Test connectivity between all nodes:
telnet <node-ip> 2377 - Document your network topology because you'll forget when it's broken
- Use Weave Net or Flannel if Docker's networking keeps failing
The bottom line: Docker Swarm fails in predictable ways. Learn the patterns, monitor the right metrics, and have a recovery plan that actually works. Most importantly, test your disaster recovery when things are working, not when everything's on fire.



